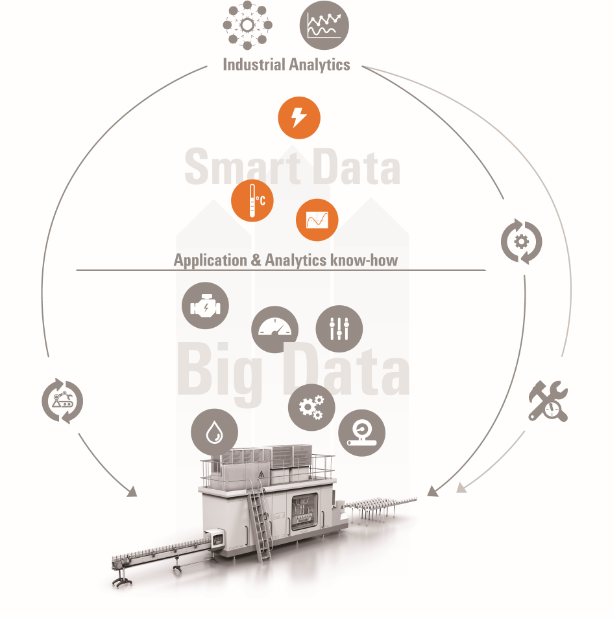
机器和生产工厂不断产生数据。将这些数据成功转化为创新的公司获得了决定性的竞争优势。借助易於使用的软体,魏德米勒公司正在使人工智慧方法应用於机器生产商和生产型公司。
 |
| 魏德米勒公司正在使人工智慧方法应用於机器生产商和生产型公司。 |
为了分析机器数据和流程数据,工业分析使用了能够检测异常情况甚至能够预测未来机器行为的复杂模型。通过使用人工智慧(AI)方法和机器学习(ML),用源自原始数据的特徵来揭示以前未知的测量值之间的关系。
需要具备综合专门知识
几??在所有公司都能获得必要讯息。在开发有意义的分析模型时,尤其是中型公司通常还要依赖外部数据科学家的支持。魏德米勒公司开发了一个突破性的解决方案,使中型公司不再需要数据科学家。在与最终用户密切合作的过程中,数据专家识别测量值中的相关性并训练初始模型。初始模型应用成功後,反复向初始模型输入新数据,并在机器的整个生命周期中进一步开发模型。随着时间的推移,这将提高讯息质量。
学习机器学习
许多机器生产商和生产型公司还不能独立使用现有的机器学习工具,因为这些工具的操作已经针对分析专家的数据驱动活动进行了优化。公司可以用巨额资金培训现有员工,也可以自己雇用一名数据科学家。这就产生了一个抑制??值,放慢了人工智慧在工业中的应用速度。
另一个方法是开发易於使用的软体解决方案,即使用户没有经过任何统计培训也能够理解并生成分析模型。魏德米勒公司的工业分析业务部门已经通过自动化机器学习软体将这一想法付诸实践。该款应用程序的名称意味着模型大部分是自动开发的。
「类似的应用程序目前在金融技术、银行业和营销领域得到广泛使用。但是,现有的解决方案不适用於机器和工厂,因为它们不支持自动化行业的相关数据类型。这些解决方案总是需要一个理想的数据库,」工业分析业务部门产品经理Carlos Paiz Gatica博士解释道。「此外,这些解决方案不能整合用户的领域知识,而这对於工业应用程序至关重要。」
对於自动化机器学习软体,魏德米勒公司的分析专家将领域专家的数据讯息与算法相结合,自动生成合适的模型。以下步骤描述了模型生成过程(以异常检测为例):
1.选择训练数据
领域专家决定应该使用哪些数据集来学习机器或工厂的正常行为。为此,首先生成原始数据概述,用来支持用户评估数据的讯息内容。测量值的准备过程完全自动进行。
2.特徵工程
如果原始数据不够,可以在原始数据的基础上生成附加讯息。用户可以使用其领域知识来创建新特徵。例如,这些特徵可以描述温度变化的过程,而不仅显示个别状况。使用这些特徵比使用原始数据通常能够对机器状况进行更好的评估。
3.标记机器行为
用户用标签标记数据中存在的正常行为区域(绿色)或不希??发生的行为区域(红色)。这样能够使用户用其领域知识增加训练数据的讯息内容。辅助系统通过直接突出显示数据集中的类似情况,支持标记过程。
4.模型训练
标记过的数据集被转换成模型,并用各种机器学习方法进行训练。这个全自动化的过程产生了一个替代模型列表,该列表可以提供与结果质量、执行时间和训练持续时间相关的讯息。《异常分数图》(Anomaly Score Plot)直接显示模型的结果,专家可以直接比较模型性能。如果未能实现所需的模型性能,用户可以再次编辑模型的特徵和标签。然後,可以将模型直接转移到目标系统的架构中。
扩展人工智慧应用程序
Paiz说过:「有了自动化机器学习软体,机器生产商和生产型企业不必成为数据专家,就可以独立开发人工智慧和机器学习并从中获益。通用的应用程序支持用户生成初始模型并进一步开发模型。这样,公司不再依赖数据科学家,也不必与外部合作夥伴分享其工艺流程和机器知识。」