许多Google产品(像是Google Assistant、Google搜寻、Google地图等)都内建了高品质的Text-to-Speech服务,可以产生如人声般自然的发音。我们收到许多开发者的意见,表示希??能将Text-to-Speech的服务结合到他们的应用程式中,所以Google特别将这项Cloud Text-to-Speech技术加入Google云端平台(Google Cloud Platform, GCP)中。
 |
| /news/2018/04/02/1046234300S.jpg |
使用者可以将Cloud Text-to-Speech服务运用在不同的情境中,如为电话语音服务(Interactive Voice Response, IVR)中心提供语音回应系统,并启用即时自然语言对话功能,另外,此服务可与物联网设备,如电视、汽车、机器人等进行对话。将文字格式的媒体内容(如新闻文章、书籍)转为囗语形式(如Podcast、有声书)。
Cloud Text-to-Speech服务提供了12种不同语言中的32种不同声音供使用者选择。即使是复杂的文字内容,例如姓名、日期、时间、地址等,Cloud Text-to-Speech服务也可以立刻发出准确且道地的发音,并支援多种音档格式,包含MP3和WAV等,不仅如此,使用者还可以自己调整音调、语速和音量。
Cloud Text-to-Speech服务更以DeepMind所建构的原始音档生成模型WaveNet为基础,透过运用WaveNet将一系列高保真度的声音转化为语音。整体而言,WaveNet可以合成并产出更自然的语音细节,而且相较於其他Text-to-Speech技术所产生的语音内容,WaveNet所产出的语音内容也更受使用者喜爱。
在2016年底,DeepMind推出了第一版的WaveNet,透过神经网路架构来训练大量的语音样本并创造原始音频的波形。在训练过程中,神经网路会撷取语音的基本架构,像是语调的连接和语音波形的形状等。当输入特定的文字内容时,经过训练的WaveNet模型会产生相对应的语音波形,藉由一次产生一个样本的方式,达到比其他方法更高的准确度。
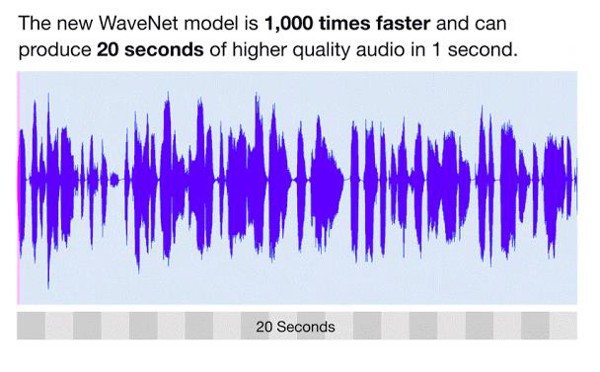
现在,我们使用的运行於Google云端TPU基础架构上的更新版WaveNet。全新且升级的WaveNet模型所生成的原始音频波形比原本的模型快了1,000倍,而且只需50毫秒即可生成一秒钟的语音讯息。事实上,这个新模型不仅更快速而且具有高保真度,且每秒能创造出24,000个音频波形的样本。为了制作出更好、更拟真的音质,我们也将每个样本的解析度从8位元提高到16位元。
如图所示,新的WaveNet模型可以制作出更自然的语音讯息。在测试过程中,使用者在1到5级的平均意见分数(Mean-opinion-score, MOS)量表中,给予新版美式英文WaveNet语音4.1的高分,其中有超过20%的人认为比标准的人声更好,而超过70%的人肯定它能降低人类语言的隔阂。由於WaveNet音讯仅需较少录制音频,就能制作出高音质模型,因此我们预计在未来几个月内,将持续改善WaveNet音讯的多样性与品质,并提供给云端客户使用。
Cloud Text-to-Speech已经协助很多我们的客户,像是思科(Cisco)和Dolphin ONE,提供更好的终端使用者体验。
「身为提供协作解决方案的领导者,思科长久以来致力於为企业提供最新的技术。Google的Cloud Text-to-Speech服务协助我们提供给客户他们所期待的自然人声。」━思科认知协作技术长 Tim Tuttle
Dolphin ONE Jason Berryman指出:「Calll by Dolphin ONE的电信平台在几??全球各地都能提供使用者多重设备的连接服务。我们将Cloud Text-to-Speech工具与我们的产品结合,为顾客能体验到最自然的语音客服。透过使用Google Cloud的机器学习工具,我们能即时将最新科技提供给我们的使用者。」