今天發布的一篇研究論文描述了生成式人工智慧如何幫助最複雜的工程工作之一:設計半導體。
 |
| 設計師利用生成式人工智慧作為晶片輔助 |
這項工作展示了在高度專業化領域的公司如何利用內部資料訓練大型語言模型(LLMs),以建立提高生產力的助手。
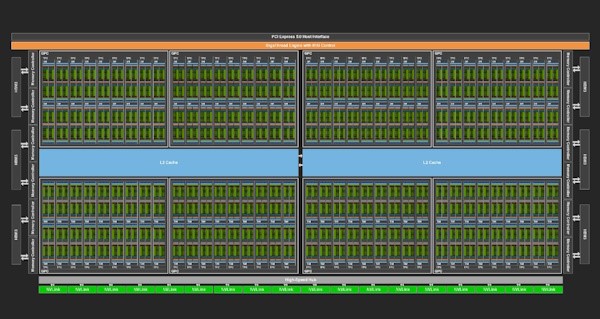
半導體設計是一項極具挑戰性的工作。在顯微鏡下,像NVIDIA H100 Tensor Core GPU(上圖)這樣最先進的晶片看起來就像一座精心規劃的大都市,由數百億個電晶體構建而成,連接在比人類頭髮細10,000 倍的街道上。
多個工程團隊花費長達兩年的時間進行協作,以建造其中一個這樣的數位化巨型城市。
有些小組定義晶片的整體架構,有些小組製作並放置各種超小型電路,有些小組測試他們的工作。 每項工作都需要專門的方法、軟體程式和電腦語言。
對於大型語言模型的廣泛願景
NVIDIA 研究總監暨該論文主要作者 Mark Ren 表示:「我相信隨著時間的推移,大型語言模型將全面幫助所有流程。」
NVIDIA 首席科學家 Bill Dally 今天在國際電腦輔助設計會議(International Conference on Computer-Aided Design)上的主題演講中宣布了這篇論文。「這項努力代表著將大型語言模型應用於複雜的半導體設計工作中邁出了重要的第一步」,Dally在舊金山舉行的活動中表示:「它展示了即使是高度專業化的領域,也可以利用其內部資料來訓練有用的生成人工智慧模型。」
ChipNeMo浮出水面
這篇論文詳細介紹了NVIDIA工程師們如何為內部使用創建了一個名為ChipNeMo的客製化大型語言模型,該模型是使用公司內部資料進行訓練,以生成和優化軟體,並協助人類設計師。
長期以來,工程師們希望將生成式人工智慧應用於晶片設計的每個階段,這有可能顯著提高總體生產力,在EDA領域已經有超過20年經驗的Ren表示。
在對NVIDIA工程師進行可能的用例調查後,研究團隊選擇了三個項目:一個聊天機器人、一個程式碼生成器和一個分析工具。
初始用例
後者(分析工具),用於自動化耗時的任務,即維護已知錯誤的最新描述,目前為止受到了最多的好評。
一個回答有關 GPU 架構和設計問題的原型聊天機器人,可幫助許多工程師在早期測試中快速找到技術文件。
正在開發的程式碼產生器(如上方演示)已經透過晶片設計人員使用的兩種專用語言,創建大約 10-20 行軟體的片段。它將與現有工具整合,因此工程師們將有一個方便快捷的輔助工具用於進行中的設計。
使用 NVIDIA NeMo 自訂人工智慧模型
該論文主要專注於團隊收集設計資料並使用其創建專門的生成式人工智慧模型的工作,這是一個可複製到任何產業的流程。
作為起點,團隊選擇一個基礎模型並用NVIDIA NeMo來客製化這個模型,NVIDIA NeMo是一個用於建置、自訂和部署生成式人工智慧模型的框架,它包含在NVIDIA AI Enterprise軟體平台中。 所選的 NeMo 模型擁有 430 億個參數,這是衡量其理解模式能力的指標。它使用超過一兆個權杖(token)進行了訓練,這些權杖代表文本和軟體中的單詞和符號。
隨後,團隊對模型進行了兩輪訓練,第一輪使用了約240億個權杖的內部設計數資料,第二輪使用了約13萬次對話和設計示例的混合資料。
這項工作是半導體產業中生成式人工智慧的研究和概念證明的數個示例之一,這些示例正在逐漸從實驗室中嶄露頭角。
分享所學經驗
Ren分享他和團隊學到其中一個很重要的經驗,即是客製化大型語言模型的價值。
在晶片設計任務中,具有少至 130 億個參數的客製化 ChipNeMo 模型的效能,甚至可與具有超過 700 億個參數的 LLaMA2 等更大的通用型大型語言模型的效能相媲美或超過。在某些用例中,ChipNeMo 模型要好得多。
在這個過程中,使用者需要謹慎地選擇他們收集的資料,以及如何清洗這些資料以供訓練使用,他補充說。
最後,Ren建議使用者要時刻關注可以加速和簡化工作的最新工具。
NVIDIA研究部門擁有全球數百名科學家和工程師,致力於人工智慧、電腦圖形、電腦視覺、自駕車和機器人等領域的研究。半導體領域的其他最新項目包括使用人工智慧設計更小、更快的電路,以及優化大型區塊的布局。
希望建立自己的客製化大型語言模型的企業現在就可以開始使用 GitHub 和 NVIDIA NGC 目錄中提供的 NeMo 框架。