嵌入式處理器的核心能夠在單一週期內處理多重的運作,其中包括了計算、資料取得、資料儲存、以及指標的增量與減量。除此之外,處理器核心還會藉由將資料從暫存檔移入移出來對內外部記憶體空間之資料傳輸進行協調。
以上所述,聽起來都很不錯,但是在現實狀況中,假如資料可以搬移而又不會一直對執行傳輸的核心產生干擾時,這樣才能夠在該應用領域中夠達到最佳化的效能。而這就是直接記憶體存取(DMA)能夠發揮作用的地方。處理器需要DMA的能力,以便使核心能夠從內外部記憶體與周邊之間,或是記憶體空間之間(記憶體DMA,或是”MemDMA )的資料傳輸作業中被解放出來。
DMA控制器有兩種主要的類型。「週期盜取(Cycle-stealing)」DMA會利用多餘的(空閒,idle)核心週期來執行資料的傳輸。對於處理負擔很沈重的系統而言,例如多媒體流(multimedia flows),這不是一個可行的解決方案。相對的,使用DMA控制器在核心之外獨立運作會來得更加有效率。
這點為何如此重要?我們可以設想一種情況,假如處理器的視訊埠具有先進先出(FIFO)功能,在每次有資料樣本可以取得時就必須被讀取。在這個狀況下,核心將會在每一秒鐘內被中斷上千萬次。還不光只有這些中斷而已,核心還必須對目標記憶體執行等量的寫入程序。對於在這項任務上的每個核心處理週期來說,在處理程序的迴路中將會有對等的週期因而損失掉。
就如同理論上所聽過的DMA一樣,以PC為基礎的軟體設計工程師在轉移到嵌入式領域的過程中,對於在應用裝置上的資料搬移必須仰賴DMA控制器是頗感遲疑的。之所以會有這樣的不情願,通常是源自於一種既定印象─將DMA納入設計中會增加潛在的編程模型複雜度─所造成。然而我們的目的就是要讓各位放鬆心情,告訴各位DMA為何能夠真正的幫上忙。在這一系列的文章中,我們將會把焦點放在DMA控制器上面,接著告訴各位如何以DMA來將效能最佳化,最後對於DMA控制器作為整體架構之一部分時,要如何最適當的加以管理提出一些想法。
讓我們稍微離題一下,先來討論記憶體空間(memory space)這個術語。嵌入式處理器具有階層式記憶體架構(hierarchical memory architecture ),能夠致力於對數個層級的記憶體,利用不同的大小與效能等級來加以平衡。最接近核心處理器的記憶體(稱為Level 1,或是L1記憶體),是以核心時脈的全速來運作的。以「最接近」來形容並不誇張,因為在矽晶片中,L1記憶體在實體上確實是很貼近核心處理器,這樣才能獲得最快的存取和運作速度。L1記憶體最常被劃分為指令區塊以及資料區塊,以便有效的利用記憶體匯流排之頻寬。
當然,L1記憶體的大小也必須有所限制。對於需要較大編碼大小的系統而言,額外的內建與外接記憶體都是可以利用的─當然也會增加延遲。較大的內建記憶體被稱為Level 2(L2)記憶體,而外接記憶體我們則稱之為Level 3(L3)記憶體。L1記憶體的大小通常都有數十個kBytes,L2內建記憶體則是以數百個kByte來計算,至於L3記憶體則往往都是以megabyte計算。
現在回到我們原本的討論主題上。DMA控制器是一個獨特的周邊,專門用來在系統中搬移資料。試想一個控制器,藉由一組專用的匯流排使內部和外部記憶體與具有DMA功能的周邊相互連結。就意義上而言,它是一組處理器能對其加以編程,以便執行傳輸的周邊。使記憶體與選定之周邊相互接合為其獨特之處。很明顯的,只有資料流動十分明顯(每秒kBytes或是更大)的周邊才需要具備有DMA功能。最佳的範例就像是視訊、音訊以及網路介面等。頻寬較低的周邊也可以具備有DMA功能,這將可以使核心減少一些介入上的負擔,並且對這些介面上的資料傳輸給予協助。
通常,DMA控制器會包含有位址匯流排(address bus)、資料匯流排(data bus)、以及控制暫存器(control registers)。有效率的DMA控制器會具備有能夠自行對任何所需資源提出存取要求的能力,而不需要處理器本身的介入。它必須要有產生中斷的能力。最後,它必須要能夠在控制器內部計算位址。
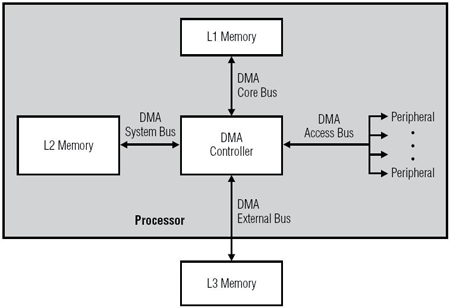
在一個處理器當中可能包含了多個DMA控制器。每個控制器都具有多重DMA通道以及多重匯流排,用以直接和記憶體插槽與周邊做連結,如(圖一)中所示。在許多的高效能處理器中會擁有兩大類型的DMA控制器。第一種類型通常稱為系統DMA控制器(System DMA Controller),可以存取所有的資源(周邊以及記憶體)。這類型控制器之週期數(cycle count)是以高達133 MHz頻率(以ADI的Blackfin處理器為例)之系統時脈(SCLKs)來加以計算的。第二種類型稱為內部記憶體DMA控制器(IMDMA),是專門為了在內部記憶體之間進行存取之用。由於存取動作都在內部(L1到L1,L1到L2,或是L2到L2)進行,所以週期數是以可以超越600 MHz速率之核心時脈(CCLKs)來加以計算的。
每個DMA控制器都有一組FIFOs,可以在DMA子系統與周邊或是記憶體之間做為緩衝之用。對於MemDMA而言,在轉換時的來源端與目的端都存在有FIFO。當資源處於忙碌狀態,以致於轉換無法完成時,FIFO能藉由提供可以存放資料之位置來改善效能。
由於多數人都會在編碼初始化階段就對DMA控制器做設定,因此核心應該只需要在整組資料的轉換完成之後才對中斷予以回應。當核心還在執行其基本的處理任務時─這才應該是真正需要投注焦點的工作─就應該對DMA控制器加以編程,使其能夠與核心平行式的搬移資料。
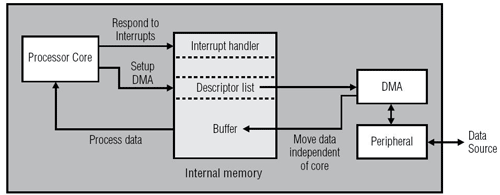
在經過最佳化的應用裝置上,核心絕對不用去處理任何搬移資料的工作,除了在L1記憶體上的存取。核心並不需要等待資料送達,因為在核心要存取這些資料之前,DMA引擎早就已經將其準備好了。(圖二)中所示為在處理器與DMA控制器之間的典型互動關係。當中斷產生時,分配到處理器的步驟都是有關於傳輸的設定、中斷的啟動、以及程式碼的執行等。而回返至處理器上的中斷輸入可以用來發出資料已經準備接受處理的信號。
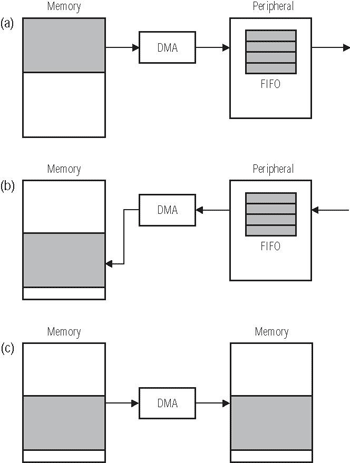
資料除了在各個周邊來回搬移之外,也需要在各個記憶體空間來回的搬移。舉例來說,視訊源可能會從視訊埠直接流向L3記憶體,這是因為工作的緩衝區大小太大,以致於無法存放於內部記憶體中。我們不希望在每次需要執行運算作業時,處理器都還要從外部記憶體去取得像素,因此記憶體對記憶體(memory-to-memory)DMA(MemDMA)可以用更有效率的存取時間將像素送至L1或L2記憶體當中。(圖三)所示為一些典型的DMA資料流。
到目前為止我們都是著眼於資料的搬移,但是DMA傳輸並不一定都會牽涉到資料。我們可以使用code overlays,設定DMA控制器將程式碼在未執行之前搬移至L1指令記憶體當中,藉此來改善效能。程式碼通常會存放於較大的外部記憶體當中,並且在有需要時才會被選擇性的載入L1記憶體。
對DMA控制器加以編程
現在讓我們來看看,在指定DMA的動作時有什麼選項可以使用。我們將會從最簡單的模型開始,然後建立起較具彈性化的模型,並且依序增加設定上之複雜度。
對於任何型態的DMA傳輸來說,我們總是需要為資料指定啟始來源以及目標位址。在周邊DMA的情況中,該周邊的FIFO若不是擔任來源就是擔任目標。當該周邊擔任來源時,記憶體所在位置(內部或外部)就擔任目標位址。當周邊擔任目標時,記憶體所在位置(內部或外部)就擔任來源位址。
在最簡單的MemDMA的情況中,我們必須要將來源位址、目標位址以及欲傳輸字串的數量告知DMA控制器。使用周邊DMA時,只需要指定來源或是目標,視傳輸的方向而定。每次傳輸的字串大小可以是8、16、或32位元任一組。這種類型的處理代表了具有一致性「 步幅」(stride)的簡單一維(1D)轉換。DMA控制器作身為這種轉換中的一部份,會隨時注意來源與目標位址的增加量。藉由一致性的步幅,8位元傳輸的位址增加量為1位元組,16位元傳輸的增加量為2位元組,32位元的增加量為4位元組。由以上的參數可以設定出基本的1D DMA傳輸,如(圖四)中所示。
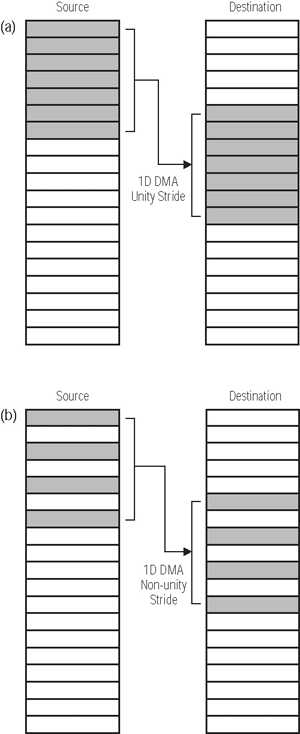
| 《圖四 1D DMA的範例:(a)具有一致性的步幅,(b)具有非一致性的步幅》 |
|
\雖然1D DMA的能力已經受到廣泛的使用,但是二維(2D)的能力其實是更具利用價值的,特別是在視訊應用領域方面。2D的特點就是我們所討論1D DMA之特點的直接延伸。除了XCOUNT與XMODIFY值之外,我們也可以對相關的YCOUNT以及YMODIFY值進行編程。最簡單的方法就是把2D DMA想像成一個巢狀迴路,內部迴路是藉由XCOUNT與XMODIFY來加以指定,而外部迴路則是以YCOUNT以及YMODIFY加以指定。因此1D DMA就可以只當作是如下形式的2D傳輸中之「內部迴路」:
for y = 1 to YCOUNT /* 2D with outer loop */
for x = 1 to XCOUNT /* 1D inner loop */
{
/* Transfer loop body goes here */
}
XMODIFY會決定每當XCOUNT減量時,DMA控制器所採用的步幅值,而YMODIFY則會決定每當YCOUNT減量時所要採用的步幅值。就如同XCOUNT與XMODIFY的情況一樣,YCOUNT會以傳輸的數量來加以指定,而YMODIFY則是以位元組的數量來指定。很明顯的,YMODIFY可以是負數,以便使DMA控制器能夠在緩衝區啟始位置的周邊繞返。我們將會對這個特點做一簡短的探討。
對於周邊DMA來說,傳輸的「 記憶體端」不是1D就是2D。然而,在周邊端永遠都會是1D傳輸。唯一的限制就是DMA的每一端(來源與目標),其被傳輸的位元組總數必須要相同。舉例來說,假如我們要從三個10位元組的緩衝區將資料傳給一組周邊,該周邊就必須使用任何有被支援的傳輸寬度以及可取得的傳輸計數值所可能產生的組合,將其傳輸設定為30個位元組。
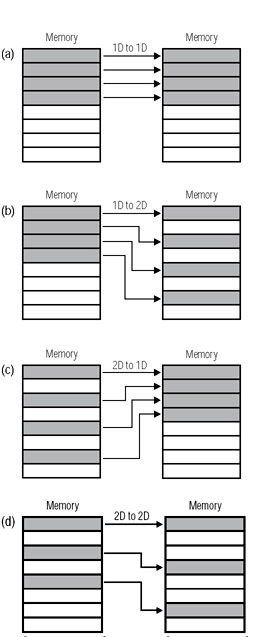
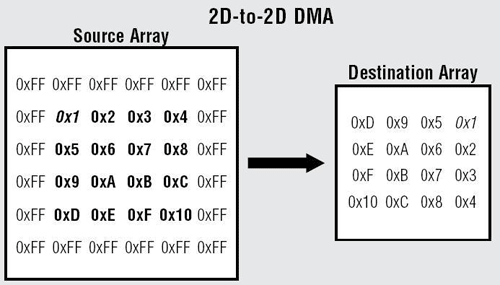
MemDMA提供了多一點的彈性。舉例來說,我們可以設定1D對1D傳輸,1D對2D傳輸,2D對1D傳輸,當然還有2D對2D傳輸,如(圖五)所示。唯一的限制就是DMA傳輸區塊的每一端,其被傳輸的位元組總數必須要相同。
現在我們來看看一些DMA設定的範例:
範例 1
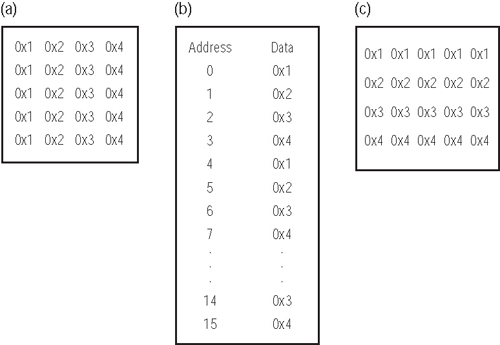
假設有一組 4像素(每列)× 5列的陣列,具有位元組大小(byte-sized)的像素值,安排如(圖6a)所示。
然這些資料是以矩陣方式顯現,但是就像圖6b中所示,這些資料是連串出現在記憶體中的。
現在我們想要利用DMA控制器建立如(圖六c)中所示的陣列。
在這個傳輸中的來源與目標DMA暫存器之設定如下:
來源 |
目標 |
XCOUNT=5 |
XCOUNT=20 |
XMODIFY=4 |
XMODIFY=1 |
YCOUNT=4 |
YCOUNT=0 |
YMODIFY=-15 |
YMODIFY=0 |
來源與目標字串的傳輸大小為每次傳輸1位元組。 |
讓我們來完成這個處理程序。在這個範例中,我們可以使用MemDMA並且採用2D對1D傳輸設定。由於來源是2D,所以顯然來源通道的XCOUNT與YCOUNT值分別為5與4,因為陣列大小就是4像素/列 × 5列。因為我們將會使用1D傳輸來將目標緩衝區填滿,所以我們只需要將目標端的XCOUNT與XMODIFY加以編程即可。在這個情況下,XCOUNT的值設為20,因為這就是將要被進行傳輸的位元組數目。目標端的YCOUNT值就是0,而YMODIFY也是0。可以看到計數值將會遵循我們稍早所討論過的規則(例如4 × 5 = 20位元組)。
現在讓我們來談談用於來源緩衝區上之XMODIFY與YMODIFY的正確值。我們希望取得第一個值(0 × 1),並且跳過4個位元組到下一個0 × 1的值。此步驟將會重複五次(來源XCOUNT = 5)。來源XMODIFY的值是4,因為該數值就是控制器為了取得下一個像素(包括第一個像素)所跳過的位元組數目。XCOUNT值會在每次蒐集到一個像素時減1。當DMA控制器達到第一列的終點時,XCOUNT值會降到0,同時YCOUNT則會減1。接著在來源端上的YMODIFY值需要將位址指標(address pointer)帶回到陣列中的第二元素上(0 × 2)。當此發生的瞬間,位址指標還仍然是指在第一列(0 × 1)的最後一個元素上。在陣列中由該點往回數至第一列的第二個像素,總共會通過15個元素。因此來源YMODIFY為 -15。
假如核心在完成這個傳輸時沒有藉助DMA控制器的協助,那麼它將會為了對每個像素進行讀取與寫入而消耗掉極可貴的週期。此外,核心還需要注意來源與目標端的位址,以及對每個傳輸的步幅值進行追蹤。
以下是一個更為複雜,關於2D對2D傳輸的範例:
範例2
假設我們現在從具有0xFF值之邊界的陣列開始,如(圖七)中所示。
我們希望只將來源矩陣(以粗筆畫顯示)的內部方塊保留下來,但是也希望能夠將矩陣旋轉90度,如(圖七)中所示。
以下的暫存器設定會將這個範例中的傳輸產生出來,而我們也會解釋其原因。
來源??????????????? |
目標 |
XCOUNT =4? |
XCOUNT =4 |
XMODIFY = 1 |
XMODIFY = 4 |
YCOUNT = 4 |
YCOUNT = 4 |
YMODIFY= 3 |
YMODIFY= -13 |
首先,我們必須要決定如何在來源陣列中存取資料。當DMA控制器從來源陣列中讀取每個位元組的同時,目標端也將會以每次一個位元組的方式建立起輸出陣列。
我們要如何開始呢?讓我們先看看我們想要搬移至輸入陣列中的第一個位元組。此處以斜體字表示為(0 × 1)。這對於我們在選擇來源緩衝區的啟始位址時,將會很有幫助。接著我們希望在跳過”邊界”位元組之前能夠連續讀取接下來的三個位元組。在這個範例中,傳輸的大小是被假設為 1位元組。
由於控制器會在跳過某些位元組而移動至陣列中的下一列之前,先讀取同一列中的四個位元組,所以來源XCOUNT值為 4。因為控制器會在其蒐集到0 × 2、0 × 3、以及0 × 4的同時將位址加 1,因此XMODIFY值為 1。當控制器完成了第一列之後,來源YCOUNT值會減 1。因為我們有四列要傳輸,所以來源YCOUNT值為 4。最後,來源YMODIFY值為 3,這是因為就如同先前我們所討論過的,當XCOUNT由 1變成 0之後,位址指標不會以XMODIFY值增加。設定YMODIFY值為3可以確保下次所要取得的是0 × 5。
在傳輸的目標端,我們將要再次的把0 × 1位元組之位置加以編程,作為初始的目標位址。因為從來源位址所取得的第二個位元組是0 × 2,所以控制器接著必須要將這個值寫入到目標位址。如同圖7中所示的目標陣列,其中的目標位址必須先增加 4,而這個值也正是用來定義目標XMODIFY的值。由於目標陣列的大小為4 × 4,因此目標XCOUNT以及YCOUNT的值也都是4。唯一剩下的值就是目標YMODIFY。要算出這個值,我們必須要先算出有多少目標位址的位元組被從搬回至陣列中。當目標YCOUNT經過第一次減量之後,目標位址會指向0 × 4的值。最後所計算出的目標YMODIFY值為 –13,其可以確保0 × 5的值被寫入至目標緩衝區的所指定位置。
在下一篇文章中,我們將會更深入探討DMA,討論兩大主要傳輸分類:以暫存器為基礎(Register-based)與以敘述元為基礎(Descriptor-based),以及何時該使用何種形式。
文章後之資料:::
屬性(人物):::
屬性(產業類別):::RED
屬性(關鍵字):::DMA,記憶體
屬性(組織):::ADI
屬性(產品類別):::
屬性(網站單元):::ZEIE