近年來手持式行動裝置快速成長。大量的音樂/視訊播放與影像處裡等多媒體應用被整合進諸如手機,個人數位助理(PDA)與手持式多媒體播放器(PMP)。除此之外,光采炫目的繪圖人機介面(GUI)以及三維繪圖遊戲更是被視為促使手持式行動裝置下一波的成長動力來源。不容置疑,會有越來越多的針對各種標準的音頻/視訊標準的硬體加速器以及繪圖處理器被嵌入在手持式行動裝置平台上。到目前為止,已經有許多低功率繪圖處理器的發表[1][2][3]。從系統的角度來看,如果能將視訊加速器與繪圖處理器加以整合不但能增加硬體利用率,減少晶片面積降低成本更能減低消耗功率,這對於下一代多媒體手持式行動裝置是個非常重要的因素。
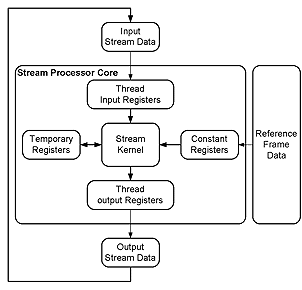
雖然視訊與三維繪圖應用在資料結構與運算型態上有許多的不同,但以資料串流模型(Data streaming model)[5]來看其實是非常相似。因此我們提出資料串流模型(Stream processing model)的多媒體串流處理器架構來處理視訊與三維繪圖運算。串流處理模型如(圖一)所示。此處理器亦為第一篇被記載單一架構能同時支援三維頂點處理運算(Vertex Shader Model 3.0)[4]及視訊壓縮功能的低功率晶片。在此創新的架構中提出了三項創新的技術,來達到最低功率與最高的硬體利用率以及最高的處理速度。分別為可調適性多執行緒技術(Adaptive Multi-Thread, AMT),可重組式記憶體陣列架構(Configurable Memory Array, CMA),與幾何轉換後濾除模組(Early Reject After Transform, ERAT)。最終此處理器能達到三維繪圖中12.5百萬頂點輸出及使用完全尋找移動估計演算法(Full search motion estimation)可達到每秒三十張CIF解析度(352x288)的視訊壓縮。
串流處理器架構
(圖二)所示為串流處理器核心架構。此核心為雙執行槽超長指令集架構(Two-issued slots VLIW)並採用單一指令執行多重資料流(SIMD)指令。當兩個指令槽(Slot)同時執行,每個指令槽執行四個通道的浮點運算,將可達到每秒四億個浮點運算(400MFOPS)。在針對視訊壓縮處理指令[7]的定點運算下,更可以達到每秒八億個定點運算(800MOPS)。可重組式記憶體陣列架構(CMA)可根據應用程式的需求,重組成(圖一)中,不同型式的暫存器集(Register files)。為了更降低功率,資料路徑前回饋(Data forwarding)與時脈截止電路(Clock gating)同時被引用與各個管路間(Pipeline stage)與處理單元(Process element),並可直接由指令集控制。
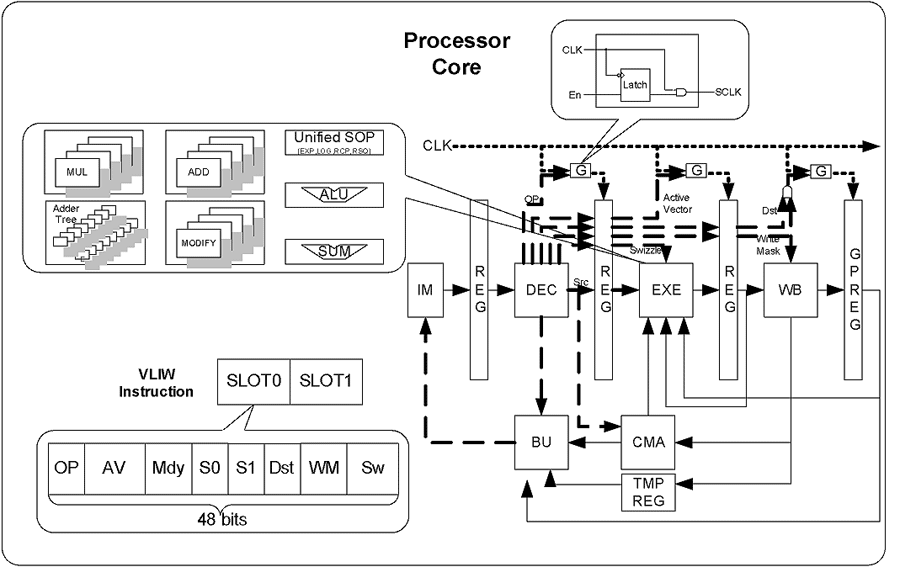
| 《圖二 串流處理器核心架構》 - BigPic:899x566 |
|
可調適性多執行緒技術
可調適性多執行緒技術(AMT)結合資料路徑前回饋輔助,可大幅減低資料危障(Data hazard)的發生機率,降低管路間停滯(Pipeline stall)增進執行效能. 甚至,可減少暫存器集的存取次數進而降低功率的消耗。可調適性多執行緒技術(AMT)有效率的使用了最少的執行緒而達成最大的隱藏執行週期(Hidden latency cycles)。(圖三)為可調適性多執行緒(AMT)與傳統執行緒[3]的執行排程示意圖。圖中,材質載入指令(TxLoad)需要六個執行週期。在傳統的多執行緒架構下,只有四個執行緒是無法完全隱藏執行週期的。相較於傳統執行緒,可調適性多執行緒(AMT)會針對目前執行的指令來判斷是否要改變目前的執行緒來達到最大的隱藏執行週期。由圖可知,同樣為四個執行緒,此技術可以完全隱藏材質載入指令。

| 《圖三 多執行緒執行排程》 - BigPic:699x416 |
|
可重組式記憶體陣列架構
在手持式行動裝置中記憶體頻寬是非常重要的資源。因為在有限的電池能量下,記憶體存取佔了相當大的功率消耗比重。在我們提出的串流處理模型中,根據不同的應用同時採用了快取記憶體(Cache)與緊密偶合記憶體(Tightly coupled memory)技術大幅的降低外部記憶體的頻寬。根據實驗,在繪圖處理時可以達到60%頂點快取擊中率,且減少重覆頂點資料的存取與消耗功率;在執行移動估計(Motion estimation)的時候,我們的架構能支援等級C的資料重複利用技術[6]達到節省86%的記憶體頻寬。可重組式記憶體陣列架構(CMA)使用了四通道與八個實體記憶體庫以提供晶片內記憶體資源(On-chip memory pool)。此記憶體資源邏輯上映射至 (圖一)中的各項暫存器集可以作為串流快取記憶體以及常數參考記憶體。而可重組的特性使得,針對不同的應用可以分配不同大小的記憶體給串流快取記憶體或其他的暫存器集進而達到最高的記憶體利用率。(圖四)表示不同的應用下,可重組式記憶體陣列(CMA)中的資料組織與分配。
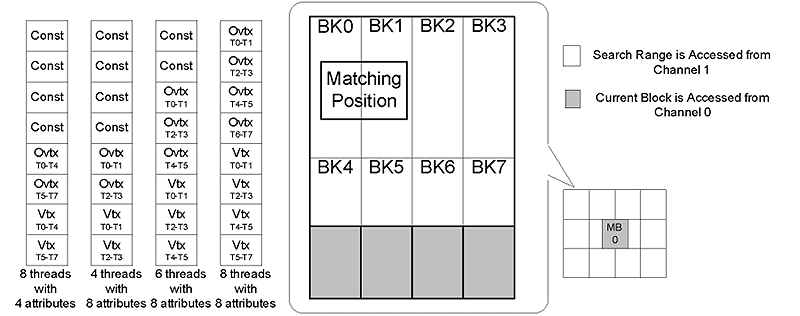
| 《圖四 可重組式記憶體陣列中資料組織示意圖》 - BigPic:799x315 |
|
幾何轉換後濾除模組
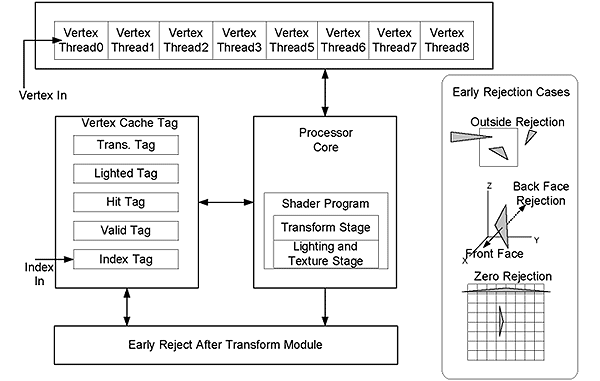
| 《圖五 幾何轉換後濾除模組》 - BigPic:599x380 |
|
在三維繪圖處理管路中,頂點處理器進行幾何物件(Primitive)中所有頂點的幾何轉換 (Geometry transform),打光(lighting)以及貼圖(Vertex texturing)運算。在將渲染(Shading)過後的頂點送至像素處理器的時候,根據實驗會有一部分的幾何物件無法呈現於屏幕而被遮蓋掉, 這導致了頂點處理器消耗了多餘的功率在無法被視見的幾何物件上。我們在此提出了幾何物件內容導向(Geometry-content-aware technique)的技術稱為幾何轉換後濾除(ERAT)技巧。此技術可以在頂點處理器中當幾何轉換處理完畢,即可判別幾何物件的視見率,提早濾除無法被視見的幾何物件進而省去大量功率提升頂點的產出率。我們使用了獨立的幾何轉換後濾除(ERAT)模組來偵測無法視見的幾何物件。(圖五)說明了幾何轉換後濾除模組,串流處理器與串流快取記憶體的協同運作。右側圖則表示三種可被偵測的無法視見幾何物件。
晶片實做
這顆晶片使用了台積電0.18微米製程,晶片大小為8.91mm2頻率為50MHz。此晶片的功能特色如下表所示,量測到的功率為8.6mw,晶片如(圖六)所示:
(表一) 晶片規格
Process Technology |
TSMC 0.18um CMOS 1P6M |
Chip Size |
2.7mm x 3.3mm |
Supply Voltage |
1.8V |
Clock Frequency |
50MHz |
Power Consumption |
(*)8.6mw |
Features
|
OpenGL ES 2.0 Support
Shader Model 3.0
Video encoding IME capability |
|
| (*)Shader Program Specular Light with 20 instructions |
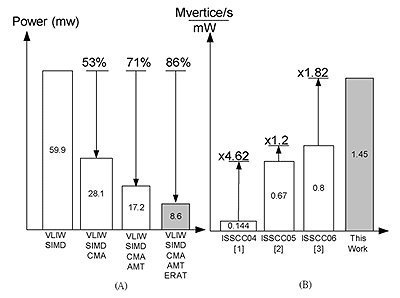
(圖七)呈現了功率消耗與執行效率比較圖。當所有的主要技術被同時引用時,功率消耗可以減少86%相較於只使用超長指令集核心架構。我們也使用了效能比(Performance index),每秒每瓦有多少的頂點產出率,來評比我們的架構與之前發表過的晶片。可以看出,我們能達到1.82倍的效能比向較於之前頂尖的晶片。
結論
此8.6mw低功率多媒體串流處理器,能達到12.5百萬的頂點輸出,且在視訊壓縮上使用完全尋找移動估計演算法能達到每秒30張CIF解析度(352x288)。整個核心的晶片大小僅有8.91mm2能達到同時滿足手持式行動裝置平台上三維繪圖與視訊壓縮的所需的處理能力。
此研究成果已發表於2007年國際超大型積體電路設計會議(2007 Symposium on VLSI Circuits)
曹友銘先生為國立台灣大學電子工程博士候選人。
林昱呈先生為國立台灣大學電子工程碩士。
孫志豪先生為國立台灣大學電子工程研究所碩士班學生。
陸家恆先生為國立台灣大學電子工程研究所碩士班學生。
簡韶逸先生為國立台灣大學電子工程博士, 現任國立台灣大學電機系助理教授。
參考文獻
[1] F. Arakawa. “An embedded processor core for consumer applications with 2.8gflops and 36m polygons/s fpu,” ISSCC Digest of Technical Papers, pp.334-335, 2004.
[2] J. Sohn. “A 50mvertices/s graphics processor with fixed-point programmable vertex shader for mobile applications,” ISSCC Digest of Technical Papers, pp.192-193, 2005.
[3] C. Yu. “A 120mvertices/sec multi-threaded vliw vertex processor for mobile multimedia applications,” ISSCC Digest of Technical Papers, pp.408-409, 2006.
[4] K. Gray. “DirectX 9 Programmable Graphics Pipeline,” Microsoft Press, 2003.
[5] U. J. Kapasi. “Programmable stream processors,” Computer, pp.54-62, August 2003.
[6] J. Tuan. “On the data reuse and memory bandwidth analysis for full-search block-matching vlsi architecture,” IEEE Trans. Circuits Syst. Video Technol, pp.61-72, January 2002
[7] Y. M. Tsao. “Low Power Programmable Shader with Efficient Graphics And Video Acceleration Capabilities for Mobile Multimedia Applications,” ICCE Digest of Technical Papers, pp.395-396, 2006.