由於7奈米及更先進製程愈趨複雜昂貴,正採用不同方法來提高效能,亦即降低工作電壓並使用新IP區塊來強化12奈米節點,而這些改變對於AI加速器特別有效。格羅方德的客戶已在AI加速技術上取得成功,這也為新一代12LP+技術奠定基礎。
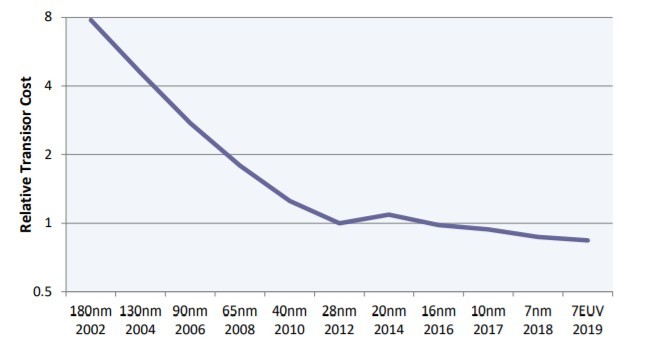
摩爾定律可能不會消失,但它正在迅速走向盡頭。經過50年的持續不斷進步,實現下一個節點變得越來越艱難。在過去十年中,微影(lithography)技術的成本不斷上漲,特別是近來導入極紫外光(EUV)後。從16奈米節點開始,轉進到3D電晶體(FinFET),也使得成本進一步提高。結果,如圖一所示,電晶體成本過往驟降的幅度已趨緩,在之前幾個節點中只有緩慢進展。新款晶片設計的初始下線(Tape-Out)成本也從28奈米的100萬美元,飆升至7奈米的1,000萬美元左右。
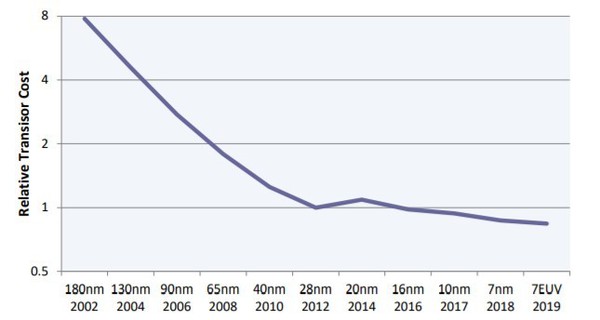
| 圖一 : 摩爾定律逐漸趨緩。在28奈米之前,每個節點的電晶體成本下降幅度約40%,但此後每個節點的成本僅下降10%。(source:The Linley Group) |
|
部分晶片公司願意付出更高代價,只為了讓自家設計擁有更好的效能和電源效率,但這些效益也在減緩中。英特爾處理器從2002年的1.0GHz飆升至2005年的3.8GHz,但在過去十年間,最高時脈頻率每年僅成長3%。其他處理器設計師也面臨類似難題:自2014年以來,Arm架構的CPU的速度每年提高約6%。其中一部分問題在於,大多數設計已經在1.0V以下運作,幾乎沒有進一步降低電壓乃至於功率的空間。幾經權衡後,許多公司不會將晶片設計推進至7奈米節點甚至超越7奈米的先進製程。
為了協助這些公司,格羅方德提升了旗下12奈米技術,以提高效能和電源效率,並創造了新一代12LP+製程。這些改變對於AI(神經網路)加速器特別有效。例如,神經網路經常採用乘累加(MAC)函數,因此格羅方德對旗下12奈米 MAC單元加以重新設計,以將電源效率提高65%。新款SRAM單元則可針對神經網路中常見的循序數據存取進行最佳化,使電源效率提高了一倍。此外,新款雙功函數金屬閘極可削減電源電壓,讓功耗再降低50%。
格羅方德的客戶已在AI加速技術上取得成功,這也為新一代12LP+技術奠定基礎。某家新創公司打造了一款採用12LP技術的晶片,實現820 TOPS(每秒820兆次浮點運算)。另一家使用12LP的客戶則在熱門ResNet-50推論基準上,於眾多資料中心晶片中達成了領先業界的電源效率。另一方面,有一款晶片採用了格羅方德22奈米技術,在功耗僅為50mW的情況下,實現了令人印象深刻的AI效能。
電晶體越小 問題越大
在最近的節點中,微影技術已成為成本增加的關鍵因素。深紫外光(DUV)微影技術在28奈米節點便達到極限。為了進一步發展,業界轉向昂貴的22奈米雙重圖案法,以及更昂貴的10奈米四重圖案法。
在7奈米中,晶圓廠開始採用極紫外光,但這項科技需要新型且昂貴的光罩、新型光阻劑,以及重達180噸且造價超過1億美元的新式步進機。FinFET需要額外的製程步驟來形成3D電晶體。7奈米節點更為導通孔引進了一款新材料(鈷)。每個節點還將在堆疊中加入了另一個金屬層(目前台積電5奈米已多達14層),從而增加了更多製程步驟。
每項新製程步驟都會使晶圓成本增加,這意味著微影技術工具的高昂成本有必要分攤到所有晶圓上。因此,自28奈米節點以來,晶圓成本不斷迅速攀升,幾乎扼殺了降低電晶體成本的可能。顧名思義,雙重圖案法需要兩倍的製程步驟,四重圖案法則需要更多。儘管EUV步進機排除了多重圖案法,但設備成本較高、產出量較低的情況,意味著EUV層的成本是DUV層的三倍。其中,EUV光罩必須採用可阻擋近X光(near-X-ray light)的特殊材質,且作工需要非常精細。也因此,隨著EUV獲得採用,包括打造出完整的光罩在內的下線成本正迅速上升中。
根據摩爾定律的要求,上述英雄式壯舉持續讓每個節點的電晶體面積減少50%左右。由於更小的電晶體需要更少的電子來切換狀態,它們消耗的功率更少,切換速度也更快。然而,隨著電晶體縮小,大多數設計師只是一味地將更多功能封裝到晶片中,讓裸晶面積保持不變。這也讓電晶體之間的金屬接線仍具有相同長度。更有甚者,這些各節點上的接線變得更薄,從而增加了電阻。對於複雜的高階處理器來說,透過這種互連而推動訊號所需的功率,如今遠超過電晶體的切換功率,將電晶體縮小的好處降到最低。在7奈米階段,許多設計師發現時脈頻率鮮少甚或毫無增加,至於電源效率,與前一個節點相比也許提高了10%。
這種情況在未來的節點上不太可能獲得改善。儘管5奈米採用的是單次圖案法EUV,但是這種方法對於下個節點而言並不足夠。選項之一是採用雙重圖案法EUV,這又使這些層的成本加倍。為了避免此問題,設備製造商正在研究一套名為高數值孔徑EUV的新技術,它可以在單一道次中打造更細微的特點。但是,這套設備將比當前的EUV步進機更加昂貴,而且這項技術需要新型光阻劑材料,而這種材料仍在開發階段。
該節點還將採用閘極全環場效電晶體(GAAFET)這款新技術,這將需要追加製程步驟,從而進一步提高成本和設計複雜性。解決所有這些問題的同時,3奈米及未來節點的導入有可能因此延後。
追求更聰明設計
格羅方德並未一路掉進縮小晶片的深淵,而是決定強化旗下具有成本效益的12奈米製程,以提供更好的效能和電源效率。特別的是,格羅方德專注於熱門的AI增強型晶片市場,從伺服器專用的AI加速器到整合微型AI引擎的微控制器,無一不包。儘管終端應用各有不同,但這些晶片的需求全都一樣:可謂常見AI演算提供最大電源效率。
時下最流行的AI應用程式可執行卷積神經網路(CNN)。顧名思義,CNN主要用於執行卷積函數,將固定權重與輸入的啟動值重複相乘,然後將乘積加到累加器上。為了讓這類演算更有效率,格羅方德將重心擺在兩件事上:從SRAM中獲取啟動值,以及有效運算MAC演算。
通用型處理器一般將SRAM用於快取記憶體或其他晶載記憶體,因為這些記憶體必須迅速回應所有存取模式。因此,晶圓代工廠會針對隨機存取,為旗下SRAM設計進行最佳化。這些SRAM陣列可一次獲取多個數值(例如快取列),然後使用多工器(mux)選取所需數值,並捨棄其他。然而,卷積運算通常得在很大的陣列上運作,因此一般是按順序處理資料。
格羅方德新設計了一款SRAM,可同時讀取和鎖存四個數值,然後使用多工器選擇所需數值。鎖存器會減慢第一次存取的速度,但是如果第二次存取依照順序,則可以立即從鎖存器讀取下一個值,無需再次存取該陣列。因此,一系列的順序性讀取可以消除四個存取中的三個,從而大幅降低SRAM陣列所需的功耗。對於典型的CNN而言,此方法可將SRAM功耗降低50%左右。
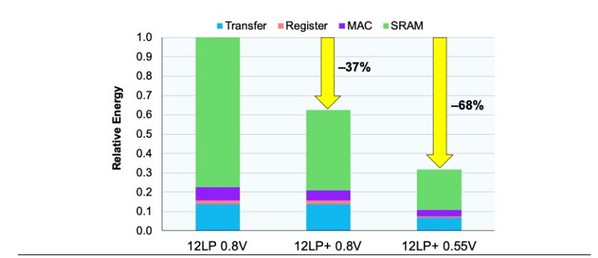
| 圖二 : 12LP+的減能情形。比起先前的12LP技術,新電路設計和低電壓的組合,可將典型CNN演算所需的能量降低近70%。(source:格羅方德) |
|
使用低電壓演算所面臨的兩項挑戰在於:設備不匹配,以及SRAM運算所需的電壓邊限。對12LP+而言,格羅方德為了邏輯裝置和SRAM單元實施了分開的閘極堆疊。這兩個堆疊有不同的工作函數,經過調整後可減少不匹配的情況,並將電壓邊限降至最低。該技術可以將SRAM電源電壓從0.7V降至0.55V,從而降低功耗。
如圖二所示,在典型的CNN演算中,記憶體佔了功率的最大部分,另一個佔用最多的則是MAC單元。在與客戶討論的過程中,格羅方德發現,有別於通用型CPU會針對單一執行緒效能和多重GHz時脈頻率進行最佳化,AI加速器可處理高度平行的工作負載,並在1GHz左右進行演算,實現電源效率最大化。因此,格羅方德新設計了一款乘法器和加法器,並針對較低的時脈頻率進行最佳化,從而將功耗降低25%。
綜上所述,在相同的電源電壓下,這些優化作法可降低37%的功耗;而在利用雙工函數閘降低電源電壓時,功耗降低了68%。換句話說,相對於在舊款12LP製程中使用標準邏輯塊的電源效率,卷積函數核心(在CNN計算週期中會消耗90%或更多)演算時的效率可達三倍之多。
為AI領導者提供動力
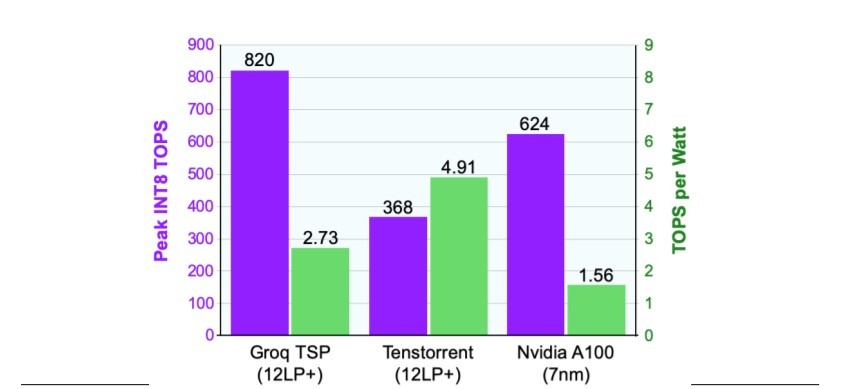
這項新技術以格羅方德12LP製程的成功為基礎,為AI產品提供動力。以矽谷新創公司Groq為例,它新開發了一套可加速神經網路的架構方法,將數百個功能單元匯集在單一核心內。這款龐大設計包括220MB的SRAM和逾20萬個MAC單元。Groq採用了12LP,好讓如此龐大的設計保持在300W功率預算內。該晶片以1.0 GHz的初始速度,針對INT8數據可實現820 TOPS的峰值產出,超過了所有其他已發表的加速器。
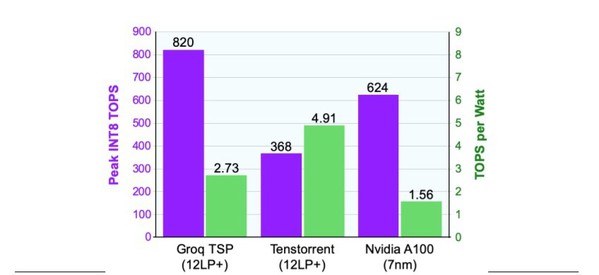
| 圖三 : 高階AI加速器比較圖。相較於NVIDIA的新款產品A100,Groq的TSP加速器可提供更高的效能,且功耗更低。Tenstorrent的目標則是降低效能點,但是讓電源效率達到輝達加速器的三倍。(source:供應商資料) |
|
加拿大新創公司Tenstorrent雖然也加快了推論速度,卻選擇了不同的設計目標:為匯流排供電的PCIe卡設下將75W功率限制。首款晶片具備120個獨立核心,每個都包括1MB的SRAM和大約500個MAC單元。這種方法仍然需要大量的SRAM和MAC單元。該晶片以1.3GHz的初始速度,實現368 TOPS。如圖3所示,12LP技術可幫助Tenstorrent達到每瓦4.9 TOPS,堪稱資料中心產品中最高的效率等級。
擁有最大市占率的輝達最近發布了以新款Ampere架構為基礎的A100加速器。Ampere導入了許多創新功能,並將峰值效能提高到624 TOPS,超越所有已發表的晶片(Groq產品除外)。不過,儘管已縮小到7奈米技術,但A100仍需要400W的熱設計功耗,較先前的12奈米產品高出33%。
為了滿足這筆增加出來的功率預算,相對於12奈米產品,輝達必須降低時脈頻率,並讓裸晶上15%的核心失效。此一策略並不尋常,可能代表晶片的實際功率遠高於模擬功率。因此,儘管輝達A100的電晶體較小,每瓦效能卻嚴重落後於Groq和Tenstorrent的晶片。
格羅方德還支援客戶開發嵌入式系統的低功耗晶片。在嵌入式系統中,有許多也加入了AI功能。這些產品比資料中心加速器更注重成本,因此它們通常使用較舊的節點。GreenWaves和Perceive等創新型新創公司選擇了格羅方德的22FDX製程,它採用了絕緣層上覆矽(FD-SOI)技術,不但可節省電力,還不會增加FinFET節點的成本。FD-SOI支援對反向偏壓(back-bias)作自我調整,讓設計師可以根據晶片狀態來改變本體偏壓。例如在睡眠模式下,施加反向偏壓可以將漏電流降低達10倍,進而大幅延長電池壽命。但是,當設備處於運作狀態時,施加正向偏壓可將效能提升到最高。
GreenWaves GAP9是一款RISC-V微控制器,包括一個小型神經網路加速器,運作功率僅50mW,執行AI工作負載時,電源效率是標準微控制器的34倍。Perceive則創造了全新的AI演算法,在旗下Ergo晶片上運作的功率為70mW。有了FD-SOI技術,Ergo的55 TOPS/W在業界評比名列前茅。為了獲得更高的效率,22FDX還支援類比式記憶體內運算;該晶圓代工廠已與比利時微電子研究中心(IMEC)研究人員合作,透過此技術開發出一款測試晶片,可達到2,900 TOPS/W。
比7奈米更好
爾定律如今已跟不上時代。儘管業界一直在尋求各種縮小電晶體的新方法,但此類技術越來越昂貴,幾乎抵銷了大部分成本優勢。電源電壓正逼近基本極限,防止減能情況導致功率降低。隨著電晶體越來越小,切換速度與減能情況陷入極大困境,亦即透過越來越細的金屬線推播訊號有其難處。因此,處於領先地位的晶圓代工廠將逐漸面臨挑戰:僅透過縮小電晶體的方式,在成本、速度或功率等方面取得有意義的進展
處理器設計師已經開始創造更加專業的設計,以適應此一新環境。舉例來說,打造AI專用的加速器為標準CPU和GPU分憂解勞,已成為新興趨勢。各大晶圓代工廠可以跟進的方式,包括為旗下技術打造應用程式專用的版本。有別於單純縮小電晶體和金屬堆疊,這些版本可以應用最佳化後的功能塊和電路設計,以更加符合特定產品類型的需求。
結語
格羅方德已配合旗下12奈米節點採取這條路線,為AI加速器打造了12LP+技術。最佳化作法包括可將電壓降低甚多的雙工函數閘、經高載最佳化的SRAM以及低功率MAC設計。總而言之,這些最佳化作法將典型卷積運算的電源效率提高了3倍。相較於其他晶圓代工廠僅將現有設計從12奈米移植到的7奈米,格羅方德的改善效果要大出許多,而且設計與下線成本也低於7奈米。
客戶在使用格羅方德技術後,已經取得令人印象深刻的成果。採用12LP製程的Groq和Tenstorrent在AI效能和電源效率方面,領先所有資料中心加速器。Perceive和GreenWaves則是利用格羅方德22FDX技術降低客戶端設備的功耗,並提高效率,協助將AI處理擴散到邊緣設備。格羅方德還提供了矽光子技術,將資料中心連接到邊緣設備,從而完成了端對端AI播送(end-to-end AI play)。這些案例說明了格羅方德如何在避免7奈米高成本的前提下,協助客戶實現領先業界的效能。新款12LP+的增強功能絕對是讓您大有斬獲的最佳利器。
(本文作者Linley Gwennap為Linley Group首席分析師暨《微處理器報告》(Microprocessor Report)主編)
**刊頭圖(source:Globalfoundries)