AMR語音編解碼器之運算複雜性──MIPS
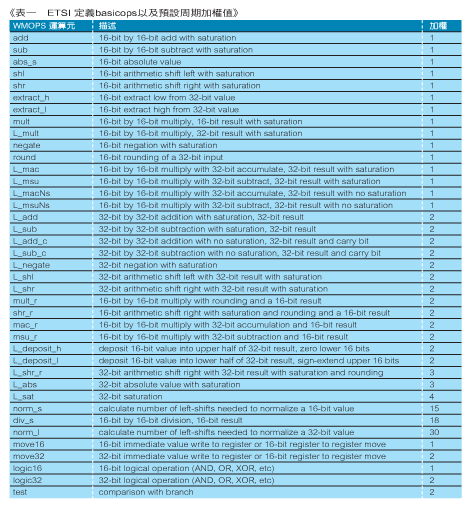
AMR語音編解碼器的MIPS是經由WMOPS(Weighted Millions of Operations Per Second)的使用來估計的,這個是由ETSI所開發的方法,用來計算資料存取時,基本的數學與邏輯上的運算並對整個運算數目進行加權,用來反映出一顆DSP上預期的效能。WMOPS是用來預估MIPS的良好慣例,因為它們能夠隨著處理器架構改變而有所適應,或者若已知道執行某一特定運算將耗費多少週期時,系統架構能夠隨之微調。(表一)列出 WMOPS 運作(通常是指 basicops) 和它們在AMR語音編解碼器參考程式碼時的原始預設加權:
| 《表一 ETSI 定義basicops以及預設周期加權值》 |
|
這個表顯示一個週期的期望數目,以執行一個特定的運算。例如,一個32位元的絕對值(L_abs)被期望花費三個週期並增加一個16位元到飽和狀態(saturation)(add),並預計花費一個週期。經由AMR語音編解碼器所執行的一個測試向量,一個基礎線(baseline)的WMOPS(以及接下來的MIPS)值會被決定。整個供AMR語音編解碼器的WMOPS是以4.75kbps 的模式運作,其中約有10.7是供編碼器所用而有2.0是供解碼器之用。當然,如果目標處理器以較慢或較快的速度來執行任何前述的運算,則加權表格必須要跟著調整,以提供更好的總體WMOPS估計值。
應該注意的是,這個WMOPS數字沒有考慮到一個目標處理器在架構上的任何限制,例如一個有限的暫存器組合或深層的管線(deep pipelines)或是如果處理器的運算單元沒辦法以一個準確的位元形式來處理這些運算,這些都將在模擬必要活動時,導致額外的週期時間。此外,這些測試沒有考慮到從運算的計算過程當中取得資料所可能產生的限制或額外增加的週期時間。參考程式碼假設當資料取得(data fetch)是由於數學運算的需求時,能夠在不增加額外週期時間的情況下被負載。這樣的假設很可能是不真實的,其主要原因有二:因為處理器並沒有支持所有來自數學運算所需資料的模擬負載,或者是因為被負載的變數是被放置在一個非零的等待狀態的記憶體。然而,WMOPS 值對於決定一個處理器上特定運算的絕對最佳可能效果,是一個很有價值的指標。
AMR語音編解碼器的運算複雜性──記憶體
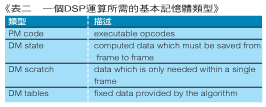
當我們在對此一性質的嵌入式系統進行編碼時,很重要的是把整個記憶體使用分散成許多PM(program memory;程式記憶體)和DM(data memory;資料記憶體)這些類別及其簡述,如(表二)所示:
DM的狀態可以在Speech_Encode_FrameState a和nd Speech_Decode_amrState的結構定義上被發現。這些結構必須在每個訊框中保留它們的值且被放置在讀取/寫入(R/W)記憶體上。編碼器需要2744個狀態位元(假設它正在使用VAD1)且解碼器需要1628個狀態位元。
在AMR參考程式碼中,DM散佈通常發生在堆疊中。當這個在PC應用上可能是經常且常態的發生時,在嵌入式系統上,減少以堆疊為基礎的散佈並透過其他的方法來進行配置也是相當常見的。在將AMR語音編解碼器移植到目標硬體的部分,將會有詳細的描述。
在AMR參考程式碼上能夠發現DM表格散佈在許多C檔案上。在AMR語音編解碼器所使用的整個表格的總數是14729個16位元的字元。這個資料只能被讀取且能夠散佈在內部DSP記憶體和外部系統記憶體。
執行AMR語音編解碼器的取捨和考慮因素
當在對一個語音編解碼器(或任何運算)進行移植或編碼時,考慮用來執行該運算的整個系統,以及處理器和應用上的需求是很重要的一件事。這些限制可能來自DSP/系統架構和終端應用上的需求,並使得整個移植過程更複雜。在這個範例當中,工程師利用ETSI所提供,最初是針對一個ARM處理器所開發參考程式碼。ETSI提供一個完整的ARM語音解碼器和編碼器,以及解釋程式碼如何運作的文件。
MIPS v.s.記憶體使用
決定可允許的運算執行時間和整個記憶體的使用量之間的平衡,是嵌入式程式運算中最重要的取捨之一。如前所述,語音編解碼器必須在下一組被安排送達的資料抵達前,即時處理它現有的資料。在上一期,已經討論了在完全雙工裝置下,以20ms的時間內,用8MHz進行抽樣,來處理160個字元區塊的需求。
一般而言,通常是很有可能經由修正一個演算法在記憶體當中的位置,來降低整個MIPS。現在有許多DSP都包含了多階層的快取記憶體或是針對每個存取而有不同等待狀態的多種記憶體類型。DSP通常也支援那些能夠在一個次要的記憶體空間放置資料的方法,以便進行雙重的資料存取;在某些DSP架構下,可能是屬於程式記憶體的一部分,或者是一個小規模的高速暫存空間。不論如何,在這個部分需要仔細的選擇,以確保次要的記憶體空間被有效的使用。在需要兩個陣列同時讀取和MAC’ed(multiply-accumlated;多重累積)的一個相關或迴旋(convolution)功能,是需要利用到次要記憶體典型範例。透過記憶體最佳化用來改善MIPS的方法將會在稍後進一步的詳述。
運算上的應用限制
AMR語音編解碼器是特別針對無線手機所設計;這隱含著特定的系統限制將能協助設計人員決定基礎線(baseline)的運算需求。由於一個行動電話是一次處理一個對話(因此需要語音編解碼),這麼一來,排除了同時執行多個語音編解碼運算請求的需求。代表著AMR語音編解碼器被移植且是不允許再次進入(re-entrant)。一個再次進入的運算需要參考所有透過指標器(pointers)所處理的狀態和scratch記憶體,而非絕對的記憶體位址。一個直接使用已定址的DM不能夠再次進入,因為來自另外一個請求的處理運算已經打斷一個請求的scratch和狀態記憶體。
如果語音編解碼器再次進入(re-entrant),高階應用程式運算介面(Application Programming Interface;API)功能的呼叫將包含指標器到scratch和狀態結構,所有被存取的變數將會被來自此一基礎位址(base address)的一種補償(offsets)。相對於絕對的記憶體存取,ADSP-218x 架構對於以指標器為基礎的記憶體存取是比較沒有效率的。因此,一個被執行單一AMR的範例版本是同時儲存了MIPS和記憶體。
除此之外,因為AMR是在一個無線裝置當中執行,為了同時處理多種運算以支援一通電話呼叫(頻道編解碼、等化器、運算系統、使用者應用等等),其不能使用太多內部的程式或資料記憶體 。這表示記憶體分析應該針對所有的變數與陣列來執行,以決定快速記憶體(例如一個位在DSP的內部SRAM)和慢速記憶體(例如外部的快閃記憶體Flash)之間適當的資料分割。執行此一分析所使用的方法,將在下面加以說明。
將參考的AMR語音編解碼器C程式碼移植到目標硬體上
很明顯地,將AMR語音編解碼器進行移植的第一步驟是取得參考的C程式碼。然而,設計團隊必須檢查在資料程式碼的完成日期之後,是否已經有任何的變更要求被執行並獲得批准。有關AMR語音編解碼器的變更要求可以在3GPP(3rd Generation Partership Project)網站上找到[1]。包括GSM網路在內,許多使用在第二與第三代無線網路的標準是由3GPP所負責營運與更新的。通常3GPP會提供所有必要變更的解釋與原始程式碼。
一旦進行了這些更新,參考C程式碼就準備好進行修正,以便對嵌入式環境中對特定處理器的獨特性提供較好的支援。在此我們將以ADI的DSP產品AD6526為例,來說明下列各項工作的修正:
評估和發展一個basicops的準確位元版本
當參考程式碼轉成一個最佳化的嵌入式運算時,最重要的工作之一是適當地處理basicop功能。當許多basicop功能能夠轉換到一個單一的DSP指令時,參考C程式碼在使用功能呼叫多數的數學運算就顯得沒有效率。將basicops最佳化最常用的方法是利用輸入線路(inline)C的預置處理器指令,來告知編譯器不要執行某一功能呼叫,而把已被呼叫的功能程式碼直接包含在檔案裡。對一些現今的DSP架構而言,發展工具包括有一個basicop路徑的資料庫,使得ETSI語音編解碼能夠更容易地移植到特定的架構。在AD6526上,多數簡單的basicops變成簡單的組合語言指令,而最複雜的basicops(such as div_s)則維持功能呼叫的執行方式。
計算並分析記憶體存取到變數和表格中
分析和最佳化AMR語音編解碼器最重要的一個部分,是決定在一個資料架構的處理期間,對所有表格和變數的存取數目。不同的表格和變數有很多不同的存取頻率,而一些存取對於某些AMR的特定模式是很獨特的。因為這樣的變數性質,顯示出存取到每個表格的數目和考慮記憶體架構和等待狀態是如何影響整個必要的MIPS,是很重要的一件事。
如果沒有硬體或軟體的模擬,來支援計算一個記憶體區域的存取計算,參考C程式碼能夠被偵測,以用來決定每個變數和陣列的存取數目。一個計算記憶體存取的方法是在每個被存取的變數和表格的位置旁邊,放置一個計數器的巨集指令,並透過編解碼器來執行其中多個測試向量之一。這麼做將提供在每個框架(frame)中的存取數目。如果可用的記憶體總數和相關的等待狀態是已知的,人們便很有可能對系統中放置變數和表格在低速記憶體(slow memory)當中的影響,取得良好的估計。
當執行此一測試時,對語音編解碼器的所有八種模式執行測試向量是很重要的。當每個AMR模式在不同的MIPS下執行且並不是所有的表格在每個處理模式中都會被存取時,每個操作模式下每個記憶體存取的頻率是很重要的資訊。MIPS較強且較經常發生的資料存取會被移到較快速的記憶體部分,以便均衡不同操作模式的效能。
堆疊使用的最小化與決定一個適當的記憶體架構
供AMR語音編解碼器所用的參考程式碼,是把它所有的暫時變數(temporary variable);也稱為散佈變數(scratch variables)放在堆疊當中。堆疊是一個普通的資料結構,其中資料和位址是在記憶體當中循序地被儲存與存取。在C功能當中所宣告並使用的變數是放在一個堆疊當中,而當該功能中止時,記憶體空間會被釋放出來,以供未來使用。這是一個管理記憶體的簡單方法,但對嵌入式的設計而言卻是很沒效率的。把所有暫時的變數放在堆疊上,限制了慢速和快速記憶體的使用效率。
此外,如果其他的運算也使用堆疊,該系統架構會被強迫讓最更糟的堆疊所佔用。如果先佔運算(在目前的工作/運算完成之前,允許一個工作/運算開始執行)是被允許的,且在系統上有多階的優先順序,這可能導致無效率的記憶體利用。堆疊的使用也強迫變數以循序的方式放置,且不允許多個記憶體全部用在雙重的資料存取上,這是DSP架構與運算當中相當重要的一部分。最後,在某些DSP中,相較於直接定址的陣列堆疊記憶體的使用是很沒效率的,DSP通常不處理以指標器為基礎的存取和直接的記憶體存取。
由於上述的原因,下列的方法是用來移除來自C功能的堆疊操縱。常見的方法是「動態記憶體配置裝」,例如ANSI C標準功能malloc。Malloc將記憶體放成一堆,相當類似於堆疊的型態。這種作法的一個優點是讓多數的編譯器能夠控制那些成堆記憶體的位置,使得系統設計人員能夠把它放在適當的記憶體區隔當中。除此之外,一些malloc也能夠執行多個成堆的記憶體,使其可以根據這些記憶體被存取的頻率,提供一種將變數放置在不同記憶體區隔的方法。另外一種方法是創造一個「散佈的(scratch)記憶體結構」,透過分析每個功能上配置了多少個記憶體,然後把這些配置放在一個C結構。在此一狀況下,高階API介面能夠呼叫malloc,以配置足夠的空間。一個程式如何能夠從一個標準的、以堆疊為基礎的記憶體配置,轉換成一個使用記憶體配置和一個散布(scratch)的例子。
主要功能和兩個子功能都放在它們的散佈記憶體的一部分,形成一個稱之為scr_scrmem的結構;該結構是被配置在主要記憶體的開端且其結尾的部分取消配置(de-allocated)。當這個程式碼使用標準的記憶體配置器在一個DSP的應用上,額外的參數將會被加到配置的功能,以允許該結構被放在一個特定的記憶體類型當中。
上述兩個表列間的資料記憶體需是相同的。因為兩個子功能的散佈陣列(scratch arrays)結合在一起,它們只需要選擇兩個陣列當中較大的一個容量,來作為其記憶體(空間)。此一作法是與如何在同樣的呼叫階層,對兩個功能的區域記憶體配置進行覆蓋的作法相同。這個例子說明了在同樣階層的呼叫如何能夠安全地把它們的散佈記憶體結合在一起。如果一個運算有其他階層的呼叫在其中(由subfunc1和/或subfunc2所形成的功能呼叫),這些結構的其他階層(和潛在地以功能呼叫的精準細節為基礎的結合)將會被放在scr_sf1和scr_sf2結構當中。
在AD6536的AMR 語音編解碼器執行,不曾使用一個已通過(passed)的指標器和間接的記憶體存取從狀態和散佈的結構當中取得資料。然而,在此所創造的結構是用來創造配置該結構的空間所需的組合語言程式碼。一個小型、以PC為基礎的C語言程式是用來作為AMR狀態和散佈結構的。它可以分析結構的單元,並對該結構單元的名稱和容量所對應的每個變數,輸出一行ADSP-218X組合程式碼。透過這樣的方式,C結構被轉換成一個相同的DSP組合語言檔案,使其能夠靜態地分配到適當的資料記憶體空間。
將表格聚集成檔案的子集合
當AMR語音編解碼器在移植時,另一個重要工作是把所有來自不同C檔案當中的表格,整合成幾個檔案。表格是在程式碼中被初始化且未曾變更過的任何變數。把所有這些常數變成幾個檔案是很重要的,因為它們需要根據本身被存取的頻率,來把表格放到不同的記憶體區隔。在ETSI原始程式碼當中,表格是很簡單地被包含在其所被存取的原始檔案當中。根據一個特定DSP架構所設計的軟體開發工具,它很難(甚至是不能)任意地把不同的表格從一個單一的檔案放到不同的記憶體區隔。
處理此一情形最簡單的方法是依靠可用的記憶體,來決定所有被存取表格的頻率,盡可能地把許多最常被存取的表格放在一個單一檔案當中;該檔案將會連接到特定的記憶體區隔。決定適當的分群是透過分析從記憶體分析所得的資料,然後將最常被存取的單元放在一個單一表格當中;當較不常被存取的表格資料放在低速的系統記憶體時,前述的方式主要是以快速的內部記憶體為目標。
最佳化快取使用率並開發快取中的未使用區域以達決定性運算
由於常見DSP運算的容量和複雜性,通常需要使用一個快取記憶體的機制來處理逐漸增加的記憶體需求。在DSP運算中使用一個快取記憶體的主要問題是造成執行時間上的不確定;被執行的程式碼與其所耗費的執行時間不再是單純一對一的對應關係。此外,程式碼的中斷執行或提早執行會佔用早先已經裝滿的快取記憶體,導致後續執行時間的不確定。
在DSP運算時,促成其執行時間最糟糕狀況的原因是很重要,尤其是對於那些麻煩的即時處理限制(例如AMR語音編解碼器必須在20ms完成其處理運算或是audible artifacts發生時)。當人們要在一個已被快取處理記憶體處理的(cached)處理器找到絕對是最糟的執行時間,是很難以捉摸的,伴隨AMR語音編解碼器的某些設計決策能夠減少在快取記憶體上執行時所帶來的衝擊。如先前所提供的資訊所示,接下來的決策是有關於如何針對DSP程式碼進行分隔。
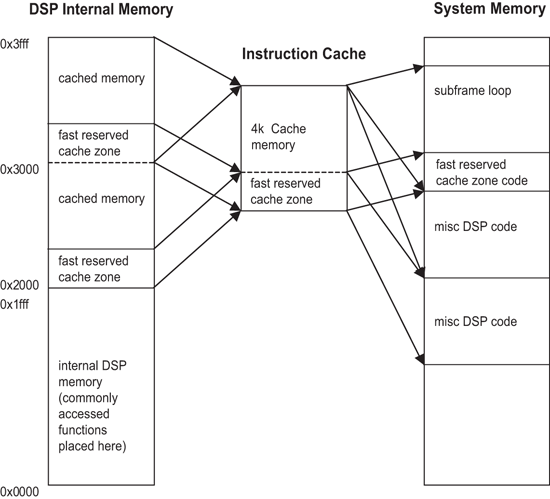
首先,最常見的已呼叫功能是被放在內部程式記憶體中。因此,這些功能不會用到快取記憶體且能夠很快地被執行。接下來,程式記憶體中一小部分的區域是對應到快取記憶體上,以配置將會常駐在此一記憶體區隔的單一功能。這種作法的效果是,一旦快取記憶體懲罰(cache penalty)此一功能的首次呼叫,但在接下來的存取中,該程式碼將被儲存在快取記憶體上且在需要時總是能夠即時提供。第三,來自編碼器次框架迴圈的程式碼會被配置,且將被對應到一個記憶體的單一4k字元區隔。這麼做是為了避免多個快取記憶體遺漏了資料當中一個框架的單一編碼運算。如果有些次框架迴路的某些部分是被放在較上層的4K,而其他的部分則放在較低的4K,快取記憶體將會在這個AMR運算當中的關鍵部分裡面,持續地重新載入,如(圖一)所示。
| 《圖一 AMR語音編解碼器最佳化效能所作的記憶體對應》 |
|
圖三為AMR語音編解碼器最佳化效能所作的記憶體對應。來自0x0000-0x1fff的DSP記憶體區域是透過指令快取記憶體。該快取記憶體的一小部分是由DSP程式碼所對應的,以確保該程式碼總能在它第一次被載入之後,持續地出現。次框架迴路是設計用來常駐在一個記憶體的單一區塊上,該區塊能在不需要造成任何閃失(也就是整個記憶體容量必須少於4K字元減掉快速保留的快取記憶體區域的容量),就能夠將其載入快取記憶體中。如果一個次框架迴路不能夠符合這個區隔,則在每個區隔的每個框架至少有四個快取記憶體失誤,必須重新載入到快取記憶體中。
AMR語音編解碼器的測試和封裝
ETSI提供包括DTX處理在內的一組測試資料,以驗證AMR語音編解碼器的基本性能。因為該運算中有許多模組和廣泛的複雜性,有數以百計的測試向量被能用來進行測試,以驗證其與原始C程式碼的一致性。一旦語音編解碼器通過這些向量的測試,它就會被視為與參考程式碼相容。然而,除了由ETSI所提供的向量數目之外,語音編解碼的完整涵蓋範圍並沒辦法單純地藉由這些測試來驗證(每個編解碼模式的處理語音的速度約為150秒)。
較為聰明的作法是透過其他額外向量的產生來證明原始程式碼與已移植的執行間的相容性。任何測試向量,不論是來自一個語音編輯器所產生的測試音調或是抽樣所得的語音,都是用來測試其運算的有效資料來源。一旦額外的測試執行之後,很有可能會在參考程式碼和已移植的編解碼器,兩者所產生的輸出中發現差異。導致這種差異的一個常見原因是如果已移植的編解碼器相對於參考程式碼,在basicops的處理上有些微不同所造成的。
ETSI的basicops有某些特定的功能(尤其是在如何處理環繞和飽和的部分)在有限的狀況下,會有發生若干不相容的機會。通常這些細微的差距不會在基礎測試向量上造成一個錯誤的發生,但是很可能會在一個新的向量測試中造成若干問題。AMR語音編解碼器在整個運算過程中利用許多門檻值(thresholds),如果被運算的值只比那些門檻值都略高或略低,就能夠在輸出上造成劇烈的變化。此外,語音編解碼器也掌握很多種狀態,而使得一個框架上的小差異,在一個錯誤發生之後,能夠創造出持續很長一段時間且大量而廣泛的運作。
一旦錯誤的精確位址和原因被確定之後,這個錯誤是否需要修正是有待爭議的。一般而言,通常會建議維持與參考C程式碼間完整相容性;此外,把它當作一個產生新的測試向量和驗證適當的運算方法越來越困難。然而,若這樣的差異不是被人厭惡的話,就不需要遵守,由非ETSI所創造針對參考C程式碼的測試。如果一個編碼運算在取捨之後,在付出了對所有可能輸入的相容性的成本下,讓一個AMR語音編解碼器運算的某一部分能夠更快地被計算,這也可能是不更改程式碼的理由。
對已移植的AMR語音編解碼器執行額外測試的可能性
除了透過功能性測試的執行來證明語音編解碼器的相容性,透過一些一般性測試的執行來決定當語音編解碼器被強迫與其他DSP運算一起運作時、或是當傳遞了初始程式碼且已經完成強化後,是否有任何編碼錯誤而影響其行為,是一種很明智的舉動。下列是這些測試所包含的一部分:
假設跨越功能呼叫的記憶體狀態
好的組合語言編碼運算,是假設一個大量且完整定義的暫存器組合(也就是所謂的暫用暫存器;scratch registers)的狀態,可以在不同的功能呼叫之間被安全地修改。如果可以這麼做,DSP程式設計人員就不需要擔心導致一個特定功能的呼叫路徑,而能夠在不需要擔心會導致主功能執行錯誤運作的前提之下,就能對任何功能進行任何修改動作。
證明此一狀態的方式不是用利用一個巨集指令來取代所有的功能回覆指令。當編解碼器被整合到一個最終系統時,巨集指令會編譯一個回覆指令;然而,在除錯階段,這樣的巨集指令是被定義作為修改所有的暫用暫存器之用。如果執行了這個測試且運算持續的適當地運作,程式設計人員將能夠確保任何適當運作的功能並沒有依賴暫存器的狀態,而那些功能能夠在不需擔心對其主功能造成影響的狀況下被修改。
發現和移除異常的記憶體存取
一個異常記憶體存取是被定義為一個記憶體的讀取和寫入是發生在一個運算所定義的陣列範圍之外。 這些錯誤(bugs)是屬於不會影響該運算本身的運作,但是當這些狀況發生在一個較大且較複雜的系統時,可能會導致微妙且難以解決的問題。
異常的記憶體寫入是危險的,可能潛在地改變其他運算的狀態,以任何一種方式,使得該運算導致不當的運作。異常記憶體一開始的出現可能是無害,但隨著這些發生異常的處理器,能夠在一個最終的應用上,導致更陌生且更微妙的錯誤。
如果目標處理器沒有硬體轉效點,它仍然有可能找到很多異常的記憶體存取。一個方法是在下載一個AMR編解碼器到目標硬體時,用已知的值設定在所有記憶體上,在執行運算之後,目標處理器記憶體會重新讀取並比較執行前後的記憶體內容,檢查是否有任何記憶體寫入是在預期的範圍之外。很不幸地,發現異常記憶體並不像檢查一個記憶體寫入那麼容易。假設所有的記憶體都可能發現一些異常讀取,若寫入運算存取一個特定的值,則運算能夠適當執行的時候,反之則否。然而,如果所讀取的值並沒使用在運算中,則能夠繼續適當的運作且異常存取不會被發現。另一個能夠幫忙發現異常讀取(和寫入)的方法是,重新安排記憶體上的陣列;經由移動許多陣列的位置,使得諸如一個記憶體對應的周邊裝置,在強迫異常的記憶體存取移到一個不同的位址後,不能安全地被讀取,而使得資料依賴性的錯誤有可能被發現。
當異常的記憶體存取(特別是寫入動作)應該避免的時候,可能有時間能夠執行在一個陣列上額外的存取,以協助改善運算的效能。很多時候,在迴路開始改善整體效能前,能夠在軟體傳遞管線(pipelines)加入一個額外記憶體讀取運算是很有優勢。然而,確定系統設計人員知道在該運算當中已經加入一個額外的記憶體存取運算是很重要的。許多嵌入式程式運算包括在增加效能與改善可靠性和可攜性之間的取捨。在執行困難的即時需求運算時,有時需要提高整合的複雜性,以取得效能上的顯著改善。如果編碼決定會導致額外讀取陣列的增加,應該在原始程式碼和公佈的筆記上仔細的記載。
未經檢驗的程式碼的檢查
決定一個從已提供的測試向量中發現未經驗證程式碼的方法是很有用處的。一些DSP供應商所提供的這種方法是統計上的描繪(statistical profiling)。統計上的描述是從被呼叫的功能和被存取的陣列當中取得資料並加以處理。因為ETSI測試向量不保證涵蓋整個AMR語音編解碼器,因此建議要精確地決定在所執行的功能當中有哪些路徑是不跟隨基礎向量集合,並產生新的向量,以使得這些路徑能夠透過程式碼來加以執行。如果不能進行統計上的描繪,巨集指令可以用來決定呼叫樹(call tree),而透過此資料,未經測試的程式碼能夠被推論出。
AMR語音編解碼器的最後包裝與文件
在完成程式碼移植和發展、除錯與測試等步驟之後,該運算已準備供整合之用。搭配實際的來源程式碼,文件是在傳遞工作進行時絕對重要的必需品。
對於一個嵌入式應用上的運算而言,清楚而完整的文件是需要的;因為在一個較大型應用的效能和相容性上,通常是依賴這些運算是如何被創造的知識以及由程式設計人員所設定的系統狀態假設而定。這一些應該提供的基本文件應該包括下列各項:
- ●一個目錄結構的總論(an overview of the directory structure);
- ●API的解釋,包含所有輸入與輸出資料類型所需要的資訊,和供編碼器與解碼器所需的一個樣本驅動程式;
- ●任何被假設的處理器狀態,包含處理器的運作模式以及經過各種功能呼叫未被使用或修改過的暫存器;
- ●已被觀察的MIPS,包含任何有關這些值(等待狀態、快取記憶體的使用等等)如何計算的假設;
- ●整體的記憶體利用,包含程式記憶體、分散的記憶體、狀態記憶體和表格;
- ●測試方法,包括任何未被ETSI所指名的測試,以及前述所建議的額外方法論測試(methodology tests)。
結論
為了可靠與有效的執行,本文試圖說明參考C程式碼在進行移植時參考C程式碼的嚴謹要求。由一個標準團體所提供的參考程式碼,有時不能讓嵌入式硬體很容易使用。當AMR語音編解碼器是針對在無線手持式裝置上的應用需求來寫成的時候,那麼實際的運算便能夠在現代的DPS上有效地執行,且初始的C語言執行也必須能夠進行各種修改,以符合一個嵌入式應用和DSP的架構。完成此一專案所需的時間大約是40個人/月。本文所說明的步驟,能夠作為在任何DSP硬體上開發即時語音編碼運算的一般性指引。(作者為美商ADI DSP軟體工程師)