嵌入型系統中處理器MIPS與週邊元件間的頻寬差距日漸擴大。系統效能並非完全取決於處理器的速度。雖然較高MIPS效率的處理器可提供更高的系統效能,但週邊元件的延遲最終仍會成為系統效能的瓶頸。針對匯流排與元件效能的分析,所得到的結果是處理器與元件效能無法完美配合,讓客戶必須面對「成本」與「效能」兩難取捨的窘境。
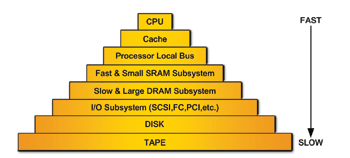
現今的系統是透過多層級子系統所組成,子系統之間的存取時間皆不相同。(圖一)顯示一個分層式「金字塔型」的效能架構:由頂層到底層分別表示速度由快到慢的層級。上方的六個子層各代表一套嵌入型系統。由上而下,各層的元件分別為:
- 1. 中央處理器(CPU)
- 2. 快取記憶體 (Cache memory)
- 3. 處理器區域匯流排 (Processor Local Bus; PLB)
- 4. 速度快且體積小的靜態隨機存取記憶體子系統
- (Static Random Access Memory; SRAM)
- 5. 速度慢且體積大的動態隨機存取記憶體子系統
- (Dynamic Random Access Memory; DRAM)
- 6. 輸入/輸出 (Input/Output; I/O)子系統:此種輸出/輸入的介面可能包括SCSI介面、光纖通道 (Fibre Channel; FC)、PCI 介面 (Peripheral Component Interconnect; PCI)與其它匯流排或是通訊協定
- 7. 磁碟陣列 (Disk array)- 包括以整合電子式驅動介面 (Integrated Drive Electronics; IDE) 、SCSI或是光纖通道(FC)等介面
- 8. 磁帶子系統 (Tape subsystem)
在這個「金字塔式」的架構圖中,愈接近底部的子系統,其需要較長的存取時間。例如:32位元中央處理器(CPU)運作速度高達200 MHz(5 ns的週期時間),而IDE磁碟陣列介面硬碟機以每秒33 MB的速度傳送資料,在32位元的匯流排中,33 MB/s 等於8.25 MHz 的運作速度 (121 ns 週期時間)。因此,32位元CPU比IDE磁碟陣列介面的速度快達24倍。
磁帶機需花費數秒的時間將磁帶轉至磁卷的開頭之後才能開始存取資料。而磁帶機的資料傳輸速度從5 MB/s 至15 MB/s不等,而5 MB/s的資料傳輸速度等於1.25 MHz (32-bit)的傳輸率;因此200 MHz的CPU比磁帶機介面快160倍,又再度證明中央處理器(CPU)與磁碟或磁帶儲存裝置的頻寬差距顯著。
在嵌入型系統本身,CPU與週邊元件之間的速度亦有相當的差距。如圖一所示,嵌入型系統中的傳輸時間隨著與CPU之間的距離而遞增。以下我們針對一套小型嵌入型電腦系統(small embedded computer system)介紹以上的議題。
嵌入型系統元件選擇要領
一般業界接納的嵌入型系統定義是指一套專為特殊應用所設計的嵌入型系統,例如像光纖通道控制器、磁碟控制器、或是汽車引擎控制器。而非嵌入型的通用系統通常能執行多種不同的應用程式,例如像桌上型PC,能執行文書處理程式、試算表、或是工程設計等類型的軟體。本文介紹部份元件之間的互動以及強調各元件之間運算(analyzing)與組合效能上的價值。以下將介紹圖一中最上面六層的元件。
中央處理器(CPU) 的選擇
現今的CPU配備有各種不同的功能組合。部份的關鍵功能包括MIPS效能、內建於晶片中的第一階(L1)快取組態與容量、執行單元的數量、晶片內建暫存器的數量、區域匯流排介面架構(包括單一分享式指令與資料匯流排的Von Neumann架構,以及擁有獨立指令與資料匯流排的Harvard架構)。
快取組態 (Cache Configurations)
取捨因素:SRAM 價格 v.s.快取效能
快取是容量小、速度快的記憶體用來改進記憶體的平均回應速度。為了維持全速效能,CPU必須能夠使用內部快取所提供的指令與資料,藉以避免必須存取外部記憶體。L1快取是系統中速度最快的記憶體,通常內建於CPU內部。有些CPU內部沒有內建快取,而是將外部高速靜態隨機存取記憶體(SRAM)與CPU緊密配置在一起,其運作速度接近CPU本身的速度。此外高速SRAM相當昂貴,因此通常必須分析價格與效能,並針對特定系統選擇最具成本效益的快取組態。
不幸的是,快取的容量通常不足以容納整組執行程式碼,因此CPU必須定期向外界存取指令與資料。當CPU被迫存取外部資料時,PLB的速度(例如,CPU與其它元件互傳資料時所經過的通道)與主記憶體子系統的效能將成為關鍵的系統瓶頸。
處理器區域匯流排 (Processor Local Bus)
取捨因素:PLB 速度 v.s. 頻寬
PLB是直接串連至CPU的資料通道,也是系統中最快的平行匯流排。在PLB與所有區域週邊元件連線時,CPU在全速運行的情形下是最理想的狀況。然而,CPU外部的高速匯流排受到許多因素所限制。印刷電路板(PCB)配置因為線路數量龐大(32至64資料位元,約等於位址位元的數量)導致其結構極為複雜。業界用來支援高頻訊號路由器的技術會增加機板開發流程的時間與費用,另外串音(Crosstalk)與非預期的振幅偏移是眾多訊號完整性問題中與複雜線路配置有關的因素。這些因素通常導致需在PLB的速度與頻寬上做取捨。
主記憶體子系統
取捨因素:SRAM v.s. SDR SDRAM v.s. DDR SDRAM
系統流量受到記憶體向高速CPU傳送資料的速度有所影響。在嵌入型系統中,L1快取旁的記憶體通道(bank)通常就是主記憶體通道。記憶體技術持續演進,目標就是希望能跟上高速處理器的腳步。目前SRAM是速度更快、密度更低,且比DRAM更昂貴的記憶體。因此,SRAM的應用一般僅限於快取應用系統。而主記憶體通則常採用DRAM。
嵌入型系統記憶體已逐漸從快速頁面模式(Fast Page Mode;FPM)與Extended Data Out (EDO) DRAM 轉移至Single Data Rate(SDR)、同步DRAM (SDRAM) 以及Double Data Rate (DDR) SDRAM。最近發展的新趨勢則是Quad Data Rate以及其它創新的記憶體技術。
I/O 子系統互動
電腦系統並非完全獨立,必須與其它系統透過I/O控制器相互傳送資料,因此CPU必須進行額外的晶片外部(off-chip)存取動作。I/O週邊元件通常是透過一組PLB進行存取,PLB則串連至其它標準匯流排橋接元件。I/O控制器配備一組嵌入型介面,經由這套介面串連至標準匯流排,而不是透過一套特定的CPU匯流排介面。因此處理器的區域匯流排必須運用一組橋接元件轉譯成標準匯流排的格式。
I/O 週邊元件的運作亦需要存取PLB上的元件(透過橋接器),若CPU需要存取PLB而I/O控制器也正在使用PLB時,CPU就必須等待,同時亦可能延遲指令的執行。I/O控制器通常負責串連至嵌入型系統以外的裝置,例如像位於圖一中較低層的磁碟陣列以及磁帶子系統。
軟體
軟體以虛擬化嵌入型系統最佳化與模式(pattern)的方式影響其效能表現(例如,精簡性 - 更小、更緊密的程式碼會耗用較少的記憶體)。模式(pattern)則是表示系統會執行圖一中那些架構部份以及耗用的時間比率。
軟體的影響關鍵在於CPU能否充份運用所有MIPS效能。若程式碼能配合CPU晶片內部的快取容量,則CPU就能在MIPS全速下運作,在這種情況下,CPU的MIPS效能就成為最重要的因素。但大多數的狀況,所有程式碼並不能完全置入快取記憶體。以下我們將針對一套小型系統的記憶體選擇進行探討。
嵌入型系統範例
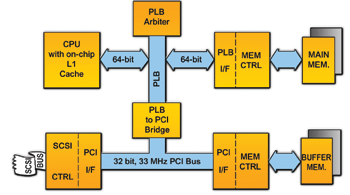
(圖二)顯示一個含有晶片內快取的小型嵌入型系統圖。現代的嵌入型CPU內建的快取容量從8KB至32KB不等。底層的程式碼核心若落在8KB的範圍內,則對效能的助益就較不顯著,但RTOS即時作業系統的核心就可能耗用64KB至數megabytes的記憶體。應用軟體相關的程式碼則不包括在這些數字中。
典型的8KB核心會填入8KB的快取。在啟動後,當核心被執行時就會逐步被置入快取中。當核心完成系統啟動作業時應用軟體的程式碼就會被啟動,而快取也會被填滿。若程式碼呼叫外常態形式(routine),核心會被快取置出,將空間騰出給應用程式使用,反之亦然。
快取置換(Cache thrashing )會發生在當某個經常被使用的位址被另一個經常使用的位址所取代之時。每當CPU在快取中找不到所需的資料時,就必須以較低的主記憶體速度執行主記憶體作業週期。因此,CPU的效能就會因等待快取資料而減緩。容量較大的快取能儲存更多的資料,減低CPU存取外部記憶體的頻率。簡單的說,快取容量愈大、CPU的效能就愈高,但更大的快取須耗費更多的成本。
主記憶體
有關主記憶體的第一個選擇就是決定使用靜態隨機存取記憶體(SRAM)或是動態隨機存取記憶體(DRAM)。同步靜態隨機存取記憶體( Synchronous SRAM)相當快速且昂貴。一般而言,系統需要的記憶體數量相當大,因此SRAM會因成本過高而不適用。此外,包括消耗功率以及較低的密度(比DRAM耗用更多的電路板空間),也是SRAM不適用為主記憶體的原因。在眾多理由之下,DRAM成為許多嵌入型系統設計的最佳記憶體技術。
DRAM 主記憶體
在決定使用DRAM之後,設計人員面臨許多DRAM選項:SDR、DDR、或其它較少見的技術。同步DRAM(SDRAM)元件有單資料傳輸率(Single Data Rate; SDR)SDRAM以及雙倍資料傳輸率(Double Date Rate; DDR)SDRAM兩種類型。在DDR SDRAM中,新資料的供應發生於時脈的上升(rising)與下落(falling)兩端。SDR SDRAM提供是143 MHz的時脈,有些DDR元件支援這個時脈,同時能在286 MHz的速度下傳輸資料。
記憶體效能
DRAMS有分頁開啟、行位址控制器延遲時間(Column-address strobe; CAS)、以及隨後產生的列位置信號延遲(Row-addess strobe; RAS)等問題,其中的CAS會降低有效資料傳輸率,同時記憶體控制器也會增加延遲的程度。
SDR SDRAM
現代的SDR SDRAM的時脈通常達143MHz,須耗用3個時脈延遲來開啟一個分頁,來進行讀或寫的作業。在相容的分頁中(例如RAS延遲已經產生),會產生另一個 3 CAS的延遲(CAS Latency of Three)。這代表快衝(burst)資料的傳輸率達143 MHz,但快衝的第一組資料會延遲三個時脈週期(在接收讀或寫指令之後)。在同一分頁的一組4字元快衝,則需6個時脈週期讓平均資料傳輸率從143 megabits (Mb/s)降低至(對於一組 x8 元件) 95 Mb/s,若分頁產生變動則會加入一組3時脈的分頁而延遲開啟。
DDR SDRAM
為提昇效能,主記憶體通道(bank)可從SDR轉變為DDR SDRAM。這些元件須經過約3個時脈延遲才能開啟一個分頁進行讀或寫的作業。一個典型的 "8M x 8 M" - 等級7的元件,CAS延遲為2.5,時脈為143MHz。這組DDR元件在143MHz時脈的兩個端點都能傳輸資料,故其快衝傳輸率為286 Mb/s。前端(up-front)的2.5 CAS延遲讓傳輸率比前者較低。在相同的分頁中,對於一組4字元的快衝作業,需耗用9個時脈週期,讓平均資料傳輸率從286 Mb/s 降低至127 Mb/s 。若分頁產生變動,就會增加一組為期3個時脈的分頁啟始延遲。
結論
系統效能與應用種類有直接的關係。在本文中,我們分析一套嵌入型系統範例,顯示CPU時脈在經歷不同的頻率範圍時,系統效能在多處會上揚至高峰點。PLB與記憶體子系統的各種特性會在不同的CPU速度產生不明顯的效能高峰。這些結果證明極高速且昂貴的處理器,其MIPS效能無法永遠充份運用。妥善搭配處理器與元件的效能,能在成本與效能之間取得最佳的平衡點。
(作者任職於Xilinx)