本文描述設計MCU和ADC之間的高速串列周邊介面(SPI)關於數據交易處理驅動程式的流程,並介紹優化SPI驅動程式的不同方法及其ADC與MCU配置等,以及展示在不同MCU中使用相同驅動程式時ADC的吞吐率。
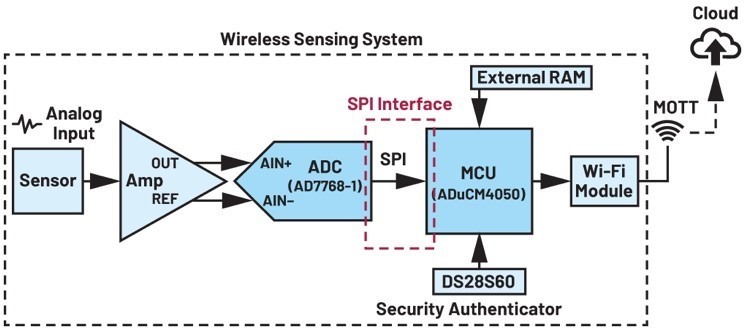
隨著技術的進步,低功耗物聯網(IoT)和邊緣/雲端運算需要更精準的數據傳輸。圖1展示的無線監測系統是一個具有24位元類比數位轉換器(ADC)的高精度數據擷取系統。在此我們通常會遇到的問題,即微控制單元(MCU)能否為數據轉換器提供高速的序列介面。
本文描述了設計MCU和ADC之間的高速串列周邊介面(SPI)關於數據交易處理驅動程式的流程,並介紹優化SPI驅動程式的不同方法及其ADC與MCU配置,以及SPI和直接記憶體存取(DMA)關於數據交易處理的示例代碼,最後展示在不同MCU中使用相同驅動程式時ADC的吞吐率。
通用SPI驅動程式簡介
通常,MCU廠商會在常式代碼中提供通用的SPI驅動程式/API。通用SPI驅動程式/API通常可以涵蓋大多數用戶的應用,這些代碼可能包含許多配置或判斷語句。
然而在某些特定情況下,例如ADC資料擷取,通用的SPI驅動程式可能無法滿足ADC數據的全速的吞吐率需求,因為通用的驅動程式中有過多的配置,而未使用的配置會產生額外的開銷並導致時間延遲。
設計思路與實踐架構
我們通常會選擇低功耗高性能的MCU作為主機透過SPI擷取ADC的輸出數據。但是,由於ADI的SPI驅動程式的數據交易處理命令存在冗餘,因此數據輸出速率可能被明顯降低。
為了充分釋放ADC的潛在速率,本文使用ADuCM4050和AD7768-1進行實驗並嘗試可能的解決方案。儘管在使用預設濾波器的情況下,ADuCM4050的最大數據輸出速率可達256 kHz,但在目前的情況下,其速率被限制在8 kHz。提高輸出速率的潛在解決方案包括刪除不必要的命令以及啟動DMA控制器。以下將介紹這些思路。
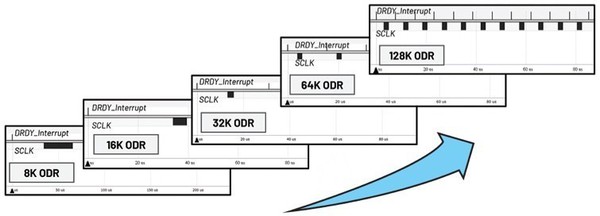
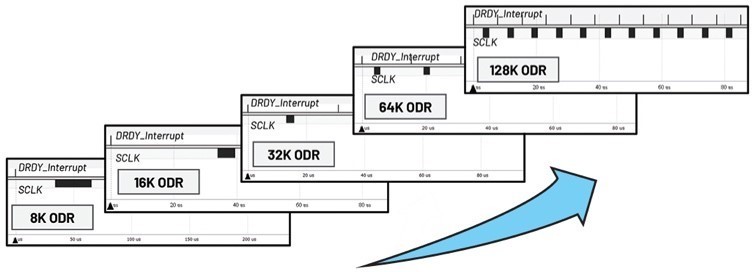
| 圖3 : 不同ODR以及DRDY與SCLK之間的關係 |
|
以MCU作為主機
ADuCM4050 MCU為一款主時脈速率為26 MHz的超低功耗微控制器,核心為ARMR CortexR-M4F處理器。ADuCM4050配有三個SPI,每個SPI都有兩個DMA通道(接收和發射通道)可與DMA控制器連接。DMA控制器和DMA通道可實現記憶體與周邊之間的數據傳輸。這是一種高效的數據分配方法,可將核心釋放以處理其他任務。
以ADC作為從機
AD7768-1為一款24位元低功耗、高性能的Σ-Δ ADC。其數據輸出速率(ODR)和功耗模式均可根據使用者的要求進行配置。ODR由抽取係數和功耗模式共同決定,如表1中所示。
(表1)數據輸出速率的功耗模式配置
|
功耗模式
|
抽取係數
|
OOR
|
|
快速功耗(MCLK/2)
|
×32
|
256 kHz
|
|
快速功耗(MCLK/2)
|
×64
|
128 kHz
|
|
中速功耗(MCLK/4)
|
×32
|
128 kHz
|
|
中速功耗(MCLK/4)
|
×64
|
64 kHz
|
|
低速功耗(MCLK/16)
|
×32
|
32 kHz
|
|
低速功耗(MCLK/16)
|
×64
|
16 kHz
|
AD7768-1的連續讀取模式也是該產品的一個重要特性。ADC的輸出數據儲存在暫存器0x6C中。一般而言,每次讀/寫操作之前,ADC暫存器中的數據都需要位址才可以存取,但是連續讀取模式則支援在收到每個數據就緒訊號後直接從0x6C暫存器提取數據。ADC的輸出數據為24位元的數位訊號,對應的電壓如表2所示。
(表2)數位輸出碼和類比輸入電壓
|
說明
|
類比輸出電壓
|
數位輸出碼
|
|
+全擺幅–1 LSB
|
+4.095999512 V
|
0x7FFFFF
|
|
中間位準+1 LSB
|
+488 nV
|
0x000001
|
|
中間位準
|
0 V
|
0x000000
|
|
中間位準-1 LSB
|
–488 nV
|
0xFFFFFF
|
|
-全擺幅–1 LSB
|
–4.095999512 V
|
0x800001
|
|
-全擺幅
|
+4.096 V
|
0x800000
|
接腳連接示意圖
ADuCM4050和AD7768-1組成的數據交易處理示例模型的接腳連接狀況,如圖4所示。
ADC的重設訊號接腳RST_1連接至MCU的GPIO28,而數據就緒訊號接腳DRDY_1則連接至MCU的GPIO27。其餘接腳則根據通用的SPI配置標準進行連接,其中MCU為主機,而ADC為從機。SDI_1接收MCU發送的ADC暫存器讀/寫命令,而DOUT_1則將ADC的輸出數據發送至MCU。
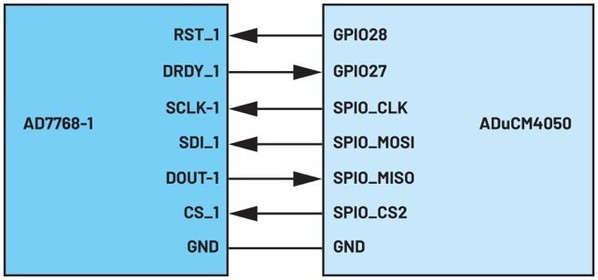
| 圖4 : AD7768-1和ADuCM4050的介面接腳連接 |
|
數據交易處理的實現
中斷數據交易處理
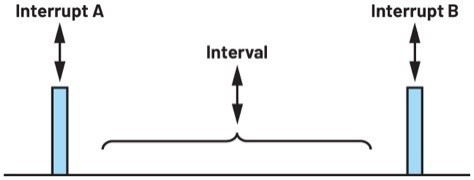
為實現連續數據交易處理,本文將MCU的GPIO27接腳(連接至ADC的DRDY_1接腳)用於中斷觸發接腳。ADC將數據就緒訊號發送至GPIO27時會觸發MCU包含數據交易處理命令的中斷回呼函數。如圖5所示,數據擷取必須在中斷A和中斷B之間的時間間隔內進行。
利用ADI的SPI驅動程式可以在ADC和MCU之間輕鬆實現數據交易處理。但是,由於驅動程式記憶體在冗餘命令,ADC的ODR會被限制在8 kHz。本文盡可能精簡了代碼以加快ODR,將介紹實現DMA數據交易處理的兩種方法:基本模式的DMA交易處理和乒乓模式的DMA交易處理。
基本模式的DMA交易處理
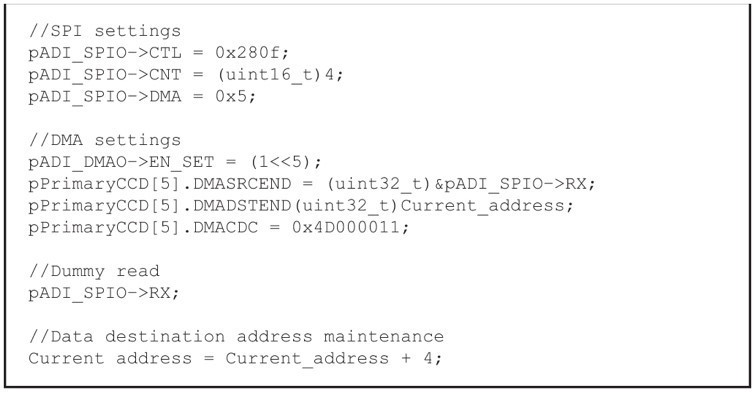
在實現每個DMA交易處理之前需要對SPI和DMA進行配置(參見圖6中的示例代碼)。SPI_CTL為SPI配置,其值為0x280f,源於ADI的SPI驅動程式的設定值。SPI_CNT為傳輸位元組數。
由於每個DMA交易處理只能發送固定的16位元數據,因此SPI_CNT必須是2的倍數。本例設定SPI_CNT為4,以滿足ADC的24位元輸出數據要求。SPI_DMA暫存器為SPI的DMA致能暫存器,設定其值為0x5以使能DMA接收請求。命令pADI_DMA0->EN_SET=(1<<5)致能第五個通道的DMA,即SPI0 RX。
(表3)DMA結構暫存器
|
名稱
|
說明
|
|
SRC_END_PTR
|
來源端指針
|
|
DST_END_PTR
|
目標端指標
|
|
CHNL_CFG
|
控制數據配置
|
每個DMA通道都有一個DMA結構暫存器,如表3中所示。需要指出的是,這裡的數據來源位址的結尾(即SPI0 Rx,亦即來源端指標SRC_END_PTR)在整個操作期間無需增加,因為Rx FIFO會自動將暫存器中的數據推送出去。另一方面,數據目標位址的結尾(即目標端指標DST_END_PTR)根據ADI的SPI驅動程式的使用函數計算得出,即目標位址+ SPI_CNT -2。
目前位址為內部陣列緩衝區的位址。DMA控制數據配置CHNL_CFG包括來來源數據大小、來源位址增量、目標位址增量、剩餘傳輸次數和DMA控制模式等設定,其值0x4D000011按照表4中所述的設定配置。
(表4)控制數據配置0x4D00011的DMA配置
|
暫存器
|
說明
|
值
|
|
DST_INC
|
目標位址增量
|
2位元組
|
|
SRC_INC
|
來源地址增量
|
0
|
|
SRC_SIZE
|
來源地址增量
|
2位元組
|
|
N_minus_1
|
目前DMS週期中的
總傳輸次數- 1
|
1 (N = 2)
|
|
Cycle_ctrl
|
DMA週期的工作模式
|
基本模式
|
SCLK時脈透過偽讀取命令SPI_SPI0 -> RX啟動,輸出數據透過MISO從ADC傳至MCU。MOSI上其它的數據傳輸可以忽略不計。一旦完成Rx的FIFO填充,DMA請求就會產生進而啟動DMA控制器,以將數據從DMA來源位址(即SPI0 Rx FIFO)傳輸至DMA目標位址(即內部陣列的緩衝區)。值得注意的是,SPI_DMA=0x3時會產生Tc請求。
最後,透過將目前目標位址加4的方式,將目標位址用於下一個4位元組的傳輸。
請注意,SPI0 DMA通道的pADI_DMA0->DSTADDR_CLR和pADI_DMA0->RMSK_CLR必須在首次中斷觸發之前在主函數中設定。前一個為DMA通道目標位址減量致能清零暫存器,用於在增量模式下設定每次DMA傳輸後的目標位址移位(目標位址計算函數僅在增量模式下有效)。後一個為DMA通道請求遮罩清零暫存器,用於將通道的DMA請求狀態清零。
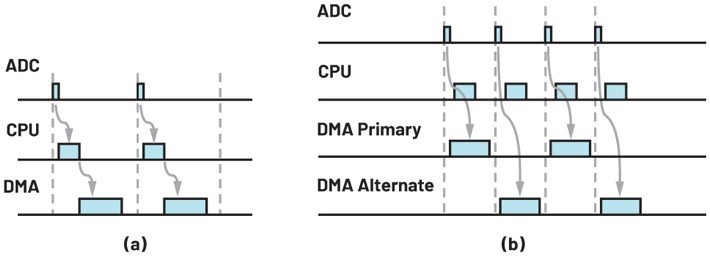
基本模式的DMA交易處理時間圖如圖7a所示。圖中三個時隙分別代表DRDY訊號、SPI/DMA設定和DMA數據交易處理。在該模式中,CPU的閒置時間較多,因此希望DMA控制器在處理數據傳輸時能將任務分配給CPU。
乒乓模式的DMA交易處理
在執行偽讀取命令後,DMA控制器會開始數據交易處理,進而使得MCU的CPU處於空閒狀態,而不處理任何任務。如果能夠讓CPU和DMA控制器同時工作,那麼任務處理就從串列模式轉變為並行模式。如此就可以同時進行DMA配置(透過CPU)以及DMA數據交易處理(透過DMA控制器)。
為實現這一思路,需要設定DMA控制器處於乒乓模式。乒乓模式將兩組DMA結構進行了整合:主結構和備用結構。每次DMA請求時,DMA控制器會在兩組結構之間自動切換。變數p的初始設定為0,其值表示是主DMA結構(p = 0)還是備用DMA結構(p = 1)負責數據交易處理。
如果p = 0,則在收到偽讀取命令時啟動主DMA結構進行數據交易處理,同時會為備用DMA結構分配值,使其在下一個中斷週期內負責數據交易處理。如果p = 1,則主結構和備用結構的作用互換。當僅有主結構處於基本DMA模式時,在DMA交易處理期間對DMA結構的修改會失敗。乒乓模式使得CPU能夠存取和寫入備用DMA結構,而DMA控制器可以讀取主結構,反之亦然。
如圖7b所示,由於DMA的結構配置是在最後一個週期內完成的,因此在DRDY訊號從ADC傳送至MCU後DMA數據交易處理可以被立即執行,使得CPU和DMA同時工作而無需等待。現在,ADC的ODR得到了提升空間,因為整體工作時間已大幅縮短。
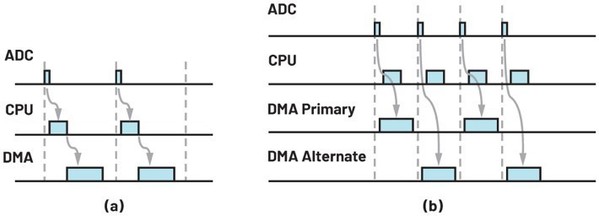
| 圖7 : (a)基本模式DMA和(b)乒乓模式的時間圖 |
|
中斷處理常式的優化
兩次DRDY訊號之間的時間間隔不僅包括了中斷回呼函數的命令執行時間,還包括了ADI的GPIO中斷處理函數的命令執行時間。
當MCU啟動時,CPU會運行開機檔案(即startup.s)。所有事件的處理函數均在該檔中定義,包括GPIO中斷處理函數。一旦觸發GPIO中斷,CPU就會執行中斷處理函數(即ADI的GPIO驅動程式中的GPIO_A_INT_HANDLER和GPIO_B_INT_HANDLER)。通用的中斷處理函數會在所有的GPIO接腳中搜索觸發中斷的接腳並清零其中斷狀態、運行回呼函數。
由於DRDY是本文應用的唯一中斷訊號,因此可以對函數進行簡化以加快進程。可選的解決方案包括:(1)在開機檔案中重新定位目標;(2)修改原始的中斷處理函數。重新定位目標表示自訂中斷處理函數,並替換開機檔案中的原始的中斷處理函數。
而修改原始的中斷處理函數只需要增加一個自訂的GPIO驅動程式。本文採用第二種方案修改原始的中斷處理函數,如圖8所示。該方案只將連接至DRDY的GPIO的接腳中斷狀態清零,並直接轉到回呼函數。請注意,這裡需要透過取消選擇build target中關於原始GPIO驅動函數的勾選框內容來隔離原始的GPIO驅動程式。
結果
速率性能
假定現在需要讀取200個24位元的ADC輸出數據,並且SPI位元速率設定為13 MHz。將DRDY訊號和SCLK訊號的接腳連接至示波器,則能透過觀察DRDY訊號與SPI數據交易處理(亦即DMA交易處理)啟動之間的時間間隔方法,量化本文所述的每種方法對速率的改善程度。這裡將DRDY訊號至SCLK訊號開始的時間間隔記為?t,那麼對於13 MHz的SPI速率,測量得出的?t為:
‧ (a)基本模式DMA Δt = 3.754 μs
‧ (b)乒乓模式DMA Δt = 2.8433 μs
‧ (c)乒乓模式DMA(使用優化的中斷處理函數)Δt = 1.694 μs
方法(a)和(b)可支援64 kHz的ODR,而方法(c)可支援128 kHz的ODR。這是因為方法(c)的?t最短,進而使得SCLK訊號能夠更早結束。如果SCLK訊號(即數據交易處理)能在T/2之前完成(T為目前ADC的數據輸出週期),則ODR可實現翻倍。這相對於原始的ADISPI驅動程式可以達到的8 kHz的ODR性能是一次巨大的進步。
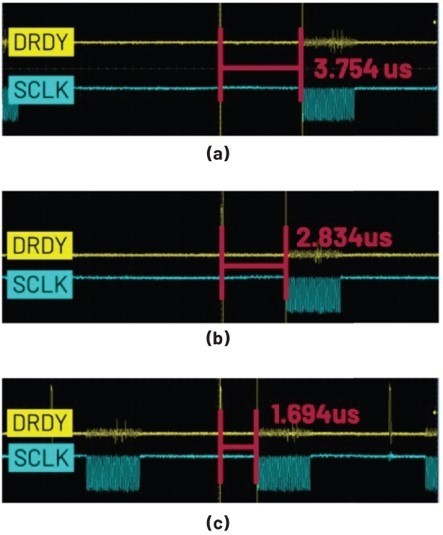
| 圖9 : (a)基本模式DMA、(b)乒乓模式,以及(c)乒乓模式(使用優化的中斷處理函數)的Δt |
|
使用MAX32660控制AD7768-1
使用主時脈速率為96 MHz的MCU MAX32660控制AD7768-1)時的結果如何?在該情況下,使用優化的中斷處理函數的中斷設定,可在不使用DMA函數的情況下實現256 kHz的數據輸出速率。參見圖10。
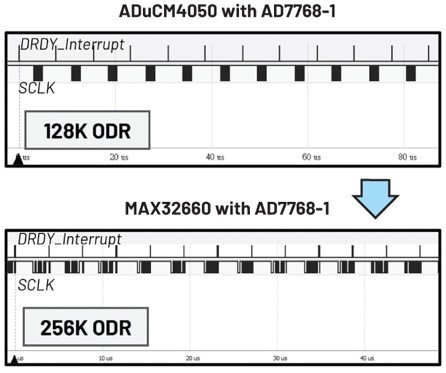
| 圖10 : 不使用DMA時MAX32660的ODR |
|
結論
本文利用選定的ADC(AD7768-1)和MCU(ADuCM4050或MAX32660)透過SPI實現了高速的數據交易處理。為實現速率優化的目標,本文簡化ADI的SPI驅動程式執行數據交易處理;此外,並提出啟動DMA控制器釋放核心,也可加快連續數據交易處理的流程。
在DMA的乒乓模式下,DMA的配置時間可透過適當的調度來節省。在此基礎上,還可透過直接指定中斷接腳的方式優化中斷處理函數。在13 MHz的SPI位元速率下,本文提出之方案的最佳性能可達到128 kSPS的ADC ODR。
(表5) 高速SPI連接實現ADuCM405和MAX32660
|
?
|
ADuCM4050(MCU)
|
MAX32660(MCU)
|
|
數據交易處理
|
未經優化的中斷
|
基本模式DMA
|
乒乓模式DMA
|
經優化的中斷
|
經優化的中斷
|
|
匯流排類型
|
SPI
|
SPI
|
SPI
|
SPI
|
SPI
|
|
主時脈速率
|
26 MHz
|
26 MHz
|
26 MHz
|
26 MHz
|
96 MHz
|
|
DRDY與SCLK
之間的時間間隔
|
6.34 μs
|
3.754 μs
|
2.834 μs
|
1.694 μs
|
1.464 μs
|
|
數據輸出速率
|
8 kSPS
|
32 kSPS
|
64 kSPS
|
128 kSPS
|
256 kSPS
|
(本文作者Denny Wang、Sally Tseng為ADI應用工程師)