先進處理能力和機器學習能力對於下一波邊緣應用至關重要。機器學習演示場景在不同的市場和應用領域大不相同,因而需要不同的加速運算性能,在功耗和整體解決方案成本方面也差別迥異。

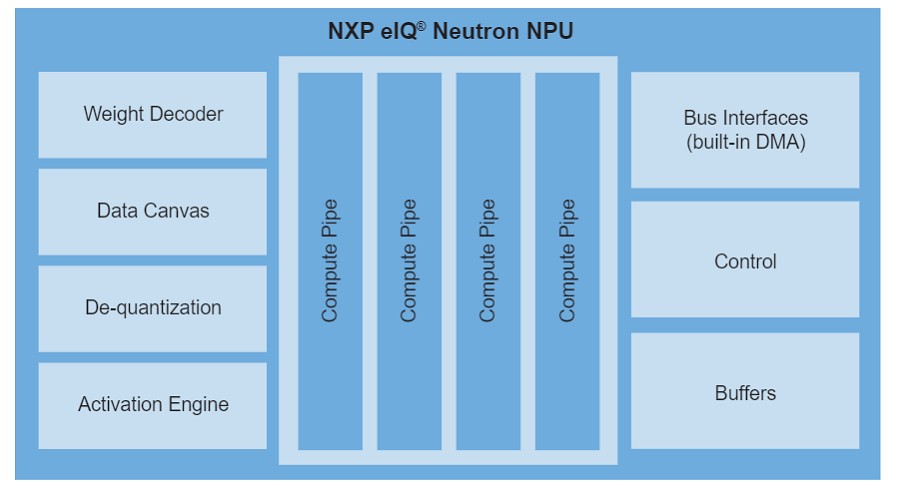
| 圖一 : 高度可擴展、分區和高能效的機器學習加速器內核架構。 |
|
機器學習應用提升運算性能和效能可通過多種方式,其中最有效的是將專門構建的專用神經處理單元(NPU),或稱為機器學習加速器(MLA)或深度學習加速器(DLA)整合到器件中,以補充CPU運算核心。
恩智浦提供廣泛的產品組合,從傳統的Kinetis MCU、LPC系列以及最近的MCX產品系列,到i.MX RT跨界MCU和i.MX應用處理器,我們服務的每一個市場領域,對高效的機器學習運算能力的需求都在增長。為了提供給客戶
高度優化的器件,我們開發了eIQ Neutron神經處理單元(NPU)。eIQ Neutron神經處理單元架構,可從我們產品組合中最高效的MCU擴展到功能最強大的i.MX應用處理器。它具有較高的可擴展性,每週期運算頻次為數十億(Giga)到數萬億(Tera),還支援多種神經網路類型(如CNN、RNN、TCN和Transformer網路等),這些要素是成功的秘訣。
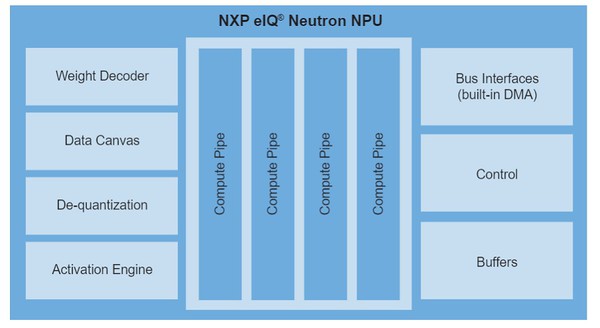
| 圖二 : eIQ Neutron神經處理單元架構圖 |
|
eIQ Neutron神經處理單元提供豐富的選項,使用者可根據內核整合的恩智浦邊緣處理器件和產品系列要滿足的市場需求加以選擇。
‧ 專用的控制器內核
‧ 內聯去量化、啟動和池化
‧ 內置微緩存,可降低功耗並減少對系統記憶體速度的依賴性
‧ 重量減壓引擎
‧ 用於輸入和輸出的多維DMA,包括跨步、批次處理、交織、級聯
‧ 可配置耦合記憶體
除硬體功能和特性外,eIQ Neutron神經處理單元內核還完全受eIQ機器學習軟體發展環境的支持。
將恩智浦開發的硬體加速和軟體支援相結合,使用者能夠利用恩智浦邊緣處理產品組合的優勢,並保證即使在部署了設備並投入實地使用之後,也能更高效地支援新興機器學習神經網路、模型和操作員。
(本文作者Ali Ors為恩智浦半導體邊緣處理AI機器學習戰略技術主管)