如果嵌入式處理器供應商沒有合適的工具和軟體,設計節能的邊緣人工智慧 (AI) 系統,同時加快上市時間可能會變得窒礙難行。挑戰包括選擇正確的深度學習模型、訓練和優化模型以實現性能和準確度目標,以及學習用於在嵌入式邊緣處理器上部署模型的專有工具。
從模型選擇到處理器部署,TI 提供免費工具、軟體和服務,協助完成深度神經網路 (DNN) 開發工作流程的每一個步驟。逐步選擇模型、隨處訓練模型,並無縫部署到 TI 處理器上,完全不需要任何手工製作或手動程式設計,藉以進行軟體加速推論。
步驟 1:選擇模型
邊緣 AI 系統開發的首要任務是選擇正確的 DNN 模型,同時考慮系統的性能、準確度和功率目標。和 GitHub 上的 TI 邊緣 AI 模型庫等工具有助於您加速這個過程。
這個模型庫是 TensorFlow、PyTorch 和 MXNet 框架常用開放原始碼深度學習模型的大型集合。這些模型在公共資料集上進行預先訓練,並經過優化,可在 TI 處理器上有效運作而實現邊緣 AI。TI 會定期使用來自開放原始碼社群的最新模型以及 TI 設計的模型更新模型庫,提供最多樣化的性能和精準的優化模型。
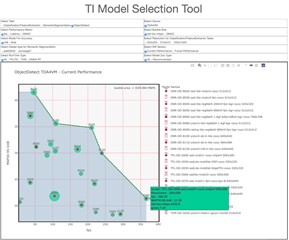
藉由模型庫中的數百個模型,TI 模型選擇工具 (如圖一所示) 可以協助快速檢視和比較推論處理量、延遲、準確度和雙倍資料速率頻寬,完全不需要撰寫任何程式碼。
步驟 2:訓練和調整模型
選擇模型後,下一個步驟是訓練或優化模型,藉以在 TI 處理器上實現最佳性能和準確度。運用我們的軟體架構和開發環境可以隨處訓練模型。
從 TI 模型庫中選擇模型時,訓練腳本可以根據特定任務的自訂資料集快速傳輸和訓練模型,完全不需要從頭開始進行長時間的訓練或手工製作模型。對於自己的 DNN 模型,訓練腳本、框架擴展和量化感知訓練工具有助於優化模型。
步驟 3:評估模型性能
在開發邊緣 AI 應用之前,需要在實際軟體上評估模型性能。
使用 TensorFlow Lite、ONNX RunTime 或 TVM 以及 SageMaker Neo with Neo AI DLR 執行階段引擎的最常用業界標準 Python 或 C++ 應用程式設計介面 (API),只需要幾行程式碼,TI 的彈性軟體架構和開發環境即可隨處訓練自己的模型,並且編譯模型再部署到 TI 硬體。在這些業界標準執行階段引擎的後端, TI 深度學習 (TIDL) 模型編譯和執行階段工具可以為 TI 軟體編譯模型、將編譯後的圖形或子圖形部署到深度學習軟體加速器上,並獲得最佳化推論處理器的性能,完全不需要任何手動操作。
在編譯步驟中,訓練後量化工具可以將浮點模型自動轉換為定點模型。這組工具透過配置檔進行層級混合精度量化 (8 位元和 16 位元),達到調整模型編譯的絕佳彈性,藉以展現最佳性能和準確度。
各種常用模型的操作不盡相同。TI 邊緣 AI 基準測試工具 也位於 GitHub 上,有助於您將 DNN 模型功能與 TI 模型庫中的模型無縫搭配,並做為自訂模型的參考。
有兩種方法可以在 TI 處理器上評估模型性能:TDA4VM 入門套件評估模組 (EVM) 或TI Edge AI Cloud,這是免費的線上服務,支援遠端存取 TDA4VM EVM 評估深度學習推論性能。用於不同任務和執行階段引擎組合的多個範例腳本可以在不到五分鐘的時間內在 TI 軟體上進行加速推論的程式設計、部署和執行,同時收集基準。
@中標:步驟 4:開發邊緣 AI 應用
使用開放原始碼 Linux 和業界標準 API能夠將模型部署到 TI 軟體上。不過,將深度學習模型部署到軟體加速器上只是其中的一部分。
為了協助快速建構高效率的邊緣 AI 應用,TI 採用 GStreamer 框架。GStreamer 外掛程式可以將計算密集型任務的端對端訊號鏈自動加速到軟體加速器和數位訊號處理核心上。
圖二 顯示邊緣 AI 的 Processor SDK with Linux 有關的軟體堆疊和元件。
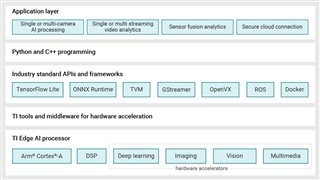
| 圖二 : 邊緣 AI 的 Processor SDK with Linux 元件 |
|
結論
即使不是 AI 專家,亦可開發和部署 AI 模型或建構 AI 應用。TI Edge AI Academy有助於在進行測驗的自定進度課堂式環境中學習 AI 基礎知識,並瞭解 AI 系統和軟體程式設計。實驗室提供建構「Hello, World」人工智慧應用的逐步程式碼,而具有攝影機拍攝和顯示的端對端進階應用程式,可按照自己的步調成功開發人工智慧應用。
(本文作者Manisha Agrawal任職於德州儀器)