太魯閣號列車出軌事故,除顯工地管理不良的嚴重問題外,也不禁讓人想問,難道沒法透過「科技」來及早預警,讓司機或自動控制系統緊急剎車,避免悲劇的發生嗎?
今年4月2日,台鐵發生70多年來死傷最慘重的太魯閣號列車出軌事故。一台工程車失控滑落邊坡並進入軌道中,導致台鐵408次列車太魯閣號閃避不及、高速撞上工程車後,釀成49死200多傷的悲劇。這事件除了凸顯工地管理不良的嚴重問題外,也不禁讓人想問,難道沒法透過「科技」來及早預警,讓司機或自動控制系統緊急剎車,避免悲劇的發生呢?
根據專家對此事件的研究指出,事故路段限速130公里,煞車需600公尺,煞停時間估計需16.6秒,但由於工程車是掉落在兩個隧道之間,司機從看到障礙物到反應的時間恐怕不到6.9秒,很顯然無法靠目視來剎停的。也就是說,台鐵列車只要經過此路段都處在不可控的風險中,而全台灣又有多少穿山越嶺的路段存在這樣的風險呢?
自動化監測AI預警系統
事實上,台鐵在108年3月完成台灣鐵道全線的邊坡調查及分級,針對落石、土石流高風險路段以工程改善方式為主,經評估後難以工程手段改善者,將架設「自動化監測AI預警系統」。
台鐵表示,這套預警系統是使用畫面監控加上AI判讀,直接監視軌道、邊坡,若有障礙物滑落軌道或有異物(行人、動物)進入監控畫面,且超過一定大小並維持一定時間,AI就會認定有風險,這時台鐵中控中心會發送軌道異物警訊給前後列車駕駛室的司機員,並在至少800公尺外開始發出警告聲,司機員也能看到警告燈號。當司機員一直無適當處置時,列車自動控制系統甚至會自行啟動剎車,讓車速歸零。此警訊同時也會送給鄰近列車,給相關人員更多反應時間。
很顯然地,這是一套關鍵任務系統,此系統有幾個關鍵技術,包括視訊監控(Video Surveillance)系統、AI影像辨識、警報系統,以及列車自動控制(Automatic Train Control, ATC)系統等,以及系統與系統間的低延遲通訊方式。本文將探討最前端的視訊監控與AI影像辨識技術。
先來看看視訊監控這一部分。視訊監控系統應用已久,傳統作法是用攝影機拍下來,再錄到錄影機中,有事件時才調「錄影帶」來回播追查可疑畫面,相當沒有效率,也無法提供即時警報。近來監視器已開始導入電腦視覺、人工智慧辨識技術,可進一步即時偵測、辨識和追蹤物件,也演進為所謂的智慧型視訊監控(Intelligent Video Surveillance, IVS)系統。
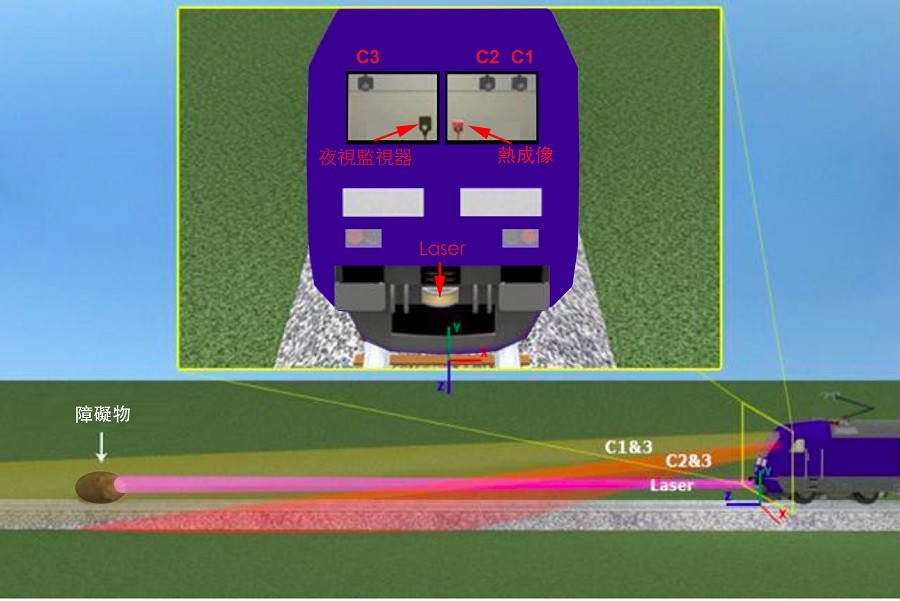
將智慧科技導入到列車的安全系統中已是大勢所趨,但由於列車行駛的情境特殊,對此監控系統的要求也不一樣,往往需要採用感測器融合(Sensor Fusion)的架構,也就是做為司機員的輔助「眼睛」,需在列車車頭的車窗上配置夜視攝影機(Night Vision Camera)、紅外線熱成像攝影機(Infrared Imaging Camera/Thermal Camera),以及2組立體視覺攝影機(Stereo Camera);並在車頭下方靠近鐵軌處配置雷射掃描器,以便在遠距離就發現障礙物並快速估算出距離。(圖1)
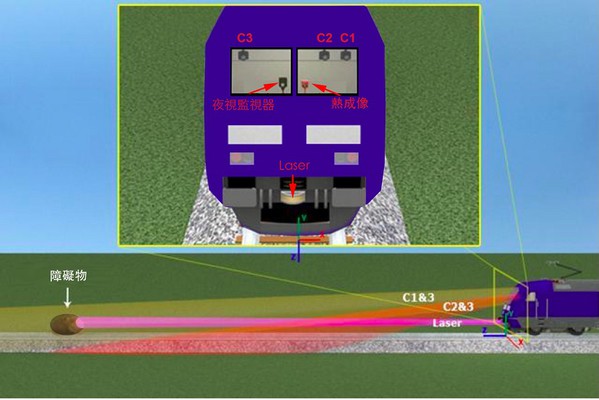
| 圖1 : 列車行駛的情境特殊,往往需要採用感測器融合的架構,也就是做為司機員的輔助「眼睛」。(source:Obstacle Detection System Requirements and Specification白皮書) |
|
至於建置在鐵道延線的AI監視系統,雖不像火車頭的監控系統那麼複雜,但由於需在各種不良氣候下(如下大雨、起霧、強光等)仍能拍攝到可分析的畫面,以免產生誤報而影響列車行駛及營運,對監視器的功能及可靠度都有非常高的要求。
AI準確關鍵:影像前處理
所謂「功欲善其事,必先利其器」,想將傳統的監控應用升級到AI級的影像應用,而且要達成精準的影像分析,影像前處理的「三步」基本工必須先做到位。這三步分別是採集(Capture)、錄影(Record)和串流(Stream)。
不論是列車上或鐵道兩旁架設的監視系統,除了要能支援多路影像的採集及不同錄影格式(如H.264、H.265)外,在此過程中也要同步處理這些影像資料,讓它帶有AI資料(AI Metadata),好讓分析時能快速找到重要片段,降低時間與人力。串流方面除了盡量降低影像傳遞延遲(如用5G)外,更重要的是採用分散式處理的架構,也就是能即使處理,有狀況立即反應。
表一:AI應用前的影像處理需求功能
|
影像處理
|
需求功能
|
|
Capture
|
|
|
Record
|
--支援H.264/H.265
--支援MPEG
|
|
Stream
|
- Edge to Cloud資料傳送
- 低延遲、即時Live View
|
|
AI
|
- 導入深度學習技術
- 數據、影像資料的Target Tag
- 進行正確的物件辨識
|
可行AI-based軟硬體監控方案
以監控攝影機來說,目前的運算力仍有限,難以即時分析拍攝到的畫面,因此在做了初步的影像處理後,還是得將影像串流送到運算力更強的裝置。一般一個區域會有個中控中心,將其週邊附近攝影機拍到的影像送到中心機房的Edge Server或Edge Computer進行影像分析。
對於鐵道運輸業來說,雖有國家經費來支持,但由於鐵路又長、車班又多,監視系統的佈建成本往往很嚇人,上述台鐵要做的邊坡預警系統雖編列了2.75億元經費,卻只能顧到25個地方。且不論這筆錢花的值不值得,若能降低硬體成本又得到加值的軟體功能與服務,可靠度也不打折,自然是鐵道業者樂於採用的。
目前有不少工業電腦廠商提供列車安全監控相關的軟硬體解決方案,他們普遍支援Intel及NVIDIA的邊緣運算技術,有的還支援Google Coral。限於篇幅,以下以Intel的平台為例,介紹一下如何將Edge AI影像辨識技術導入到鐵道安全當中。
在IVS的市場,Intel的市佔率一直很高,有很大的理由是因其運算硬體除了提供Intel CPU、GPU、VPU及FPGA等多核心平台外,也內建H.264與H.265硬體視訊編解碼功能,讓電腦視覺或影像AI的處理更有效率。
再看看Intel架構的視訊編解碼效能(CODEC Performance),以IntelR Tiger Lake-U CeleronR 6305處理器為例,可以很容易地處理單路4K60影像,即使四路4K30影像也不掉幀。而在Tiger Lake Core i7新一代運算平台上,更可以輕鬆處理到六路4K30,或是四路4K60的目標,也能滿足鐵道多路同步監視的需求。
軟體方面,Intel的OpenVINO Toolkit(Open Visual Inference & Neural Network Optimization Toolkit)能讓列車安全監控相關的工業電腦方案,很容易地具備AI影像辨識的功能。
OpenVINO這個開源平台的定位本來就是針對Edge AI的推論(Inference)運算而生,它所提供的模型優化器(Model Optimizer)功能,可將推論速度提升數十倍以上。優化後,產出二個IR(Intermediate Representation)檔案(*.bin, *.xml),再交給推論引擎(Inference Engine)依指定的加速硬體(CPU、GPU、FPGA、VPU)進行推論。
同時它也提供很多預訓練(Pre-trained)及優化好的神經網路模型,可供大家直接使用,而且是免費的。此舉讓不熟悉電腦視覺和深度學習原理的人也能很快上手,不必擔心如何建置開發平台、選擇深度學習框架、訓練及優化模型和硬體加速等問題,只需利用預訓練及優化過的模型,就能很快做出有模有樣的應用原型。
鐵道障礙物之AI影像辨識技術
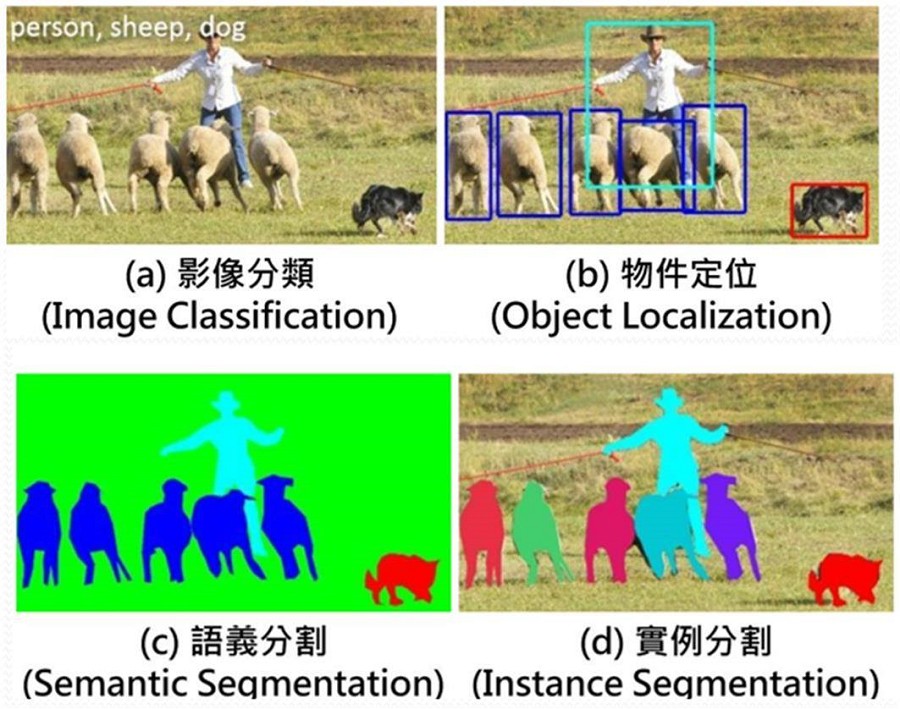
當然,說都不懂AI技術也能用好OpenVINO,有些誇張了,至少也要認識影像辨識的四大常見類型技術:1. 影像分類(Image Classification);2. 物件定位(Object Localization);3. 語義分割(Semantic Segmentation);4. 實例分割(Instance Segmentation)。以下來談談如何將這四類技術用於鐵道障礙物的辨識。
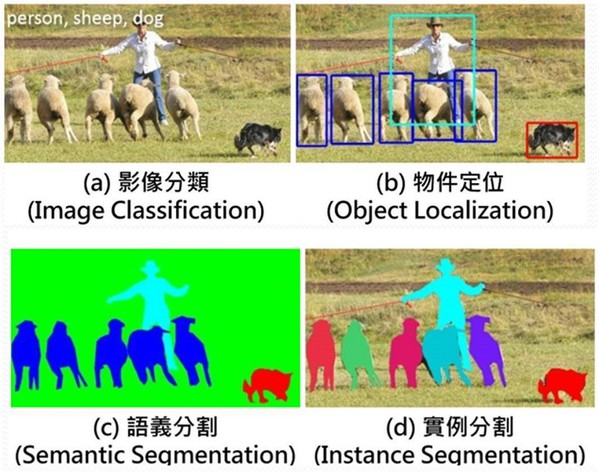
| 圖2 : 影像辨識的四大常見類型技術。(source:makerpro.cc) |
|
「影像分類」能做到的是辨識出有什麼東西出現在一張圖片中;「物件定位」則能進一步給辨識出的物件一個邊界框,進而取得其位置和尺寸,用途更大。由於鐵道的的場景較單純,透過「物件定位」技術就能找出列車、侵入的人或物、號誌位置,下圖即運用「物件定位」的技術來辨識出鐵道中出現的是一個人、多人、動物(馬匹)及列車靠近,並判斷出是否該發出警示。

| 圖3 : 影像分類」能做到的是辨識出有什麼東西出現在一張圖片中。(source: aip.scitation.org) |
|
但當場景較複雜(如平交道或月台)時,同一影像中物件數量很多,且邊界框重疊的情況很嚴重,用「物件定位」技術的辨識效果不佳,這時就需要用到「語義分割」及「實例分割」這兩種像素級的分類技術。
這兩類技術的差異在於「語義分割」只須分辨出物件類型但不區分個體,對於道路上的物件類型辨識來說,「語義分割」就很好用了,以OpenVINO的預訓練模型(semantic-segmentation-adas-0001)為例,此模型即可同時辨識出道路、車輛、路標、天空、植物、建物等多達20種類別的物件。

| 圖4 : 語義分割預訓練模型可針對道路、車輛、路標等物件類型進行辨識。(source:openvinotoolkit.org) |
|
不過,當需要更精準地分辨出每一個體(實例)是何物,並算出數量時,就得靠「實例分割」技術了。以OpenVINO的另一個預訓練模型(instance-segmentation-security-0002)來說,它是整合Mask R-CNN, Resnet 50、FPN、RPN 及 Microsoft COCO分類資料集所訓練完成的,模型參數就有近三千萬個。Microsoft COCO資料集在影像分割上共提供了 123,287 張影像, 886,284 個物件(實例),80 個分類,包括人、交通工具、街道物件、動物等,如圖5。

| 圖5 : 實列分割預訓練模型可針對道路、車輛、路標等個體進行辨識,本圖還能分辨出自行車、車上的人,以及人的背包。(source:openvinotoolkit.org) |
|
結論
本文僅針對如何將AI用於鐵道障疑物的影像辨識上,延伸的問題還很多,包括如何精準且快速的測距、如何排除誤判、如何進行極低延遲的通訊,以及如何設計有效的預警系統,甚至有權啟動ATC的剎車功能等等。
事實上,在自駕車的議題上,障礙物辨識與測距的研究已經很多,但在鐵道安全方面的研究就相對少了很多。本文僅針對障礙物、異物進入鐵道的AI辨識技術提供一個技術輪廓,以及表達一下這方面技術已發展地相當成熟,可以運用IntelR Media SDK & OpenVINO這類AI工具來加速開發及優化鐵道預警系統,強化列車行駛的安全,避免悲劇再次發生!
(本文作者為MakerPRO總主筆暨共同創辦人)
參考資料
[1] Obstacle Detection System Requirements and Specification白皮書
[2]運用 Intel OpenVINO 土炮自駕車視覺系統(MakerPRO)
https://makerpro.cc/2018/10/use-intel-openvino-to-make-self-driving-vision-system/
[3] Railway obstacle detection algorithm using neural network白皮書
https://aip.scitation.org/doi/pdf/10.1063/1.5039091
[4] OpenVINO Toolkit Intel's Pre-Trained Models
https://docs.openvinotoolkit.org/2021.3/omz_models_group_intel.html