過去三十年間,基於伺服器的運算歷經多次飛躍式發展。在1990年代,業界從單插槽獨立伺服器發展到伺服器叢集。緊接著在千禧年,產業首次看到雙插槽伺服器;在這之後,多核處理器也相繼問世。進入下一個十年,GPU的用途遠遠超出了繪圖處理的範疇,我們見證了基於FPGA的加速器卡的興起。
邁入2020年,SmartNIC網路介面卡(network interface card;NIC),即資料處理單元(DPU)開始風靡。它們大量採用FPGA、多核Arm叢集或是兩者混合運用,每種作法都能大幅提高解決方案的效能。從股票交易到基因組定序,運算正以更快的速度求得解答。在主機殼內部,資料通道是PCI Express(PCIe)。雖然幾經變革,但它仍然是毫無爭議的選擇。
PCIe 的演進發展
PCIe於2003年首次亮相,恰逢網路準備開始從以十億位元乙太網路(GbE)為主要互聯的時代往更高速的時代躍進。此時,Myrinet和Infiniband等高效能運算(HPC)網路分別以2Gb/s 和8Gb/s的資料傳輸速率超越GbE。此後不久,10-GbE網路介面控制器(network interface controllers,NICs)嶄露頭角,而且擁有優異效能。它們在每個方向上的速率都接近1.25GB/s,這種8通道(x8)PCIe匯流排的誕生恰逢其時。
第一代 PCIe x8匯流排在每個方向上的速率為2GB。當時16通道(x16)的插槽尚未問世,且伺服器主機板一般只提供零星x8插槽和幾個x4插槽。為了節省成本,部分伺服器廠商甚至使用了x8連接器,但有趣的是卻僅將它們連接成x4。
大部分人(例如網路架構師)都知道每一代PCIe的速率都翻了一倍。現今的第四代PCIe x8 插槽的速率大約為16GB/s,所以下一代PCIe的速率將大約為32GB/s,如果這就是第五代PCIe能達到的水準,那確實也不錯。不過它還可以像阿拉丁神燈那樣神奇,能以CXL和CCIX兩種新協議的形式允許在CPU與SmartNIC,或是輔助處理器等加速器之間實現高效的通訊。
CXL
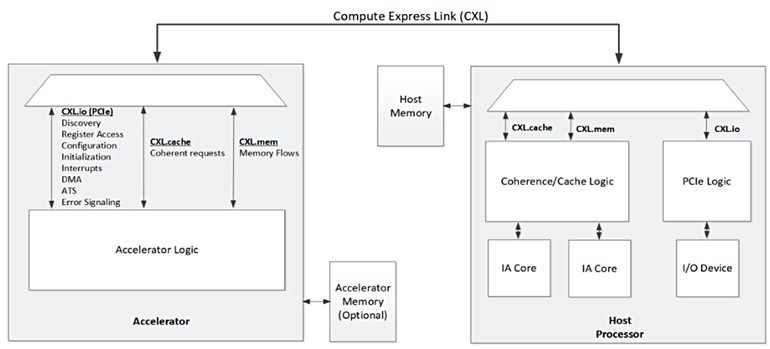
我們先來談CXL,它提供了定義明確的主從模式。在這種模式下,CPU的根聯合體(root complex)能透過與加速器卡的高頻寬連結來共享快取記憶體和主系統記憶體,如圖一。
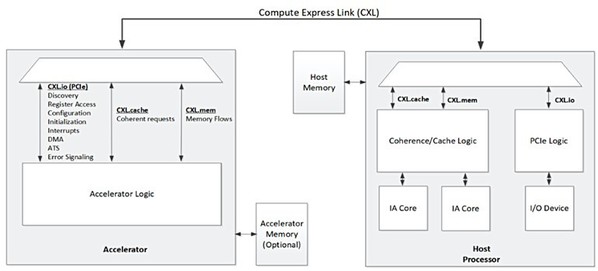
| 圖一 : 透過CXL與處理器相連的加速器概念圖(來源:Compute Express Link Specification July 2020) |
|
這有助於主機CPU可以有效地將供作分配給加速器,並接收其處理結果。部份此類加速器使用DRAM或高頻寬記憶體(HBM)來配備大容量高效能的本機記憶體。借助CXL,現在可與主機CPU共享這些高效能記憶體,從而更輕鬆地在共享記憶體中處理資料集(dataset)。
此外,對於不可分割交易(Atomic Transaction),CXL能在主機CPU和加速器卡之間共享快取記憶體。CXL在改善主機與加速器間的通訊方面有了長足的發展,但卻未能解決PCIe匯流排上的加速器之間的通訊問題。
2018 年,Linux內核終於推出了可支援PCIe點對點(Peer-to-peer;P2P)模式的代碼。這使PCIe匯流排上的不同設備之間更容易共享資料。雖然P2P早在此次內核更新之前就已存在,但它需要精心調整才能運行,往往要求用戶能夠透過程式設計就兩個對等設備進行控制。隨著內核的更新,加速器與PCIe匯流排上的PCIe/NVMe記憶體或另一個加速器間的通訊方式相對簡化。
隨著解決方案變得日益複雜,簡單的P2P已不敷使用,而且還會限制解決方案的效能。如今,我們使用DIMM插槽中的永久記憶體、NVMe儲存和直接插在PCIe匯流排上的智慧儲存(SmartSSD),搭配各種加速器卡和SmartNIC或DPU(其中有些本身就具有很大的儲存空間)。由於這些設備之間必須能互相通訊,因此昂貴的伺服器處理器將化身為成本高昂的交通號誌,使得海量資料流出現瓶頸。CCIX在此情形下就能大顯身手了,其環境適合在PCIe匯流排上的設備之間建立對等關係。
CCIX
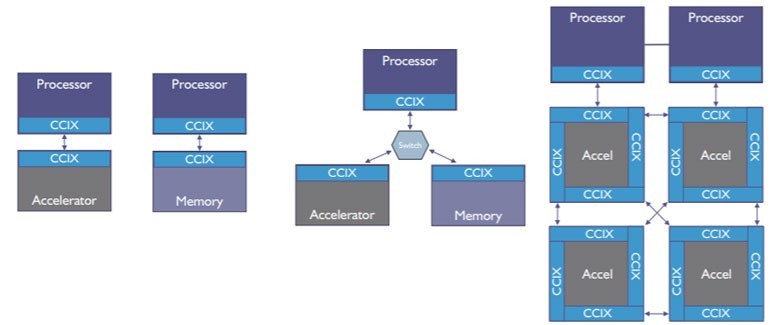
有些人認為CCIX標準與CXL大同小異,但事實並非如此。在實現匯流排上點對點連接,CCIX的方法與CXL截然不同,如圖二。此外,它還能利用不同設備上的記憶體,每個設備具有不同的效能特徵,對這些記憶體進行池化,並映射到單一的非一致性記憶體存取 (Non-Uniform Memory Access;NUMA) 架構。隨後它建立一個虛擬地址(Virtual Address)空間,使池中的所有設備都能存取NUMA記憶體的完整空間。這已經遠遠超出簡單的PCIe P2P記憶體間複製或是由CXL提出的主從模式。
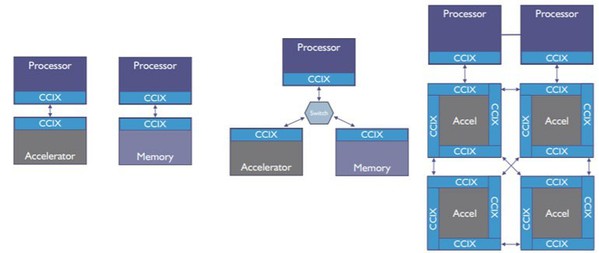
| 圖二 : 三種CCIX配置圖例,包括直連式、交換拓撲和混合菊鍊(來源:An Introduction to CCIX White Paper) |
|
作為一種概念,NUMA自1990年代初期以來就已經存在,所以業界對它非常了解。在此基礎上,當今大多數伺服器都能輕鬆地擴展到太位元組(TB)或更大容量的DRAM記憶體。不僅如此,還存在能映射名為持續性記憶體(Persistent Memory;PMEM)或儲存級記憶體(Storage Class Memory;SCM)的新型記憶體的驅動程式,它能與真實記憶體(Real Memory)搭配,創建「巨量記憶體」。綜合運用PCIe 5和CCIX,將會進一步使系統架構師能利用SmartSSD擴展這一概念。
運算儲存
SmartSSD也稱作是運算儲存,它將運算元件(通常為FPGA加速器)與固態驅動器中的儲存控制器緊密佈局,或在控制器中嵌入運算功能,從而使SmartSSD中的運算元件能夠在資料進出驅動器的過程中進行處理,進而重新定義資料的存取和儲存方式。
雖然SmartSSD最初被視為區塊裝置,但在FPGA中安裝適當的未來驅動程式後,可以當作像按位元組定址的儲存器使用。現今生產的SmartSSD具有數TB的容量,但容量還是會爆炸。因此,只有透過NUMA,SmartSSD才能用於擴展巨量記憶體的概念,這樣一來主機CPU和加速器應用就能跨眾多設備存取數TB容量的記憶體,且無需使用該儲存器重新寫入應用程式。此外,藉由實現在線壓縮與加密,SmartSSD還能提供更佳的TCO解決方案。
導入SmartNIC
具體應用上該如何使SmartNIC與此架構搭配呢?SmartNIC是一種特殊類型的加速器,位於PCIe匯流排和外部網路之間的連接處。SmartSSD將運算放在資料的附近,而SmartNIC則讓運算緊臨網路。為什麼這一點如此重要?簡單地說,我們很少關注伺服器應用自身的網路延遲、擁塞、封包遺失(Packet Loss)、協定、加密、覆蓋網路(Overlay Network)或安全政策等問題。
為了解決這些問題,創建了諸如QUIC之類的低延遲協議來改善延遲問題、減少擁塞以及從封包遺失中復原。我們精心開發出了TLS並採用內核TLS(kTLS)加以擴展,以提供加密和安全的資料傳輸。我們現在看到kTLS被添加為SmartNIC的一項卸載功能。
為了支援虛擬機器(VM)和容器(container)的協作,我們創建了覆蓋網路,隨後又開發出Open vSwitch(OvS)等技術定義和管理覆蓋網路。SmartNIC正開始卸載OvS。
最後,我們按照政策進行管理以確保安全。這些政策有望反映在Calico和Tigera等形式的協作框架中。這些政策很快也將透過使用P4等編程match-action框架被卸載到SmartNIC。這些任務都應該卸載到稱為SmartNIC的專用加速器中。
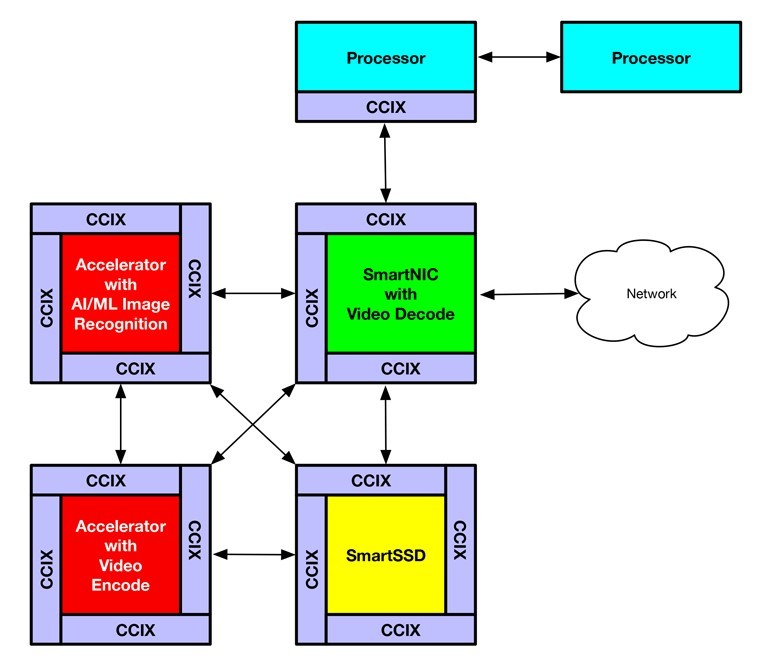
架構師可以藉由CCIX構建出一個解決方案,作為具有單個虛擬位址空間的巨量記憶體空間,使多個加速器直接存取真實記憶體和SmartSSD中的儲存器。例如一個解決方案可由四個不同的加速器來構建,如圖三。
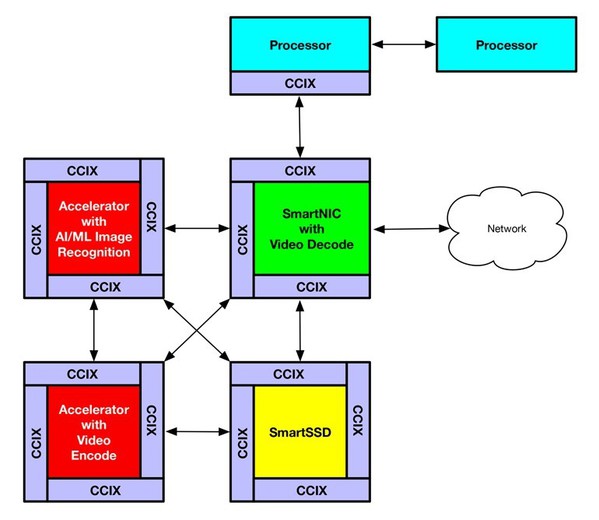
| 圖三 : 圖中所示為CCIX應用範例,它使用了修改過的CCIX 4c-混合菊鍊模型 |
|
SmartNIC可能裝有視訊解碼器,以便從攝影機導入視訊時,可以轉換回未經壓縮的幀,並儲存在NUMA虛擬位址空間的共享幀緩衝記憶體中。在這些幀可用後,執行人工智慧(AI)影像辨識應用上的第二個加速器能掃描這些幀,辨識人臉或車牌。與此同時,第三個加速器可以對這些幀進行轉碼,用於顯示和長期儲存。最後,在SmartSSD上運行的第四個應用則負責在AI和轉碼任務成功完成後,從幀緩衝記憶體中刪除這些幀。這裡我們用四個高度專業的加速器協同工作,形成所謂的「Smartworld」應用。
業界開始增添更多內核以解決與摩爾定律相關的問題。如今,雖然有大量的內核,但CPU與 NIC、儲存和加速器等外部設備間的頻寬不足。PCIe Gen5是我們的下一個關鍵發展點。它能大幅提高頻寬,開啟在CPU上進行高效能運算的時代。
例如,典型的CPU核心能處理1Gb/s+,但如果你採用128個雙核CPU,那麼PCIe Gen4x16是不夠用的。對於需要在CPU核心和加速器之間進行密切交互的應用來說,CXL和CCIX協議提供的快取記憶體一致性具有諸多優勢。資料庫、安全性和多媒體等主要應用作業負載現在正開始利用這些優勢。
協作
這個問題的最後一個環節是協作。這項功能指Kubernetes等框架能自動發現並管理加速的硬體,並在協作資料庫中將其標記為在線可用。它隨後還需要知道該硬體是否支援上述一個或多個協議。隨後,隨著對新解決方案實例的請求進入並動態啟動,能夠由這些高級協定感知並加速的容器執行個體就可以使用該硬體。
以賽靈思資源管理器(XRM)為例,能夠與Kubernetes協同工作並管理池中的多個 FPGA資源,從而提升加速器的整體利用率。這樣一來,就能自動分派新發佈的執行個體應用,使其在基礎設施中最適當的高效能資源上執行,同時遵守既定的安全政策。
SmartNIC和DPU使用了PCIe 5和CXL或CCIX,將為我們提供高度互連的加速器,有助於開發複雜、高效能的解決方案。這類SmartNIC將在我們的資料中心內乃至整個世界範圍內,向其他系統提供運算密集型連接。甚至可以構想這樣一個未來:命令一旦進入Kubernetes控制器,就在SmartNIC資源上以原生執行的方式啟動容器或Pod。這個新作業負載的大量運算隨後可能會在伺服器中某處的加速器元件上進行,甚至完全不需要伺服器主機CPU的直接參與。
結語
為了正確發揮這樣的功能,就需要進一步強化安全,使安全水準遠遠高於Calico和Tigera。此外,我們也需要新的加速器感知安全框架來將安全環境(通常稱為安全隔離區;Secure Enclave)擴展到多個運算平台上,這樣就使得機密運算有了用武之地。它應該同時提供所需架構和API,為單一個安全隔離區內多個運算平台上的在用資料提供保護。
所有敏感資訊隔離設施(Sensitive Compartmented Information Facility;SCIF)都是如此。電腦中的安全隔離區應能涵蓋多個運算平台,而激動人心的時刻就在眼前。
(本文作者Scott Schweitzer為賽靈思技術傳教士)