在智慧物聯(AIoT)的世界裡,物聯網當然是串聯各式終端的核心基礎建設,但其最終的目標,則是要實現「智慧」的境界?而要達成這個願景,「深度學習」就是必須要了解的一項關鍵技術。
大家都知道,所謂的「人工智慧」是一個整合性的科技成果,它是透過多項技術交互運用後的最終風貌。所以,要到達人工智慧,其實是有階段性的。我們常會看到這樣一張圖片,人工智慧最外面的大圈圈,中間則是「機器學習」,最裡頭的小圈圈,就是「深度學習」。
所以由此可知,深度學習就是實現機器學習的核心技術,而機器學習則是系統學習能力與智慧功能的來源。
至於深度學習本身的技術原理,則與神經網路(Neural Network)技術的運用有很大的關聯。雖然說技術的解釋與說明,並不是本專欄的重點,但理解神經網路的基本原理,則是探討AIoT應用的重要基本常識。
顧名思義,神經網路就是一種參考人類腦神經結構的一種演算法,它最大的特色就是採用「神經元」多節點連結模式,以及多層的運算式來運作。這裡所說的神經元,就是處理資料輸入的種種函式,並將之往下一層輸出。所以整個神經網路的運作原理,就是以數值與向量模式,把輸入的資料作分類、轉譯、標籤化等方式,設計作為模型識別使用。
理論上,越多層、越多節點的運算式,就可以分析越複雜的資料,也有很大的可能可以取得越精準的模型。但這完全取決於資料的形式,與研究者的演算法設計,並不見得越複雜就越好,最終還是取決的所產生的模式是不是夠精確。但可以確定的是,複雜的資料與演算法結構,對於硬體與運算資源就有更大的要求。
而在AIoT應用場景中,取得大量的數據資料並對其進行分析,一直是此應用的核心競爭力所在。而數據的來源,經常都是終端設備裡的各式感測器所自動採集而來,或者是各式的商業與工業流程所產生的文件與資料。
傳統上,龐大的運算式與分析功能,都會被設置在雲端平台或者更上層的核心IT系統中。但AIoT應用裡,則是期望能夠更快速的反應在第一線的裝置裡。所以這些數據與資料,就需要在終端裝置中就先進行分析與運算,以快速對用戶指令進行反應,以提升系統的智慧功能的反應速度,並且提升使用體驗。所以深度學習的技術,就會被部署在終端裝置中,這也就是邊緣運算的基本原理。
而這樣的思考已被市場普遍的認可,因此深度學習技術就變成了AIoT應用的顯學。依據市場研究機構Grand View Research的研究報告,至2025年,深度學習市場的規模將達到102億美元,複合年增長率達到52.1%。主要的成長驅力就是機器學習演算法的顯著改進,以及深度學習晶片組的快速成長。
至於主要的應用領域,則是各種積極導入人工智慧技術的式場,例如自駕車、安全監、智慧語音輸入、智慧製造、以及醫療影像分析等。這些應用都需要針對大量數據進行分析與運算,因此深度學習和神經網路的採用就變得十分重要。
透過軟硬整合提供深度學習能力
以Arm為例,Arm本身並不提供演算法,而是協助開發者聚焦創意,加速軟體開發流程。Arm首席應用工程師沈綸銘指出,為了讓開發者聚焦創意,開發工具需要更簡化而有效。在今天,嵌入式運算與嵌入式世界正遭遇重大改變,即嵌入式發展以及物聯網、機器學習(ML)與數據科學彼此間越來越大的重疊。由於嵌入式、ML與雲端開發者從截然不同的領域和角度來處理終端裝置設計,Arm的工具必須應對所有團體的需求,不管選擇的裝置或作業系統為何,開發工具必須提供終端裝置與任何雲服務供應商之間,無縫整合與連接的能力,好讓開發者聚焦於創意,發展如何為市場帶來具有競爭優勢的全新差異化功能。
Arm的強化套裝工具可加速開發流程。Arm次世代的開發解決方案可結合現代網路技術,以及微控制器開發套件Arm Keil MDK,另外還有完整的C/C++嵌入式套裝工具Arm Development Studio的成熟開發與除錯功能。其結果是在各種微控制器與開發板上,都能更快速且更直覺地通過產品的開發流程。
目前Arm正與微軟合作,為物聯網終端裝置加速AI的創新。透過這個協作,Arm將把共同的專注力集中在優化與加速完整的AI作業負載開發生命周期,進而在Azure雲端服務平台上訓練與調整ML模型,到在任何Arm架構的終端裝置上優化、部署與運行這些模型,這將促成嵌入式、物聯網與ML開發社群彼此間產生更有效的體驗。
此外,也透過與帝視科技合作AI Super Resolution深度學習解決方案,為DTV、4K/8K電視等,改善畫質、降噪、增艷色彩。
行動裝置深度學習
對於處理輕量DL/ ML工作負載的Cortex-M,例如穿戴式裝置,則是透過Armv8.1-M 架構M-Profile Vector Extension(MVE)向量擴充方案的Helium技術,簡化開發者軟體開發流程,並顯著提升未來基於Cortex-M處理器裝置的機器學習與訊號處理效能。Helium技術將為未來Arm Cortex-M處理器提供達15倍的機器學習效能以及提升5倍的訊號處理效能。
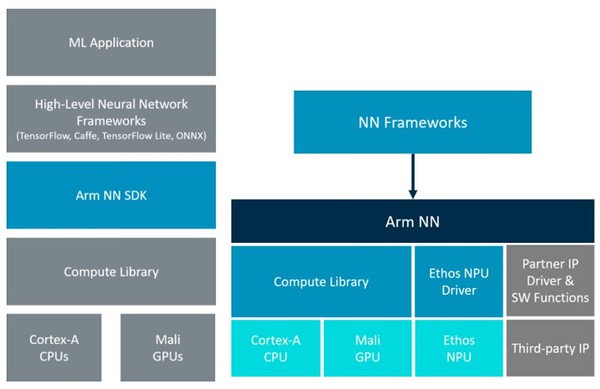
| 圖二 : Arm NN(Neural Network)軟體框架圖 |
|
對於處理大量且複雜的DL/ML工作負載的Cortex-A系列,例如智慧手機,則透過Arm NN(Neural Network)軟體框架,可在Arm架構的高效能平台輕鬆構建和運行機器學習應用程序。它往上銜接現有神經網路框架(例如TensorFlow或Caffe)與在嵌入式Linux平台上運行的底層處理硬體(例如CPU、GPU或NPU)。而這正是機器學習、深度學習在邊緣裝置上進行推論時,需要的解決方案。
效能與功耗的平衡
以Ethos-N78為例,它支援超過90種獨特的組態,並允許合作夥伴針對乘加器(MAC)、靜態隨機存取記憶體(SRAM)進行組態,提供矽晶圓合作夥伴更多彈性,此彈性確保夥伴們可以精細調整他們的設計,以便達成效能、耗電功率與面積間的平衡。此外,Ethos-N78 也可應用於各式各樣的裝置上,並擁有透明的軟體相容性與可攜性。
另外,在面積與使用DRAM頻寬則更小。與前一代產品相比,面積效率最高達到30%的提升,讓合作夥伴得以在更小的矽晶片面積上達成更好的效率。矽晶片面積雖然是重要的成本度量,但動態隨機存取記憶體(DRAM)的頻寬,同樣也是電子系統中珍貴的資源。Ethos-N78的設計讓它使用特別少的DRAM頻寬,每個推論(inference)消耗的DRAM數據最多可以減少40%,讓我們的夥伴得以用更少的記憶體實作ML,進一步降低系統的耗電與成本。這樣的運算硬體架構允許在軟體的應用內廣泛使用ML,同時能確保長的電池續航時間。