基本上有接觸過自動控制架構的每個人,幾乎都知道可以透過CPU、FPGA以及PLC來進行複雜伺服馬達的運動控制,例如雙軸插值(Interpolation)、凸輪控制等。但是到目前為止,甚少發現利用PLC來負責這些動作的計算。
這時會有個疑問出現,為什麼不利用PLC來控制?通常來說,這些由PLC進行控制非常不錯,但是PLC大多是負責多工的(multi-tasking)處理,所以幾乎沒有餘力可以再負擔複雜的伺服馬達計算。
因此在進行運動控制時,就需要採單一Tasking處理才能達到高速運算的作業目標。另外,也不適合用PLC來編寫雙軸插值和凸輪控制等複雜的作業,最好將伺服放大器和CPU組合一起作為伺服馬達的專用機制,即使以後進行修改也可以降低成本。
不適合透過PLC單獨對伺服馬達高速控制
因此,透過CPU、FPGA與其他機構的搭配可以減輕PLC程式的負擔,另一方面,CPU具有高速計算能力適用於控制伺服馬達,因此PLC可以專注擔任其他機器控制(感應馬達等)和訊息控制來分配處理負載。
什麼是簡單運動單元(Simple Motion Unit)?簡單運動單元可以執行與CPU相同的控制(雙軸插值、凸輪控制等),並且可以透過來自PLC的命令輕鬆進行操作。
由於它是受限需要於PLC的命令輸出,因此在連續執行伺服馬達時,CPU可以比簡單運動單元更快地完成操作。此外,簡單運動單元還有一個優點就是比CPU便宜,並且可以使用常規MOV命令輕鬆控制PLC的程序。不過卻有一些情況,並不常利用這種廉價而又容易進行操控,簡單運動單元來做為伺服馬達的馬達,而是要使用麻煩的CPU呢?
這是因為在進行高度運動控制時,又可以不受PLC掃描時間影響的一種高速系統架構。PLC的掃描時間會受到程式容量的影響,因此伺服馬達的多軸控制無法避免增加PLC的程式量。如果CPU可以控制伺服馬達的操作模式和時序,就可以大幅減少PLC程序的負載。
運算單元的配置相當重要
運動系統控制的過程包括在設備的智慧化和自動化中,具有離線(Off Line)計算能力以及智慧,並透過線上(On Line)計算實現功能的流程。由於離線計算沒有時間限制,因此即使運算單元的能力不佳也可以利用時間來彌補,但是在即時的On Line計算中,運算單元的配置就變得相當重要。
對於軟性即時(Soft Real Time)處理,可以採用具有高性能OS的CPU,但是當需要FArm/硬性即時(Hard Real Time)處理,或許微處理器或FPGA會更易於使用。因為FPGA除了有高精緻的優點,在需要即時處理的情況下更具有優勢。
舉例來說,圖1是利用FPGA完成的一個採樣頻率為1 MHz的機器人運動控制系統,在這樣的FPGA高精細執行高速訊號處理的架構下,可以獲得的控制性能非常好,可以輕鬆達到精確控制 (使用解析度為10 nm的光學編碼器進行定位,並且誤差在1或2個脈衝之內)。還可以藉由FPGA的高精細度,透過高速訊號處理等方式消除運算系?中的噪訊,提高控制系?的增益。
| 圖1 : 利用FPGA完成1 MHz採樣頻率運動控制實驗(source:Increments) |
|
這樣一來,就可以不用受到像傳統的H∞最佳化控制理論的限制與約束,可以提高增益,使得系統性能得以大幅度提升。這樣的機制比起費盡心力的設計補償器更容易獲得更好的性能。
CPU與FPGA的互補與優劣勢
就工業控制器的開發與使用而言,所有工程師都希望盡可能地降低控制器成本,微控制器已經大量的使用,例如安川電機和三菱CPLD,由於物聯網的趨勢而被廣泛使用。現今由於缺乏通用介面(尤其是通訊系統)的靈活性,而又回到了採用微控制器,或者導入SoC FPGA來實現Linux on ARM中的高階功能,同時在FPGA中進行控制的例子。
雖說FPGA的優勢性目前正在擴大,如果不能在指令級確保並行性,與CPU相較之下就會顯得遜色,畢竟這樣的FPGA只能當作運算工具,用來執行向量運算的並行ALU。
實際上用於機器人運動控制的命令值生成與數據相關,是循序運算或使用三角函數計算的,因此使用FPGA進行效率非常低。反之,這會使得CPU被採用的頻率更高,即使非常努力的設計FPGA運用架構,相信也無法達到期望值。
另外,因為對於機器人的運動控制,在校正錯誤的反饋(Feedback)這一部分,包括從觀察(計算器輸入)到校正指令輸出(計算器輸出)的過程,當然是愈快愈好。所以希望能獲得高速處理能力,而工程師就需要更高密度的設計I/O系統和電路,這也是FPGA將常被導入架構應用的原因之一。
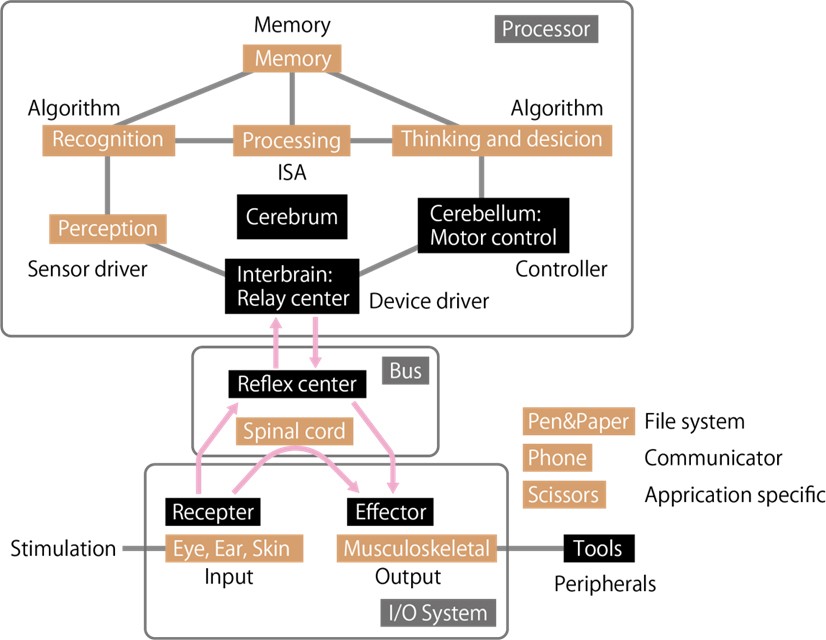
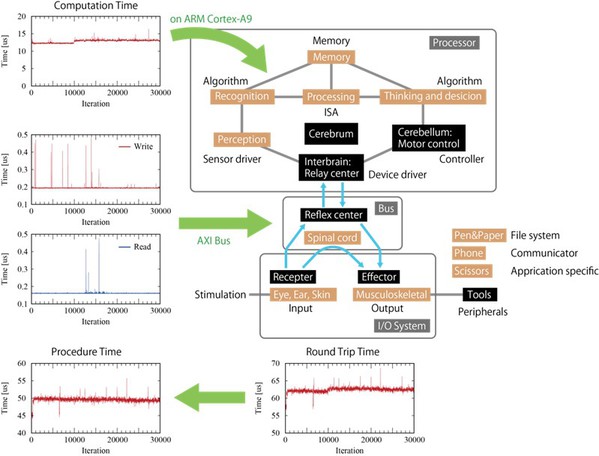
如同人體的反射動作與思考判斷後動作
為了更容易理解上述的要求,在這裡以模擬的方式來說明該運算單元(圖2)。
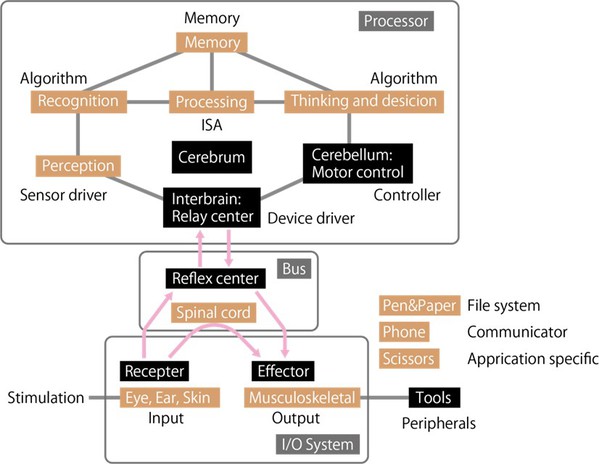
| 圖2 : 訊號判斷的處理與傳輸架構 (source:Increments) |
|
就人體身體的感測機制而言,例如包括眼睛、耳朵和皮膚等生理感測器,從外界的刺激現象獲得感受訊號後,會將這些感受訊號傳遞至入體內相關機制,有一些訊號會進入大腦,有一些訊號會進入脊髓,並對肌肉或骨骼系統等發出命令。
而進入大腦的訊號通過間腦的中繼中心,隨後在顳葉和頂葉進行判別,再透過顳葉和枕葉的感覺部分,在額葉做出決定並在小腦發出動作控制訊號,這些訊號再通過間腦進入肌肉骨骼系統。
這樣的處理機制相當類似於CPU的功能。因為利用FPGA中的平行算術邏輯單元(Arithmetic Logic Unit;ALU)來執行的加速運算,等同於增加頂葉和額葉等結合區的面積並增加計算量。
另一方面,因為脊髓反射動作沒有經過大腦,因此速度很快,這樣的反射中心類似於為FPGA上精心設計的I/O系統電路。由於肌肉骨骼系統是在腦以外勵起作用並反映,就像是效應器,使用筆和紙進行記錄和讀取等使用外部工具。
在使用SoC FPGA的設計中,就像需要利用大腦的訊號處理是透過CPU進行運算,而脊髓所發生的反射動作則是經過FPGA處理。CPU可以進行運算程序來完成許多不同的事情,但是各種過程(中斷和匯流排控制)都需要時間等待,才能在CPU處理。
源於I/O所造成時間的延遲累加
透過以下的例子,就可以了解運算工作分配的重要性,如果不能善用類似脊髓可自發生反射動作的FPGA,解決一些即時性的Feedback或校正錯誤,而是無限度的將計算工作丟給CPU,就會出現不斷累加的計算時間延遲結果。
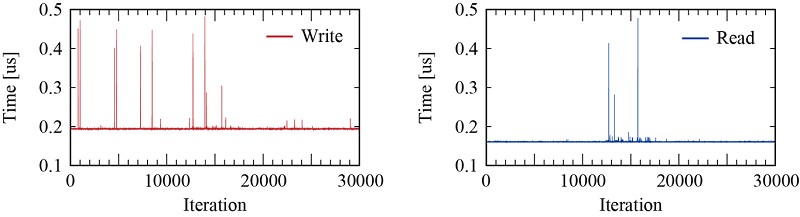
這個例子是測量每個程序所需的過程時間來了解反應速度的區別。在此項實測中,採用ARM CPU與FPGA搭配,並用AXI4通訊協定來連接,對應在Arm CPU上映射的I /O的寫/讀速度(圖3)。這個測試是執行30000次所需的控制時間,每次讀寫100次所花費的時間除以100,而測量計時器放置在FPGA上。
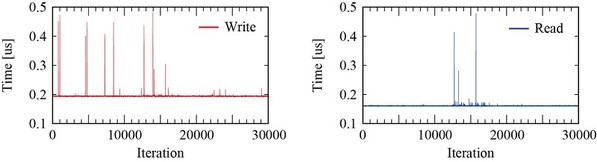
| 圖3 : 利用ARM CPU上映射的I /O的寫/讀速度(source:Increments) |
|
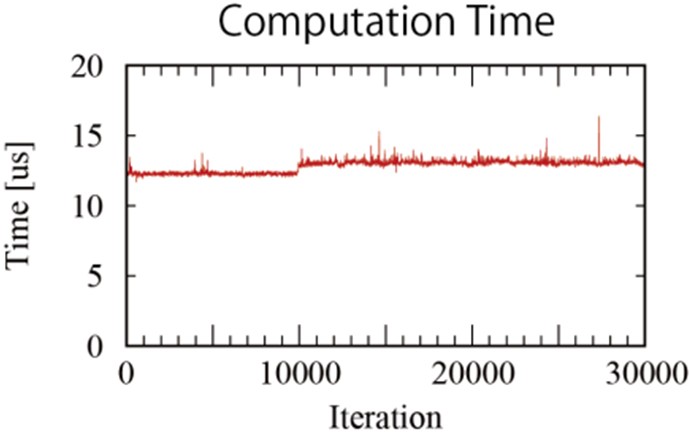
執行機器人運動控制所需的代碼,在此是採用了時鐘獲取時間(clock_gettime),由於時鐘獲取時間本身的負荷,會有1us左右的誤差。可以發現進行第10000次之後,在計算三角函數時所需要的計算時間出現了增加的現象。
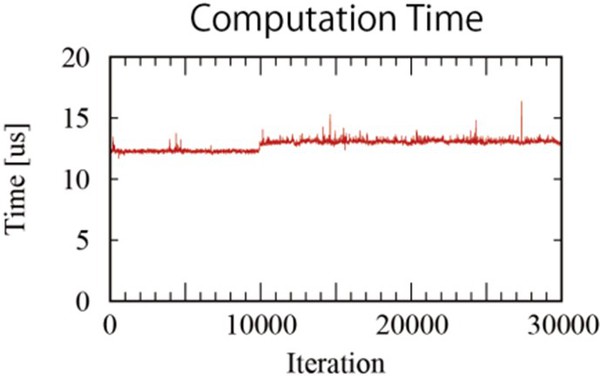
| 圖4 : 進行第10000次之後,計算時間出現增加(source:Increments) |
|
從受體到效應器的往返時間
結果是,從FPGA向Arm CPU發送出中斷,並使用FPGA上的計時器,測量了直到從Arm進行I/O寫入為止的時間。同時也考慮到AXI4的速度和Arm計算時間,它花費了很長的時間。從往返時間中減去AXI4通訊時間和Arm操作時間,使用處理器的程序處理時間如下(圖5~6)。
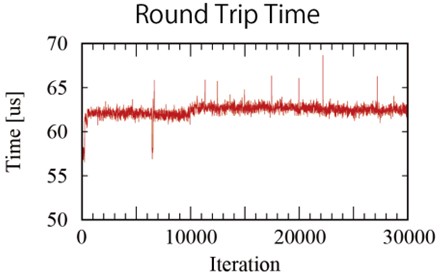
| 圖5 : 3萬次的封包來回時間(source:Increments) |
|
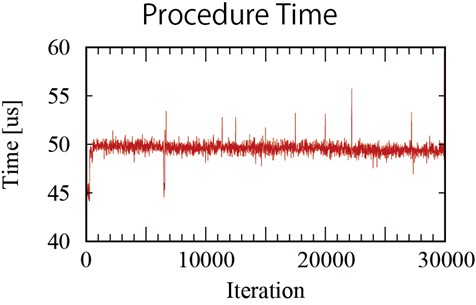
| 圖6 : 3萬次的運算處理時間(source:Increments) |
|
從例子可以發現,在處理中斷的過程中,可以發現有延遲的情況出現,由於中斷使用UIO的速度很慢,所以應該利用內和運算來進行處理,相信回應速度會比較快(圖7)。
| 圖7 : 利用內和運算進行處理,相信回應速度會比較快。(source:Increments) |
|
如果要在短時間內使用Arm處理器進行採樣,就必須管理時程。如果想利用Arm CPU進行短時間採樣時,就不得不認真考慮處理中斷這個動作時所耗費的時間。
而在控制方面,訊號處理系統會受到時間軸的抖動影響,可以對FPGA做精確時間的平均採樣,或許這非常有用。另外,還能透過FPGA本身的高精緻度特性,在電腦程式中建立很多執行緒,每個執行緒都有自己的時鐘,並且嚴格定時,相信這對於在執行各種操作的機器人運動控制系統中是非常有用的。