科學家和工程師能藉由專業領域知識在AI專案取得某種程度的成果;然而,若利用如自動標記等工具來快速地處理龐大、高品質的資料集,將是進一步成功的關鍵。
隨著取得了現有深度學習模型與研究並加以持續改進,科學家與工程師得以在人工智慧(AI)專案得到更大範圍的成果。傳統上,AI模型大多數以影像為基礎,不過接下來這一年,AI模型將涵蓋更多樣化的資料類型結合,從感測器到時間序列,再到文字和雷達資料等等。
| 圖1 : 傳統上,AI模型大多數以影像為基礎,未來AI模型將涵蓋更多樣化的資料類型結合。 |
|
科學家和工程師固然可藉由自身具備的專業領域知識在AI專案取得某種程度的成果;然而,若還可以利用某些工具如自動標記等來快速地處理龐大、高品質的資料集,將是進一步成功的關鍵。資料品質愈高、資料量愈大,愈能增加AI模型的精確性,成功機會也愈大。
豐富的模型化基礎設計工具
更多複雜設計、以AI為驅動的系統正不斷增加,因此AI模型的行為對於整個系統性能將帶來重大影響,帶動了更多嚴格測試流程的需求。因此,在2020年,我們將看到更多能提供模擬、整合與持續測試的模型化基礎設計工具被大量地採用。
模擬可讓設計者測試人工智慧與系統之間如何進行互動,整合則可幫助設計者在完整的系統情境下試驗他們的設計,持續測試有助於更容易地找出AI訓練資料中的弱點和其他元件的設計缺陷。
透過協作機器人與AI使生產線更靈活
透過AI來進行的參數化和調整的Cobots—在人類身邊運作的協作機器人(由collaborative robots合併縮寫而成)—將是2020年後實現真正靈活生產線的關鍵。在過去五年,關於工廠廠房生產線自動化的新願景被大量地談論—「大批產品客製化(sample size one)」,也就是生產線如何藉由逐一生產每個單項產品,以避免缺乏效率和轉換時間長的問題。
要實現工業4.0願景之一的生產完全個別化,生產線必須具備靈活性,並設有多個可以在生產過程中即時重新調配的機械電子模組,也需要配置更多協作機器人,這些皆由AI依據下一個要製造的個別化產品進行調整。

| 圖2 : 由AI驅動生產線的靈活性是實現工業4.0生產個別化的關鍵 |
|
邊緣運算與預測性維護持續演進
雲端系統的使用,再加上更強大的工業控制器和邊緣運算裝置的運算能力,將為新的功能性生產系統軟體鋪路。預測性維護技術將持續改進,隨著資料來源不只來自單一個別機器,也包括了跨越多個地點及不同供應商設備間的資料。除此之外,以AI為基礎的演算法將可動態地優化整個生產線及生產量,並將耗能維持在最低,持續提升工廠效率。

| 圖3 : 預測性維護技術將隨著感測資料的多元化而持續精進 |
|
強化學習之工業應用
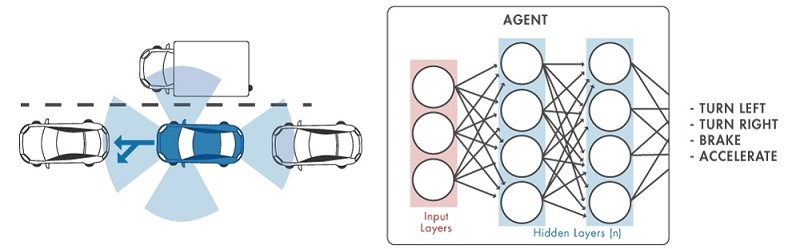
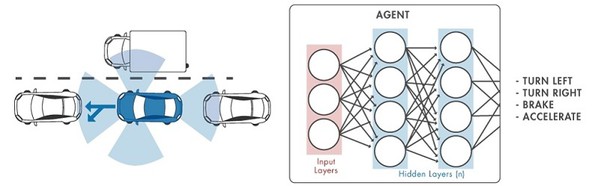
強化學習(reinforcement learning),指電腦反覆跟一個動態環境間不斷地互動、透過嘗試-錯誤(trial-and-error)來學習執行一項任務。應用範圍從在Go和下棋等桌上遊戲裡打敗人類玩家,到變成提供工程師一系列的支援。在工業應用上,它可以被用來實現控制器及複雜系統的決策演算法,像是機器人和無人自主系統等。
提供工程師們更容易使用的工具來建立與訓練強化學習策略,並訓練所開發出的模擬資料,是驅動未來強化學習(reinforcement learning;RL)改善大型工業系統的重要關鍵。
其他驅動強化學習應用的因素,還包括了能將強化學習主體(agents)與系統模擬工具整合,以及讓嵌入式硬體的程式碼生成變得更加容易的工具。舉例來說,將一個強化學習主體加入自主駕駛系統可以改善及優化駕駛的表現、提升速度、降低燃料消耗及回應時間等等。
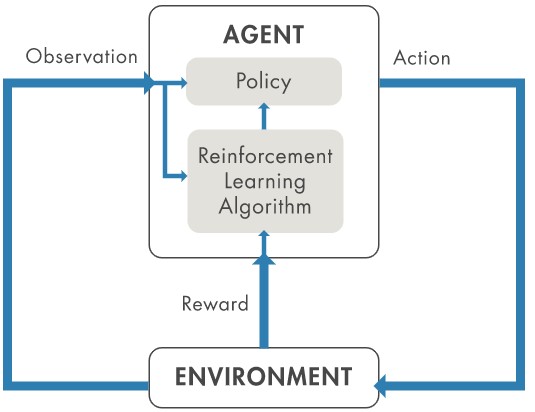
| 圖4 : 強化學習-由電腦所代表的主體與動態環境不斷地互動,以嘗試錯誤的方式來學習如何執行任務 |
|
隨著科技的進步,科學家與工程師將享受大量的好處,不過工具的使用、增加學習與採用工具來處理更大資料集工作任務的意願、以及建立新模型與測試AI驅動系統等,將是實現所有工業4.0願景功能勢在必行的工作。
(本文由鈦思科技提供;作者Jos Martin任職於MathWorks公司)