隨著多媒體技術及相關設備的發展,使用者體驗受到越來越多的重視,例如影片從過往黑白無聲的畫面,至今日進入超高畫質的階段。高解析的影片如HD、Full HD 解析度的影片已取代類比電視 480P 解析度成主流,目前隨著硬體設備的進步已提升至4K即3840*2160 pixels。
除了影像畫面本身的解析度提升之外,呈現方式亦從使用者單方面的接收內容,發展至今如自由視角(Free-View Video, FVV)等使用者可參與顯示內容之形式,或跳脫平面之三維視訊( 3-D Video)如3-D電影等新型態的應用來獲取近似於身歷其境的體驗。
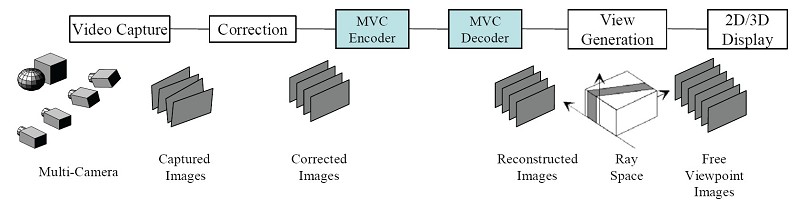
自由視角視訊與三維視訊的實現,為拍攝時利用多組攝影機組成攝影機陣列對場景進行不同角度的拍攝,對於攝影機未拍攝的視角,即可利用相鄰的攝影機視角進行合成,應用時傳送多個不同視角的資訊至使用者端,再對使用者所要求的視角進行合成與顯示。
然而此類應用由於需要傳送多個不同視角的資料,加上畫面解析度及品質的提升等考量,需要傳送的資料量更為龐大,因此如何提升壓縮效率以減少傳送成本是個重要的議題。
對此議題,國際電信聯盟(International Telecommunication Union, ITU)的視訊編碼專家群(Video Coding Experts Group,VCEG)和國際標準組織(International Organization for Standardization/International Electrotechnical Commission, ISO/IEC)共同組成的聯合視訊小組(Joint Video Term, JVT),開發一個可供使用者選擇觀看視角的多視角視訊編解碼技術(Multi-view Video Coding, MVC),此技術建構於MPEG-4 AVC/H.264標準上,其中便包含了立體視訊顯示與自由視角兩大應用。
深度資訊編碼知識背景
影像區域的分割
電腦視覺(Computer Vision)隨著科技的進步,被應用在非常多不同的應用,如近年來很流行的體感遊戲、社群網站上傳影像後,可以直接進行人臉辨識、或是手機拍照後,可以將前後背景或物件分離,影像區域分割(image segmentation)技術的發展,占了非常重要的一環。
將一張輸入的影像,依照色彩相似度或紋理特性等許多不同的特徵值,分割為許多不同的區域或物件。然而數位影像是由許多像素(Pixel)所組成的矩形區域,而每個單一像素卻只能表達自身的區域資訊,無法提供與相鄰區域的關聯性。
因此,區域劃分須透過影像處理,將畫面內的像素依照特性進行分群(clustering),得到的結果相會是特性相近的區域,即可將資訊應用於影像檢所、動態估測等不同的領域。
許多研究電腦視覺影像的學者分別提出許多不同的影像區域劃分方法,將這些被提出的演算法蒐集後,區分為主要三大類別:Region-Based Segmentation Methods、Data clustering以及Edge-Based Segmentation Method。
(1)區域為基礎的分割方式(Region-Based Segmentation Methods):
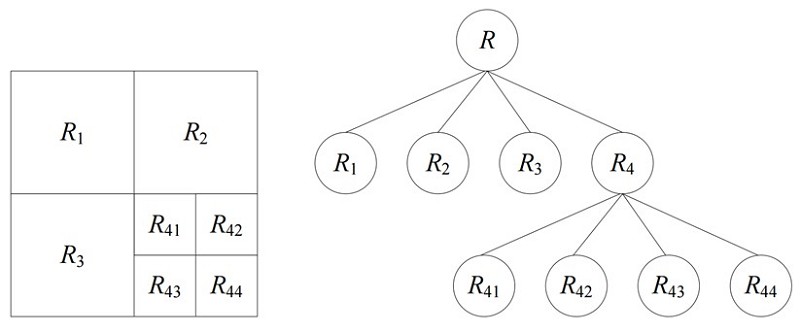
此分割方法主要是假設同一區域內的相鄰像素應具有相似的數值。經由比對此像素若是與相鄰之像素具有相似性,則可將此像素歸納至同一分群之中。因此,相似性判定標準將會影響到區域劃分的結果。文獻中也提到相關延伸之區域劃分方法如Seeded Region Growing、Unseeded Region Growing、Region Splitting and Merging。圖1為Region Splitting and Merging採用四分樹(Quad-tree)的架構進行區域劃分。
(2)資料分群(Data clustering):
資料分群是被廣泛應用於影像分割和統計的方法之一。其主要的概念是在於找出影像資料中較相似的幾個群聚(clusters),並找出其代表點,稱為中心點(centroids)以達分割的效果。主要可分為階層式(Hierarchical)和分割式(Partitional)聚類。類似的演算法,如Squared Error、K-means或Mean Shift。
(3)邊界為基礎的分割方式(Edge-Based Segmentation Method):
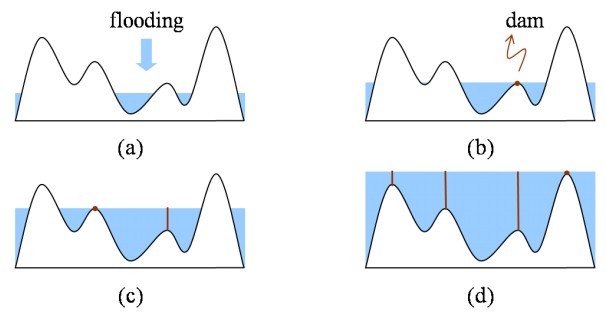
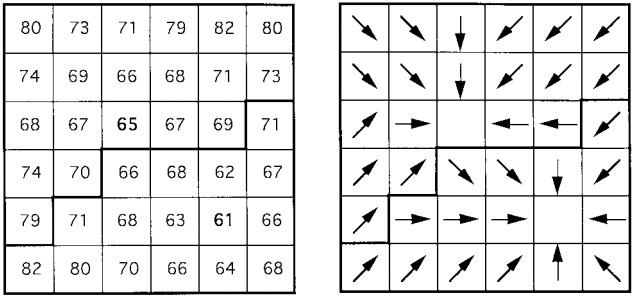
此方法通常使用邊緣檢測後進行分類,如梯度算子(Gradient operators)和希爾伯特變換(Hilbert transform)。而另一種方式不同於使用邊緣偵測工具,則是利用邊緣的變化的特性,如分水嶺分割算法(Watershed Segmentation Algorithm)。該演算法為找出影像中的分嶺線(Watershed line)進而影像進行切割。如圖2、3。
立體視覺視訊、原理與架構
立體影像的原理為雙眼接收到同一場景之不同角度的影像時,會於腦中將之合成為立體影像。人類的左眼與右眼間的距離約為5至8公分,因此對於同一場景而言,兩眼個可捕捉到另一眼所無法捕捉的畫面,再加上角度不同所產生的誤差所產生的兩眼畫面不同,這些誤差即稱為視差(disparity)。
人類的大腦會將視差進行處理,進而使人類感受到視覺上的遠近關係,因此欲產生立體視訊,則必須至少有兩個視角的資料,再由相關的硬體設計,如偏振切割、時間切割等技術,使不同視角的畫面分別顯示於兩眼,藉此達到立體畫面的效果,如圖4所示。
自由視角視訊原理與架構
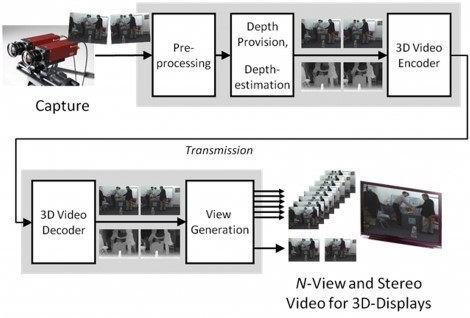
@內文:自由視角視訊(Free-Viewpoint Television Vidoe)利用多台經過校準的攝影機陣列進行拍攝,然後再進行編碼與傳送,其架構如圖5。
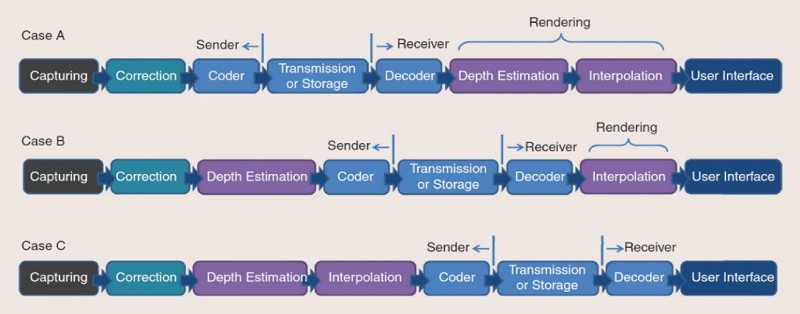
透過多視角視訊的訊息,可以在接收端合成任一角度的虛擬視訊。如圖6中分別表示了三種因應不同的系統限制(如硬體或頻寬等)之多視角視訊編碼架構,可對應使用者的使用環境選擇於傳送端或接收端進行影像合成。
現有相關深度資訊編碼架構
區塊為基礎的編碼方式-3-D HEVC Extension深度資訊編碼
深度影像的編碼在3-D HEVC參考軟體中,以附加工具(3-D HEVC Extension)的形式提供,其基本架構承襲HEVC編碼架構而來,因此諸如畫面內預測(intra-prediction)、運動估測與補償(motion-compensated prediction)、視差補償估測(disparity-compensated prediction)、變換編碼(transform coding)等工具,均如同應用於紋理編碼一般可套用於深度資訊編碼。
然而基於紋理資訊與深度資訊的差異,3-D HEVC Extension針對某些編碼工具進行了新增或修改,使其符合深度編碼的特性,如色彩取樣模式因深度資訊為數值範圍0-255的灰階影像,因此僅使用4:0:0色彩取樣模式。
為了因應不同角度的攝影機所擷取之畫面可能有景深極大值與極小值不同,而造成同一深度平面卻有不同深度值的問題,而新增了Z-near z-far compensation(ZZC)工具以確保進行畫面間預測(inter-frame prediction)時,所有參考畫面皆可以處於相同的參考點進行比較。
3-D HEVC Extension新增了四種不同的區塊模型模式(modeling mode)來對當前編碼區塊進行模擬,此四種模型的概念皆為將當前編碼區塊劃分為兩塊常數區塊,因此僅需對劃分方式以及切割後的兩區塊內深度常數值進行編碼,即可達到節省位元率的目的。
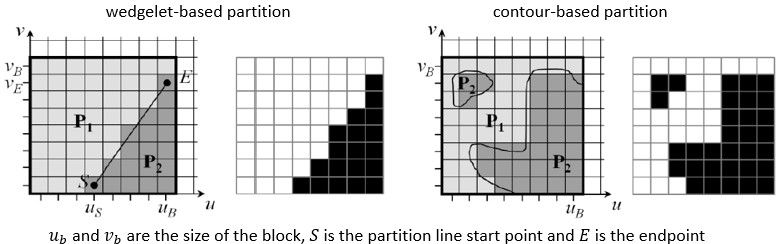
區塊的劃分工具可分為楔形波為基礎(wedgelet-based)以及輪廓為基礎(contour-based)的區域劃分方式,楔形波為基礎的劃分方式適用於當前編碼區塊,可被一條直線劃分為兩個常數區塊;輪廓為基礎的區域劃分,則是用於不規則外型的區塊,如圖7所示。
3D-HEVC Extension的Mode4則為利用當前編碼畫面的對應紋理畫面進行畫面間預測,如圖 8 所示。利用紋理圖進行二值化運算之後得到的結果,應用於當前深度編碼區塊,並以解碼端的紋理資訊進行輪廓之重建,即可節省編碼輪廓所需的位元。

| 圖8 : 3D-HEVC Extension畫面間預測模式 |
|
區域為基礎的編碼方式
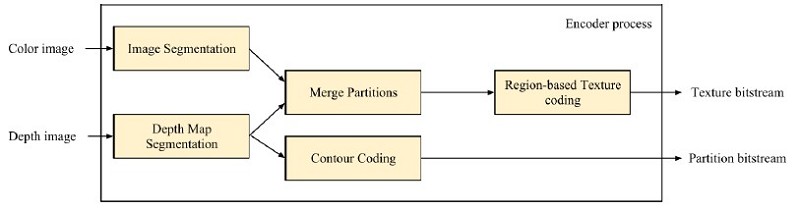
一張深度圖可以看成以多個輪廓及輪廓內深度值的區域所構成的影像。基於此特點,捨棄傳統以區塊為基礎(Block-based)的編碼架構,並提出以區域為基礎(Region-based)之編碼架構。
首先將愈編碼的深度影像進行區域切割為由相似深度值所構成的區域,並將區域邊界及內部的數值進行編碼。解碼時先進行邊界的重建後填入對應的深度值,即可重建完整的影像。由於完整的保存了深度影像的邊界資訊,故在合成視角時可得到較好的影像品質。
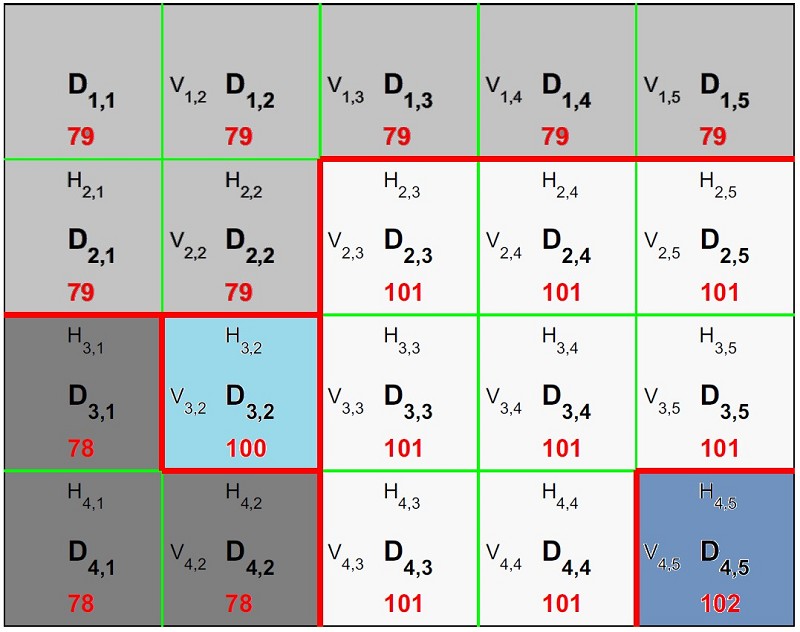
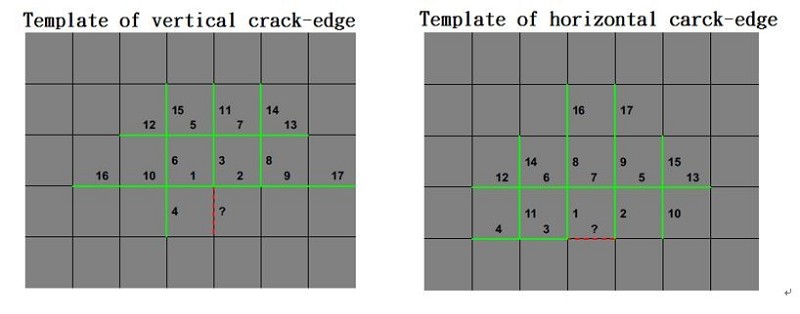
實驗顯示若兩相鄰像素的深度值不相等時,即存在著斷裂邊界(Crack Edge, CE)。運用畫面內CE資訊即可將深度影像區分成三個部分:邊界資訊CE、多個CE圍成之區域及區域內之常數數值,如圖 9所示。D為像素點座標,紅色數字則為該項數的深度值,V為垂直邊界而H為水平邊界,並以紅色及綠色表示該邊界是否啟用。
影像中的CE可使用二維的布林陣列表示,布林值0為不啟用、1則代表啟用邊界。因此CE的資料可看成是以一串的二元數值所構成的字串,其特性相當符合算術編碼(Arithmetic Coding)的編碼之特性(少量的符號以不相等之出現機率)。
同時由於物件邊界具有高度相似結構的特性,因此文獻提出以收集CE資訊後預測當前編碼的CE,並利用內容預測式算術編碼(Context-based Arithmetic Coding)進一步提升編碼效率減少熵(Entropy)。如圖10所示,綠色線段為已經編碼CE,紅色虛線為當前編碼CE,利用已知的CE預測編碼的方式使得資料分布更加集中,進而提升編碼效率。
以彩度邊界輔助深度資訊編碼的方式
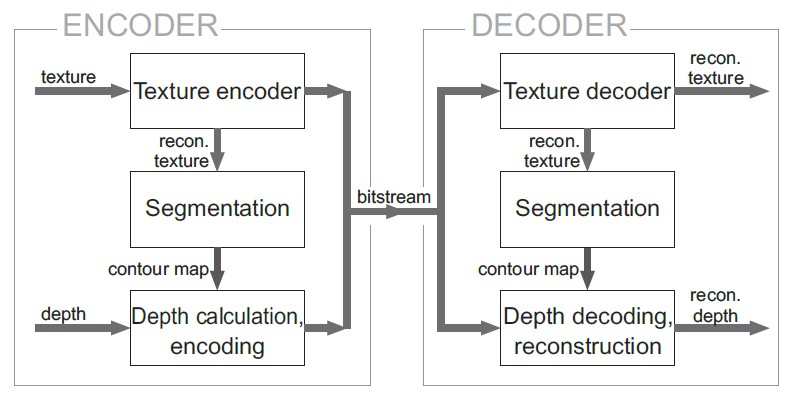
上一小節介紹了以區域為基礎的編碼方式,其編碼方式為直接進行深度影像的深度劃分,然而這樣的編碼方式仍需要傳送大量的深度資訊,所以文理影像與深度影像的邊界資訊有著極高的關聯性,如圖11所示。加上紋理影像在編碼端及解碼端都可以得到。
基於此論點,提出以彩度資訊輔助深度影像編碼的方式,只需傳送使用紋理影像所劃分出來的區域內深度值,即可在解碼端重建完整的深度影像。
以紋理資訊輔助深度資訊編碼的架構圖,如圖12所示。首先將重建後的紋理影像進行區域分割,並將分割的結果提供給深度影像運算所對應區域的深度值,並與區域劃分資訊整合為單一碼流傳送至解碼端。使用重建後的紋理影像進行區域劃分之原因,為確保解碼端和編碼端視使用相同的畫面來分割以免造成漂移誤差(Drift Error),確保系統的閉迴路特性(Closed-loop Property)。
若只單純使用紋理影像進行區域分割,可能會發生雖然深度影像有邊界但紋理影像對應區域之顏色較相近,導致紋理影像在進行區域分割時被歸屬在同一個區域,造成影像重建時有很大的差異,如圖13。
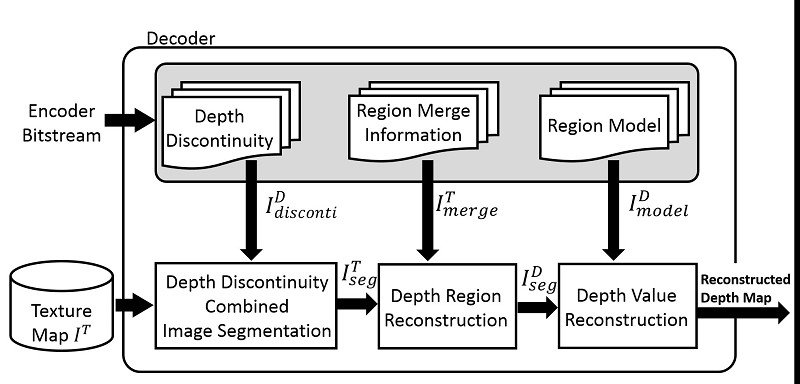
因此提出補足此缺點之編碼架構(圖14)下,以導入深度資訊之紋理區域劃分方法於深度資訊編碼系統,架構圖如15。先由深度圖取得深度邊界CE,並將支給予紋理圖協助其分割,若有啟用的CE即便紋理影像之特性相近,也不會進行合併,如此便可以良好的保持深度邊界資訊,如圖16所示。
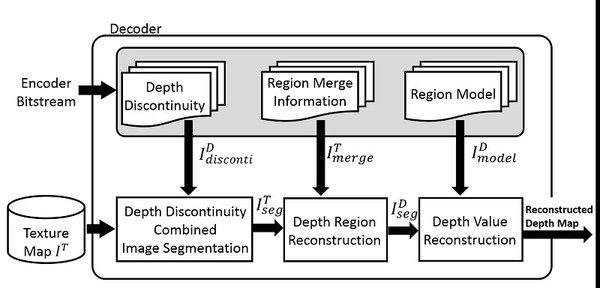
| 圖15 : 以深度邊界的紋理區域劃分方法於深度資訊編碼系統 |
|
?
深度資訊編碼的發展
自由視角視訊與三維視訊之原始影片採用格式為多視角彩度加深度(multiview view video plus depth, MVD),使用以深度資訊(depth information)輔助紋理資訊(texture information)進行視角合成的技術。
傳送端僅送出特定視角的紋理與相對應的深度資訊,以節省傳送所有視角所需的成本,未傳送的部分則以接收之資訊進行合成,其中深度資訊準確性會明顯影響合成視角的品質。
深度資訊記錄了場景物件與攝影機的距離,相較於呈現色彩差異的紋理資訊,深度資訊所記錄的為場景中各物件之空間位置關係,可用於虛擬視角合成時選取參考畫面之依據,應用於自由視角視訊與三維視訊,可使得最後的虛擬視角合成成果更加精確。
儘管MVC技術以捨棄部分視角資訊的方式減少傳送成本,然而在減少了紋理資訊的同時,亦增加了深度資訊的負擔,因此深度資訊的編碼與壓縮即成為重要議題,自2008年MVC技術制定完成後備受重視,至今仍有需多相關研究進行。
於2013年制定完成之高效率視訊編碼(High-EfficiencyVideo Coding, HEVC),亦於其參考軟體提供針對深度資訊特性修改的編碼擴充工具3D-HEVC Extension,足見傳統編碼架構應用於深度資訊有其不足之處。
影像編碼技術可以運用在數位電視、行動視訊、影音串流等各項新興多媒體服務中,而且都具有極高的應用價值。現階段數位科技蓬勃發展使得編碼技術日趨重要,但如何在更有效率的形況下達到良好的編碼品質,是目前最重要的課題。
(本文作者許庭瑋任職於凌群電腦軟體工程師)
資料來源
[1] HEVC https://en.wikipedia.org/wiki/High_Efficiency_Video_Coding
[2] M. Tanimoto, “Free Viewpoint Television - FTV”, Picture Coding Symposium 2004, Session 5, December 2004.
[3] 3D- HEVC?
https://blog.csdn.net/tianzhaixing2013/article/details/21248073
[4] ITU-T and ISO/IEC JTC1, “Joint draft 8.0 on multi-view video coding,” JVT-AB204, July 2008.
[5] P. Merkle et al., “Multi-view video plus depth representation and coding,”in ICIP, Oct 2007.
[6] ITU-T and ISO/IEC JTC1, “Joint draft 8.0 on multi-view video coding,” JVT-AB204, July 2008.
[7] K. Muller, “3D video coding with depth modeling modes and view synthesis optimization, ”Signal & Information Processing Association Annual Summit and Conference, p.p. 1-4, 2012.
[8] J. Hanca ea al., “Segmentation-based intra coding of depth maps using texture information,”Digital Signal Processing, pp. 1-6, July 2013.
[9] M. Maceira et al., “Fusion of colour and depth partitions for depth map coding,”Digital Signal Processing, pp. 1-7, July 2013.