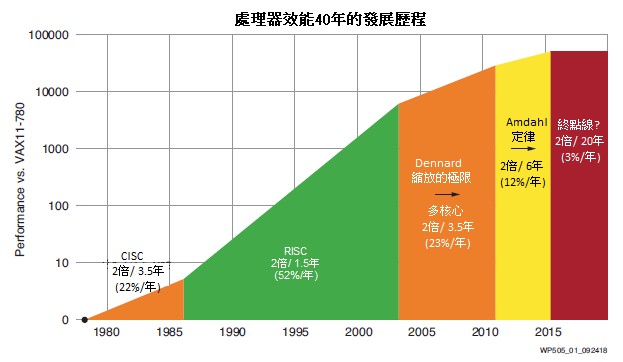
近期在半導體製程領域湧現的技術挑戰阻礙了傳統上通用(one-size-fits-all)型 CPU純量運算引擎的擴展。如圖1所示,半導體製程頻率縮放的變化,迫使標準運算單元愈發趨於並行[1]。
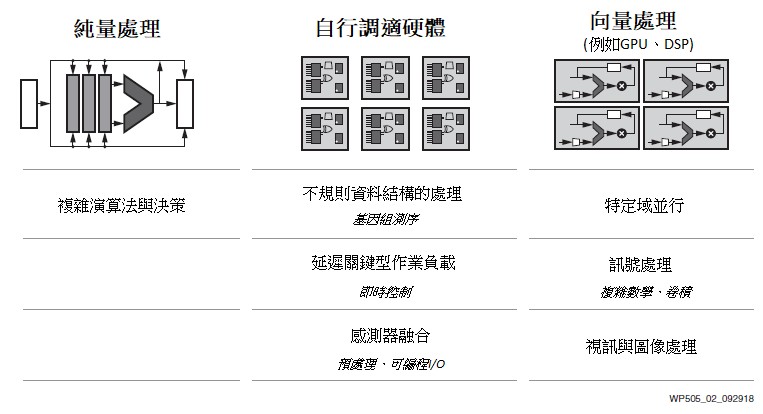
因此,半導體工業正在探索替代特定領域的架構,包括以往被歸入特定極端效能應用的部分,如採用向量的處理(DSP、GPU)和完全並行可編程的硬體(FPGA)。問題在於,哪種架構最適合哪項任務?
‧純量處理單元(例如CPU)在具有不同決策樹和廣泛資料庫的複雜演算法中非常有效,但在效能擴展方面受到限制。
‧向量處理單元(例如DSP、GPU)在一組更窄的可平行運算函數集上效率更高,但由於記憶體階層結構不靈活,它們會受延遲和效率的影響。
‧可編程邏輯(例如FPGA)可以精確地根據特定的運算功能客製,這使它們在延遲關鍵型即時應用(例如汽車駕駛輔助)和不規則資料結構(例如基因組測序)方面表現最佳,但演算法的更改在傳統上要花幾個小時來編譯,而不是幾分鐘。
參見圖2。
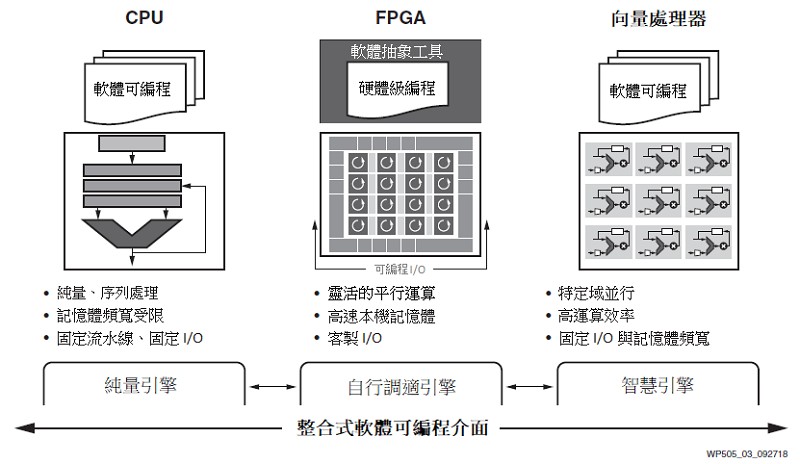
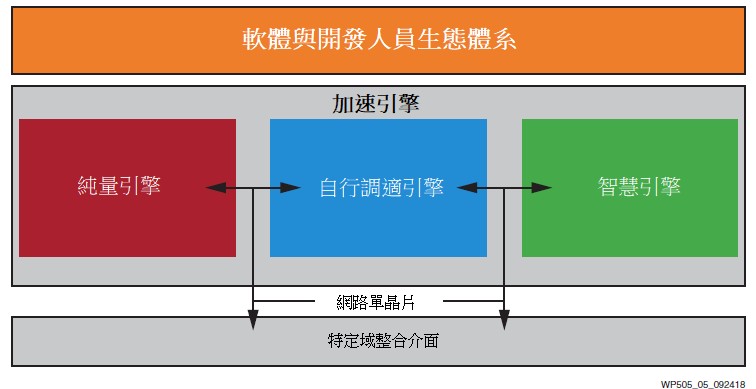
為因應這一問題,賽靈思推出了一個革命性的新異質運算架構,即自行調適運算加速平台(ACAP),它囊括三大方面的優勢,提供了與下一代可編程邏輯(PL) 緊密耦合的世界一流的向量與純量處理單元,將一切與高頻寬網路單晶片(NoC) 聯通,提供對所有三種處理單元類型的記憶體映射存取。這種緊密耦合的混合架構比任何一種單獨架構的實現,都支援更高的客製水準和效能提升(圖3)。
要想在效能上有如此大的提升,就必須對工具進行類似的大幅改進,並重點關注易用性。ACAP在設計上不需要RTL流,可以開箱即用。ACAP原生支援軟體編程有助於開展採用C和採用框架的設計流程。這些元件具有整合Shell,包括具有整合型DMA、NOC和整合型記憶體控制器的快取記憶體一致性主機介面(PCIe或CCIX技術),進而避免了開展RTL工作的需求。
新的ACAP架構在易用性方面也帶來了顯著改善。它通過一個統一的工具鏈為程式設計,提供了一個完全整合的記憶體映射平台。賽靈思工具鏈針對各類開發人員支援多種輸入方式。例如,某些應用(如AI機器學習推論)可以在框架級別(例如Caffe、TensorFlow)進行編碼;其他應用可以使用預先最佳化的函式庫(例如5G無線電濾波器)用C語言進行編碼。傳統型硬體開發人員仍然可以通過傳統的RTL輸入流,將他們現有的RTL移植到ACAP。
本文審視了由傳統採用CPU的運算模式開展變革的需求,詳細探討其他選項,並介紹了賽靈思Versal ACAP-一款異質運算平台。
ACAP的三大主要優勢包括:
1.軟體可編程性—能夠通過軟體抽象工具鏈快速開發最佳化應用。
2.加速—指標涵蓋廣泛的應用,包括人工智慧、智慧型網路介面卡、高密度儲存、5G無線、自動駕駛汽車、高級模組化雷達,以及兆位元光纖網路。
3.動態自行調適重配置—能夠重配置硬體,實現毫秒間加速新的負載。
ACAP:針對並行異質運算的軟硬體最佳化
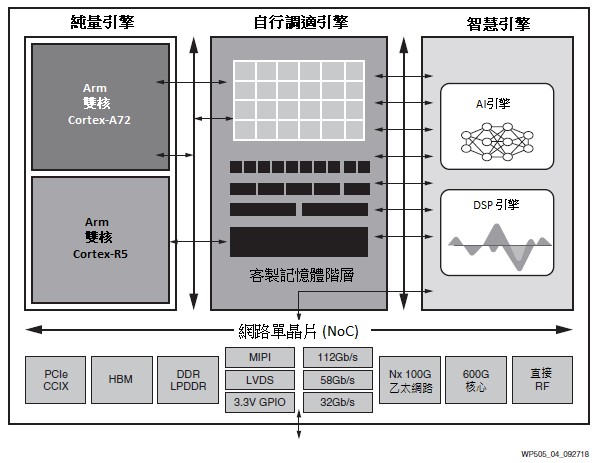
ACAP的特點在於它結合新一代純量引擎、自行調適引擎和智慧引擎。NoC通過記憶體映射介面將它們相連,總頻寬為1Tb/s+。除了NoC以外,可編程邏輯(和整合型RAM模塊)支援的大量記憶體頻寬,能夠支援可編程記憶體架構針對單個運算任務進行階層最佳化(進而避免其他採用快取記憶體運算單元固有的高延遲和延遲不確定性)。參見圖4。
純量引擎採用雙核Arm Cortex-A72構建,與賽靈思上一代Arm Cortex-A53核心相比,每核單執行緒效能提高了2倍。高階的架構和7nm FinFET製程的功耗相結合,DMIPs/WAT與先前的16nm落實的方案相比提高了2倍。基於賽靈思目前在汽車產業大量部署的經驗,經ASIL-C認證的(1)UltraScale+ Cortex-R5純量引擎結合額外的系統級安全特性向7nm遷移。
自行調適引擎由可編程邏輯和記憶體單元組成,與新一代業界最快的可編程邏輯相連。除了支援原有設計之外,還可以重新編程這些結構,以形成針對特定運算任務客製的記憶體階層。與最新的GPU和CPU相比,賽靈思智慧引擎可達到更高的迴圈效率和更高的單位運算記憶體頻寬。這是最佳化邊緣延遲與功耗,以及最佳化核心絕對效能的關鍵。
智慧引擎由一組創新的超長指令字(VLIW)和單指令、多個資料(SIMD)處理引擎以及記憶體構成,彼此間的互聯速度和儲存頻寬均為100Tb/s。這使機器學習和數位訊號處理(DSP)應用的效能提升了5 - 10倍。
如表1所示,這些運算函數以不同的比率和大小混合,構成了Versal元件產品組合。
表1: Versal 元件產品組合、市場及重要特性
|
Versal 產品組合
|
主要市場
|
重要特性
|
|
Versal AI核心
|
資料中心、無線
|
最高水準智慧引擎運算
|
|
Versal AI 邊緣
|
汽車、無線、廣播、A&D
|
緊密熱度範圍下高效智慧引擎數降至 5W
|
|
Versal AI RF
|
無線、A&D、有線
|
直接 RF 轉換器與 SD-FEC
|
|
Versal Prime
|
資料中心、有線
|
帶整合型 Shell 的基準平台
|
|
Versal Premium
|
有線、測試與測量
|
搭載最高水準自行調適引擎的高階平台,112G SerDes 和 600G 整合 IP
|
|
Versal HBM
|
資料中心、有線、測試與測量
|
帶 HBM 的高級平台
|
賽靈思自行調適運算加速平台(ACAP)結合了向量、純量和自行調適硬體單元,提供了三大引人注目的優勢:
‧ 軟體可編程性
‧ 異質加速
‧ 靈活應變能力
軟體可編程性
由自行調適晶片支援的自行調適加速
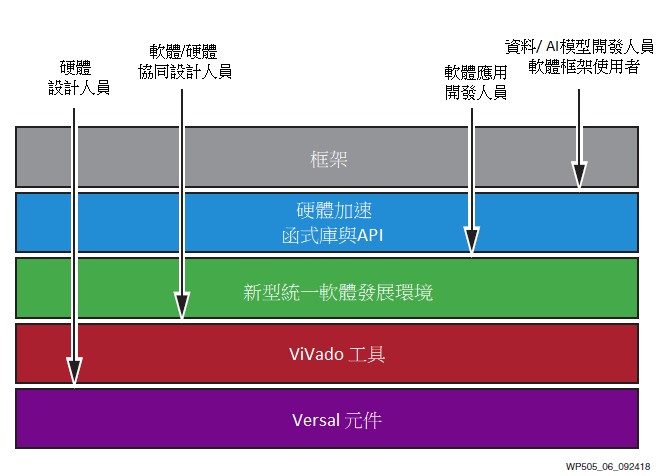
Versal ACAP提供自行調適加速硬體,易於在軟體中進行編程。無論任何應用類型,異質引擎都支援軟體應用的最佳水準加速。智慧引擎能夠加速機器學習和常用的經典DSP演算法。自行調適引擎內的新一代可編程邏輯對平行演算法進行加速。多核CPU為剩餘的應用需求提供了全面的嵌入式運算資源。整個Versal 元件在設計上便於使用軟體程式設計,無需具備硬體專業知識。參見圖5。
‧ 資料和AI科學家可以部署在標準軟體框架中構建的應用,並使用Versal ACAP為應用達到數個量級的加速。
‧ 軟體應用開發人員使用賽靈思統一軟體發展環境,無需硬體專業知識,就可以使用Versal ACAP加速任意軟體應用。
‧ 硬體設計人員可以繼續使用Vivado Design Suite進行設計,同時使用 Versal平台的整合I/O介面和NoC縮短開發時間。
參見圖6。
專用硬體,提高易用性和應用效率
自行調適介面邏輯使對外接介面的存取變得容易,這包括到外部主機處理器的標準介面。在資料中心應用中,軟體應用通常駐留於主機CPU上,而不是嵌入式微處理器上。連接主機CPU和Versal平台可編程資源的介面稱為Shell。整合型Shell包括完全相容型快取記憶體一致互聯,適用於加速器(CCIX)或主機 PCIe Gen4x16介面、DMA 控制器、快取一致性記憶體、整合型記憶體控制器、高階功能性安全和安全功能。
NoC有助於每個硬體元件和軟IP模組間輕鬆地相互存取,或通過記憶體映射介面存取軟體。它提供了一個標準化、可擴展的硬體框架,使異質引擎和介面邏輯之間能夠進行高效通訊。
異質加速
雖然可編程邏輯(FPGA)和採用向量的(DSP、GPU)近來已展示出明顯高於 CPU的效能提升,但只有當開發人員利用Versal ACAP的多個類型運算單元支援緊密耦合的運算模型時,ACAP架構真正的優勢才會成為人們關注的重點。在這種架構下,三單元合力可遠超僅僅三倍的功效。
表2總結了Versal ACAP元件為各類市場提供的優勢。
表2:Versal ACAP與目標市場
|
市場
|
基準
|
與 CPU 對比
|
與 GPU 對比
|
與 FPGA 對比
|
備註
|
|
資料中心
|
圖像辨識(推論)——延遲敏感
|
43倍
|
2倍
|
5倍
|
GoogLeNet v1(不限制批次處理大小)
|
|
圖像辨識(推理)——2ms延遲
|
不適用
|
8倍
|
?
5倍
|
GoogLeNet v1(< 2 ms)CPU 延遲下線 5ms
|
|
風險分析
|
89倍
|
不適用
|
>1倍
|
用於利率互換Maxeler 結果的風險價值 (VaR)
|
|
基因組學
|
90倍
|
不適用
|
>1倍
|
人類基因分 Edico基因組結果
|
|
彈性搜索
|
91倍
|
不適用
|
>1倍
|
1TB資料BlackLynx結果延遲降低91倍
|
|
無線5G
|
16x16 5G遠端無線電
|
不適用
|
不適用
|
>5倍
|
為5G遠端無線電提供 >5倍的無線電頻寬
|
|
波束成形
|
不適用
|
不適用
|
>5倍
|
>5倍的運算能力
|
|
A&D雷達
|
DSP TMAC
|
不適用
|
不適用
|
>5倍
|
超過27TMAC
|
|
演算法反覆運算時間
|
不適用
|
不適用
|
>100倍
|
軟體可編程智慧引擎在幾分鐘內編譯完畢
|
|
汽車
|
低延遲推論(<2 ms)
|
不適用
|
3倍
|
15倍
|
ResNet50 Batch=1
AI引擎能更好地適應低延遲、安全關鍵型 ADAS和自動駕駛
|
|
外殼類型
|
1
|
2
|
4
|
ACAP產品組合是唯一能夠高效支援 <10W、20W、30W,以及後備箱安裝外殼的元件
|
|
有線
|
加密網路流量
|
不適用
|
不適用
|
4倍
|
ACAP對網路和加密 IP的整合使兆位元的單晶片成為可能
|
資料中心人工智慧:機器學習推論加速
隨著人工智慧開始在現代生活中普及,對提高運算效率的需求開始推動半導體領域的創新,但任何單一的方案都很難以達到最大效率的處理。在這方面,向量處理和可編程硬體之間的緊密耦合,具有無可比擬的價值。
運算單元(FP32、FP16、INT16、INT8等)的精度一直是人們關注的焦點,但對網路類型之間記憶體階層需求差異的忽視,導致眾多最新的人工智慧推論引擎,在不同網路上的效率急劇下降。例如,目前業界一流的機器學習推論引擎,需要4 個HBM記憶體(7.2 Tb/s 的外部記憶體頻寬)才能達到其最高效能,但它們採用緩存的記憶體階層效率僅為25-30%,並為即時應用帶來了顯著的延遲不確定性。解決方案就是用可編程記憶體階層強化智慧引擎執行的向量處理,精確地針對每種網路類型進行最佳化,並通過FPGA邏輯的大規模並行來落實。
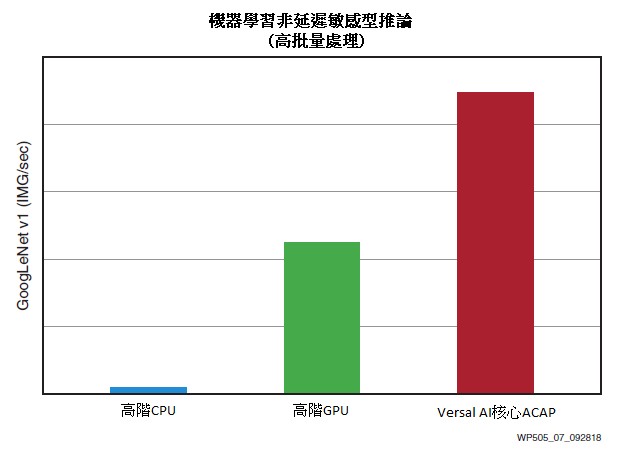
例如,GoogLeNet的Versal平台為非延遲敏感型應用提供了極高效能,比當今最高階的Skylake Platinum CPU(2)傳輸率高出43倍,比當前的頂級GPU [ 2] 效能高約3倍,並且功耗均更低(圖7)。
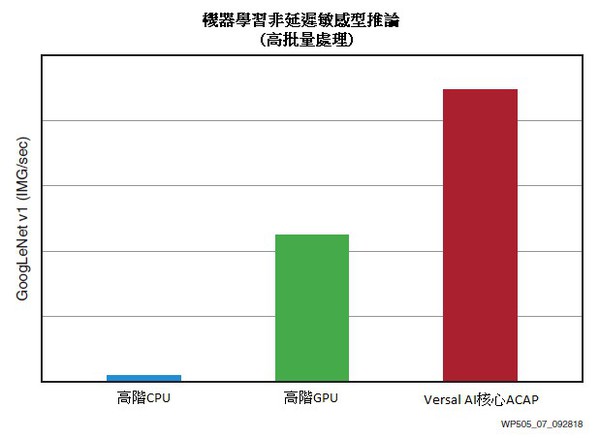
| 圖7 : GoogLeNet 效能(< 7ms延遲)= 比高階CPU效能高出43倍 |
|
隨著資料中心不斷深入地應用於神經網路,多個神經網路可以連結在一起,大大增加了對低延遲神經網路的效能需求。例如,即時口語翻譯需要語音轉換文本、自然語言處理、推薦系統、文本轉換語音,然後語音合成[2]。這意味著對於該應用,神經網路的總延遲預算增加了5倍。
隨著即時應用數量的不斷增加,對資料中心客戶而言,選擇一種可擴展的技術以滿足他們未來的需求極為關鍵。這就出現了兩種趨勢:
‧ 為提高軟體設計效率,確定性延遲變得愈發重要[3]。
‧ 隨著日益複雜的交互建模(人機交互、金融交易)和安全關鍵型應用(如汽車、工業應用)的增加,神經網路延遲要求日益嚴格。
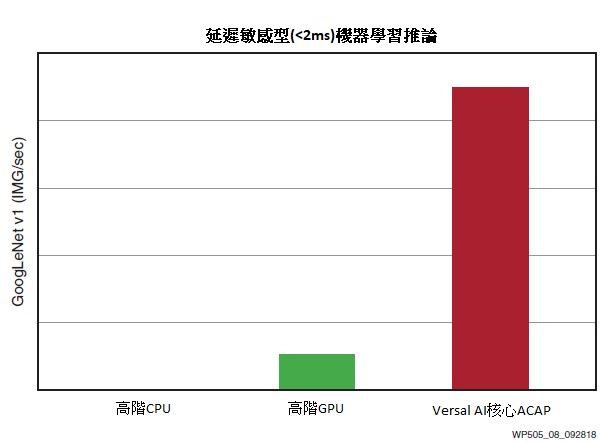
這兩個要求需要消除批次處理,這將導致採用CPU和採用GPU的解決方案的固定的、採用緩存的記憶體階層效能顯著下降。即使高階CPU延遲極限也高達 5ms,而一旦延遲在7ms以下,甚至是高階的GPU也會出現顯著的效能下降。僅有Versal ACAP能夠以可接受的效能達到低於2 ms延遲。參見圖8。
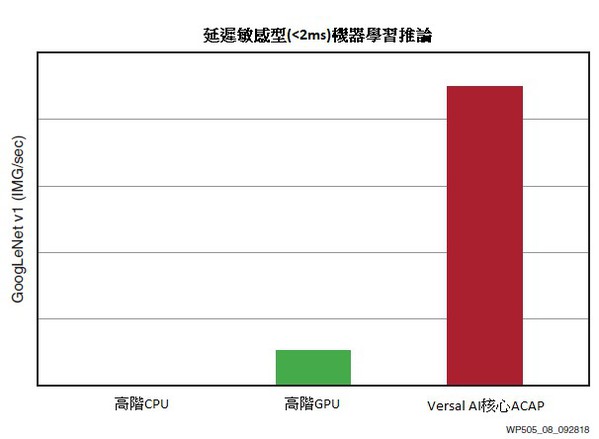
| 圖8 : GoogLeNet即時效能(< 2 ms延遲)=高出高階GPU(Nvidia)8倍 |
|
因此,採用ACAP的解決方案獨有的可編程記憶體階層,既提供了最高效能的機器學習推論效能,也提供了擴展性,因為未來的應用要求更低和更確定的延遲。
資料中心智慧NIC
網路介面卡(NIC)起初只是簡單的連接。隨著時間的推移,它們通過增加額外的網路加速(加密、管理程式網路卸載、虛擬開關)化身為「智慧NIC」。亞馬遜在Annapurna專案上取得了巨大的成功;它從CPU中卸載了所有的程式管理器功能,使100%的CPU週期都能用於產生收入的運算。
隨著智慧NIC的發展,賽靈思預計將出現三大優勢:能夠在資料中心乙太網路邏輯上動態分配和擴展作業負載,能夠運行任何運算加速功能的可重配置加速池(最大限度地利用雲端資源),以及能夠與網路資料平面一致運行運算功能。
賽靈思Versal ACAP元件支援將NIC功能與採用向量和可編程邏輯的混合運算引擎整合,所有這些功能都由賽靈思的網路IP和SerDes提供深度支援,包括用於新一代NIC to TOR(機架頂部)鏈路的單通道112G SerDes。
此外,可以在新的作業負載上動態地重配置或重新部署這些NIC資源。
表3:資料中心網路介面卡類型
|
?
|
描述
|
特性
|
實例
|
|
1 類
|
基礎連線性NIC
|
- 基礎卸載(校驗、LSO、RSS)
- 單根I/O虛擬化
- 某些隧道卸載(VXLAN、GRE0)
|
- Fortville
- ConnectX
- NetExtreme
|
|
2 類
|
用於網路加速的SmartNIC
|
- 加密/解密(IP安全)
- 虛擬開關卸載(OVS等)
- 可編程隧道類型
|
- 賽靈思 2 類
- LiquidIO
- Annapurna
- Innova
|
|
3 類
|
用於網路運算加速的SmartNIC
|
- 內聯機器學習
- 內聯視頻轉碼
- 資料庫分析
- 儲存(壓縮、加密、Dedupe)
|
|
資料中心儲存加速
長期以來,FPGA一直被用於儲存驅動器,來執行糾錯和寫調平任務。它們靈活的 I/O支援卓越的設計重用,在發展迅速的快閃記憶體技術界尤為關鍵。此外,眾多當前的資料庫搜索和加速設備都在驅動器附近採用了FPGA 的加速並獲得重大優勢。(通過將運算單元直接佈局在驅動器旁,可以獲得最大限度的效率。)
採用ACAP架構,驅動器和資料庫加速廠商可以直接在驅動器內(已使用FPGA)添加機器學習運算,從而將跨資料中心的資料移動(以及相關的延遲、功耗和運營開支)減少10倍。
5G無線通訊
無線使用者對頻寬無止境的渴求推動了無線產業「每10年10倍」的極速創新步伐。在2020年奧運會上,業界將開始首次公開展示第五代無線技術,稱為「5G」。一開始大部分都將構建於現有的賽靈思元件,特別是極為成功的16nm RFSoC元件上,它提供了三個關鍵優勢:
‧ 整合直接RF取樣速率ADC和DAC
‧ 整合LDPC和turbo軟決策前向錯誤修正(SD-FEC)碼塊
‧ 16nm FinFET製程技術帶來的低功耗DSP
隨著產業的發展湧現出兩大挑戰:以較低的成本向更寬的頻譜邁進,以及在無線電中增加機器學習推論技術,以增強光束引導演算法、增強使用者交接演算法和支援自癒網路。
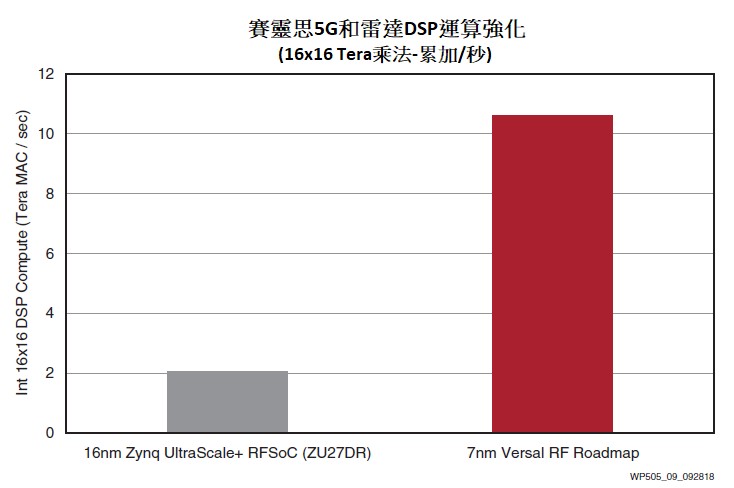
傳統意義上,一些無線廠商通過採用向量DSP的ASIC來降低成本。Versal ACAP 中加入了一個智慧引擎,很大程度上消除了ASIC和FPGA之間傳統的成本差距,因為它提供了超5倍的單晶片TMAC(圖9)。
因此,雖然16nm Zynq UltraScale+RFSoC可落實200MHz 16x16遠端無線電單元(RRU),但 7nm Versal元件產品規劃路線可以落實完整的800MHz 16x16 RRU(圖10)。
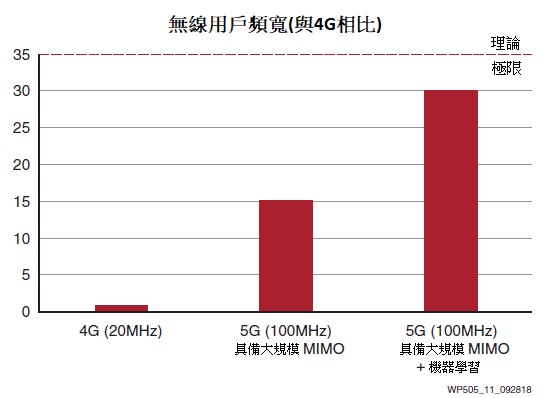
增加了高效的機器學習(具有框架級的設計流程),為採用ACAP的Versal產品組合開拓了一個全新的類型。這種技術可以增強光束引導和使用者交接演算法,比傳統的編程定義演算法高出2倍,接近理論極限的85%(圖11)。
賽靈思將所有四種關鍵技術彙聚在單個晶片:直接RF採樣ADC和DAC、整合式SD-FEC代碼、採用高密度向量的DSP以及框架可編程的機器學習推論引擎,打造出一款真正的5G晶載無線電。例如,圖12描述了ACAP架構彙聚經典無線需求和緊急AI/ML技術的能力的實例。RF波形分類器在認知無線電應用中將發揮重大作用,有助於提高無線電資源的利用率。使用AI機器學習技術,該演算法能夠將基線準確率提高38%,比公認技術的準確率高出20%。
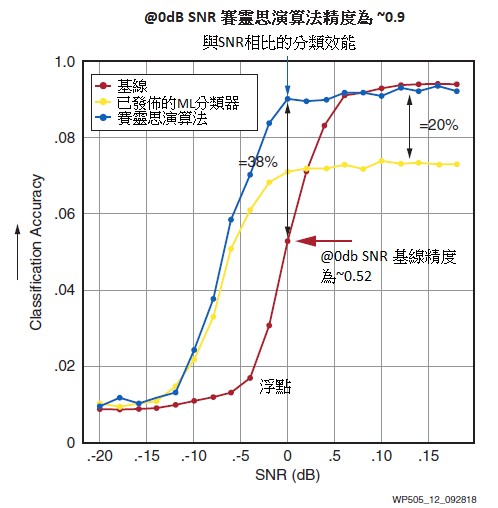
| 圖12 : 機器學習帶來的數位預失真(DPD)效率提升 |
|
航空與國防
FPGA的大規模並行DSP能力長期以來一直是許多國防領域雷達落實的支柱。然而,ADC技術的最新創新已將ADC取樣速率提高到每秒數萬兆次,這要求 DSP能力也取得相應地提高。
採用向量的強大DSP引擎與AI機器學習的融合,使航空與國防工業的革命性新產品,如先進的模組化雷達成為可能,由高頻波長驅動的天線間距要求採用極小的外形。賽靈思在單一封裝元件中,就能提供每秒兆位元的天線頻寬,以及多達 17 TMAC的INT24,或24 TFLOPS的32位單精確度浮點DSP。
汽車駕駛輔助(ADAS)
賽靈思在汽車、航空、衛星、醫療和商業網路系統領域的高可靠性和熱限制系統方面擁有歷史悠久的經驗。賽靈思技術經專門設計,以減輕SEU效應,並能在高達125°C的溫度下運行,結合對機器視覺和機器學習的關注,可靠性和品質方面的豐富經驗意味著,賽靈思技術原生適用於汽車駕駛輔助系統(ADAS)和未來的自動駕駛汽車技術。迄今為止,賽靈思已經針對各種汽車插槽交付超過1.5億個FPGA和SoC,並專門為ADAS應用供貨超過5,000萬個元件。汽車產業是賽靈思在過去兩年中增長最快的市場領域。
賽靈思針對汽車的可擴展Versal ACAP內含一個高能效純量引擎,該引擎具有雙核Cortex-R5S、可編程 I/O和低延遲、智慧AI引擎,該引擎支援節能、功能性安全、AI強化的自動駕駛解決方案,與當今市面上採用FPGA,ASIL-C認證的ADAS解決方案相比,INT 8機器學習效能提高了15倍。
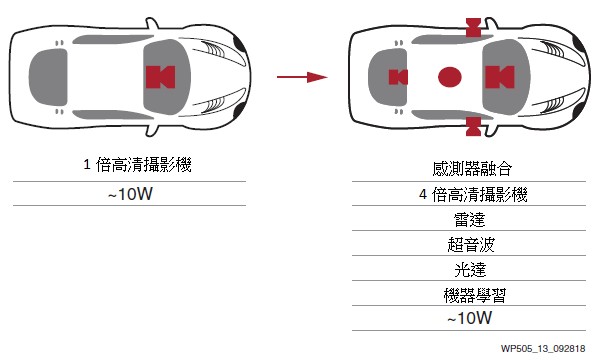
此外,通過空中硬體更新對整個元件進行重新程式設計的能力提高了系統在現場的通用性,從而提高了客戶價值。最後,賽靈思可編程I/O為廠商提供了變更感測器類型的靈活性和適應性,無需承擔等待ASSP或GPU重設計帶來的延誤與成本(圖13)。
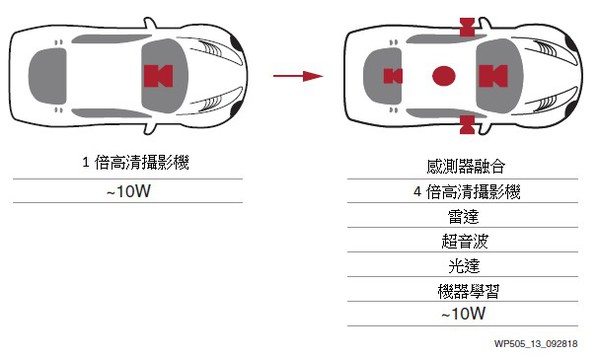
| 圖13 : 賽靈思ACAP元件支援低功耗感測器融合 |
|
汽車領域創新頻現,重點在於要選擇一種可跨多個平台提供代碼可攜性和可擴展性的處理元件組合,從5-10W擋風上安裝的前置攝影機設計到20-30W座艙中央模組,再到100W+液體冷卻後備箱安裝的超級電腦,所有這些都具有相同的程式設計模型(表4)。
表4:賽靈思汽車產品覆蓋面與友商對比(同一程式設計模型)
|
?
|
(10W)
智慧端點(例如前置攝影機)
|
(20W)
中央模組(基本型、無源散熱)
|
(30W)
中央模組(高級型、風冷)
|
(100W+)
後備箱超級電腦(液體冷卻)
|
|
賽靈思
|
·
|
·
|
·
|
·
|
|
NVIDIA
|
?
|
?
|
·
|
·
|
|
Intel MobilEye
|
·
|
?
|
?
|
?
|
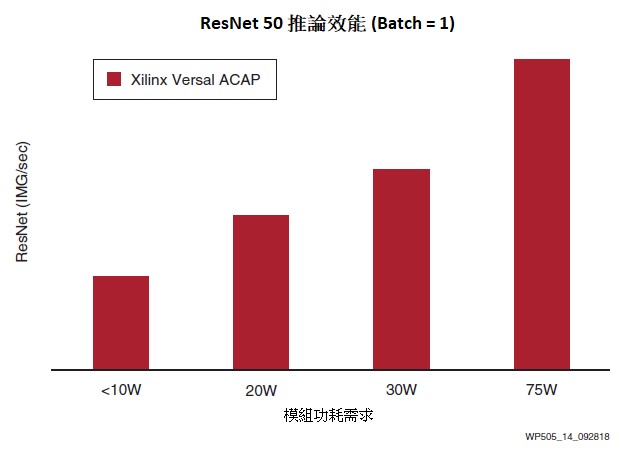
在考慮高速行駛的車輛時,延遲是一大關鍵處理效能因素。在60MPH(100KPH) 的速度下,不同ADAS系統的反應時間上,幾十毫秒的差異會對系統的有效性產生重大影響。隨著自動駕駛汽車技術的日益普及,或需將多個神經網路串聯執行複雜的任務,這加劇了GPU依賴大規模批次處理的問題。因此,賽靈思最佳化了AI邊緣系列,使其能夠在低批次處理規模下以極高的效率運行(圖14)。
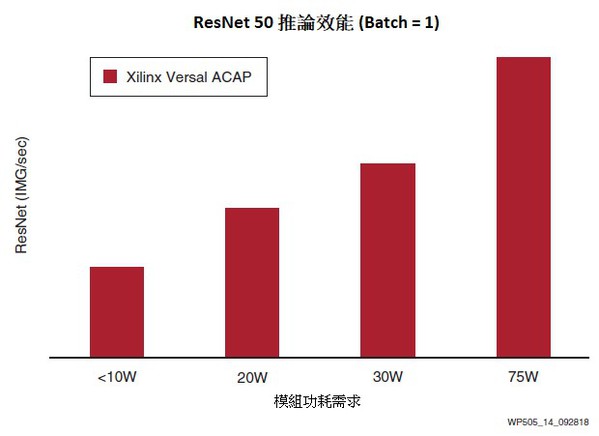
| 圖14 : 低延遲安全關鍵型 Versal 產品組合覆蓋面 |
|
當今汽車ADAS/AD系統對高解析度攝影機的要求越來越高。運算需求根據像素進行擴展,這意味著來自高畫質攝影機(1080x1920)的圖像,比資料中心標準的 224x224圖像明顯需要更強大的運算能力。高運算效率的賽靈思Versal元件擴展性定位獨到,可滿足更高的解析度要求。
有線通訊
今天,每一條互聯網流量都經過多個賽靈思FPGA處理。FPGA長期以來一直充當「膠水邏輯」,使網路硬體能夠適應網路營運商不斷變化的需求。賽靈思在先進的112G SerDes技術領域的領導地位,使業界能夠第一次落實新的協議和嚴格的光、銅電纜和底板標準,以及現有的58G PAM4和32G NRZ協定,例如標準應用前時期的PCI Express Gen5。豐富的IP組合使標準化介面的整合成為了可能,並降低了成本和功耗。賽靈思豐富的IP組合支援客戶進行混合和匹配,從而在硬體級達到差異化。
隨著網路運營商不斷提出新的功能要求,快速編碼和現場更新自行調適硬體的能力比依賴原有ASSP的硬體更具優勢。
賽靈思Versal ACAP具有與新一代600G波長規劃一致的突破性整合IP水準,完全支援乙太網路和OTN標準10G、25G、50G和100G SerDes速率,包括:
‧ 10/25/40/50/100GE MAC/PCS/FEC,具有±1ns IEEE STD 1588時間戳記、eCPRI和TSN支援
‧ 600G FlexE核心可達到低至10G通道和高密度400GE/200GE/100GE MAC/PCS/FEC
‧ 600G線速加密引擎,支援MACSEC和IPSEC,以及批量AES-GCM加密
‧ 整合FEC的600G Interlaken用於PAM4通道
‧ 用於DOCSIS電纜 LDPC應用的SD-FEC
這些 SerDes 的顯著改善能夠支援:
‧ 用於OTN和邊緣路由器應用的單晶片1.0Tb/s+ 網線卡與商用ASSP相比具有類似的功率,但靈活性更高
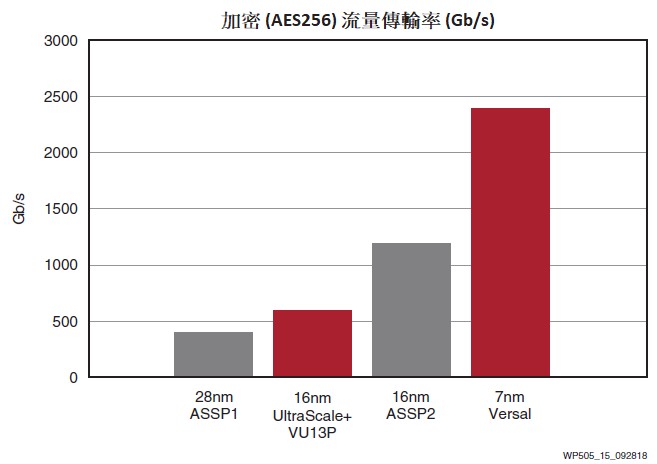
‧ 單晶片2.4Tb/s+ 加密資料中心互連(DCI)機架安裝設備,每個RU有多個實例(圖15)
‧ 400Gb/s+ 纜線數據機終端系統(CMTS),每使用者獨有加密隧道,針對高階商業和住宅服務。
靈活應變能力
可編程邏輯技術的一大優勢在於現場硬體升級的能力。在今天的4G無線和光纖網路,以及汽車自動駕駛產品中已經廣泛部署。
賽靈思Versal ACAP通過支援更高級別的抽象(C 或框架級介面)和8倍速的部分重配置,達到了更快的內核倒換,進而擴展了這一領域內的升級功能。
自行調適硬體
長期以來,FPGA的核心價值主張一直是在現場進行設計變更的能力。無論是糾正錯誤、最佳化演算法或添加全新的功能,可編程邏輯提供了所有其他半導體選項不具備的獨特靈活性。
賽靈思Versal ACAP將這一概念進一步推進,使配置時間加快了近一個數量級,達到以毫秒為單位的部分位元流的動態倒換,讓硬體具有軟體的靈活性。
可編程記憶體階層
作為一種補充,自行調適硬體強化了Versal ACAP,進而最佳化了ACAP架構新功能的效率。
可編程邏輯的最大優勢之一是能夠重配置記憶體階層,從而針對不同的運算負載進行最佳化。例如,即使在專注圖像辨識的神經網路範圍內,每幅圖像的記憶體佔用和運算操作,也會因演算法的不同而帶來很大的差異。可編程記憶體架構支援對可編程邏輯進行調整,以最佳化它所支援的每個網路之運算效率。
因此,當結合向量處理器和可編程邏輯來落實神經網路時,Versal ACAP可達到領先的GPU近2倍的運算效率,並實現了固定記憶體階層的向量處理。參見圖16。
動態重配置
該元件固有的可編程性將為某些成本敏感的即時應用帶來優勢,在多個邏輯功能之間複用一組可編程硬體,而且自行調適引擎部分重新程式設計時間低至亞毫秒水準。在資料中心中,與GPU這樣的更受限的向量處理器相比,這意味著Versal ACAP元件能夠執行傳統上由CPU執行的更廣泛的功能。(圖17[4])
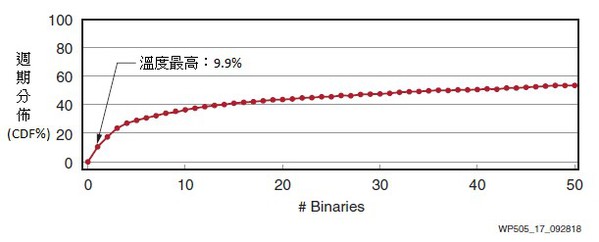
| 圖17 : 由於資料中心作業負載經過廣泛分配(Kanev),再不會產生「殺手應用」 |
|
總結
近來湧現的技術挑戰迫使業界跳出同構通用型CPU純量處理解決方案,進而探索新的發展方向。向量處理(DSP,GPU)能夠解決部分問題,但由於記憶體頻寬的使用效率不高,致其在傳統的擴展中遭遇挑戰。傳統的FPGA解決方案提供了可編程記憶體階層,但傳統的硬體流程一直是推廣的阻礙。
該解決方案將所有這三大要素與一個新的工具流相結合,通過單個自行調適運算加速平台(ACAP),提供了從框架到C到RTL級編碼的各種不同抽象。
僅針對可編程邏輯一項,ACAP架構就顯著拓展了其能力。可編程邏輯和向量處理單元的混合能夠支援資料中心、無線網路、汽車駕駛輔助和有線通訊中應用的運算量突破性的增加。
強大的AI機器學習運算、高階網路,以及加密IP的結合有助於針對資料中心落實新一類的自行調適運算加速引擎以及智慧NIC。
將預製的人工智慧機器學習推論與密集DSP和直接RF採樣ADC/DAC相結合,與採用DSP的自開發ASIC相比,能將5G無線電的傳輸率翻一番,使 LIDAR、雷達和視覺感測器在汽車駕駛輔助(ADAS)應用中的單晶片感測器融合成為可能。
參考文獻
[1] J. Hennessy, D. Patterson, Computer Architecture: A Quantitative Approach (6th Edition, 2019).
[2] Nvidia, Nvidia AI Inference Platform: Giant Leaps in Performance and Efficiency for AI Services, from the Data Center to the Network’s Edge (2018). Retrieved from nvidia.com, 2018.
[3] N. Jouppi, C. Young, N. Patil, et al., In-Datacenter Performance Analysis of a Tensor Processing Unit?. In International Symposium on Computer Architecture (ISCA 2017). Retrieved from arxiv.org, 2018.
[4] S. Kanev, J. Darago, K. Hazelwood, et al., Profiling a warehouse-scale computer (2015). Retrieved from google.com, 2018.