在當今AI潮流之下,企業和年輕人如何出人頭地呢? AI機器人AlphaGo打敗天下無敵手,已經出人頭地了。人們何不向AlphaGo及AlphaGo Zero學習呢?
AlphaGo懂得如何征服限制面對的巨大不確定性棋局,因而超越了人類頂尖高手。當學習AlphaGo如何探索機會之後,創客就懂得面對AI的不確定市場,而企業就會像AlphaGo一樣,超越頂尖的人類競爭對手,出人頭地了。
傳統上,人類的學習偏重於「利用」所學的知識發揮所長,解決問題。如果人類(如創客)能從AI強化學習得到啟示,強化探索能力,則人人能探索更多的可能,得到更多的機會。
在高度不確定性的環境裡,唯有懂得降低風險,才敢大膽探索、提高機率勝出。一旦選擇了創客/創業之路,若能向AlphaGo學會探索機會的方法,將會協助您在創業路途上鴻圖大展。
強化學習:探索和利用之間找到平衡
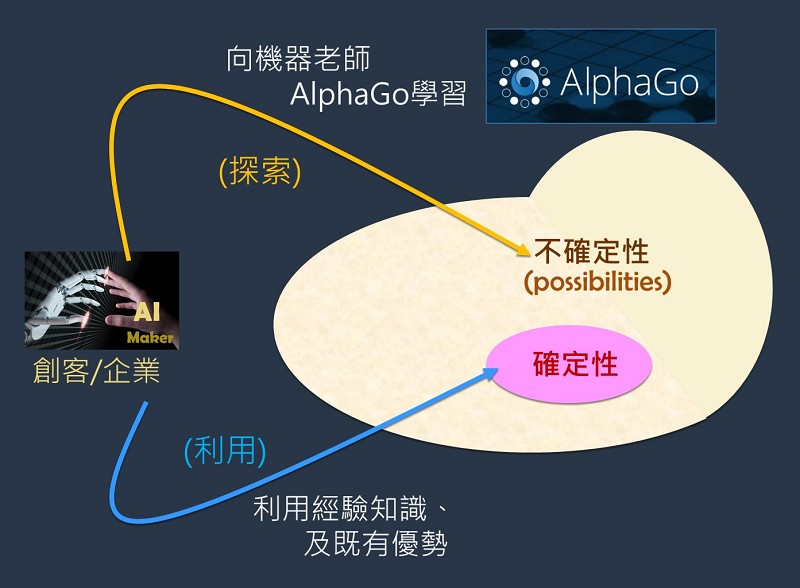
強化學習(Reinforcement Learning)的演算法又稱為「近似動態規劃」(approximate dynamic programming,ADP) 。它在探索(在未知的領域)和利用(現有知識)之間找到平衡。探索(exploration)就是:嘗試以前從未想過或做過的事情,以求獲得更高的報酬。利用(exploitation)就是:做當前條件下能產生最大回報的事情(圖1)。
例如,假設在您家的附近有十個餐館,到目前為止,您僅在其中的八家餐館吃過飯,瞭解了這八家餐館中哪家的是最好吃的。例如有一天,女朋友來訪,您想請她去最棒的餐館晚餐,請問您會如何選擇餐館呢?在這個例子裡,「利用」就意味著您帶她去所知道的八家中最好吃的餐館;而「探索」則是帶她去您從沒吃過的第九家或第十家餐館晚餐。
如果您選擇八家中最好吃的餐館,那麼也許第九家或第十家比這八家都好吃很多呢?反之,如果您選擇第九家或第十家,也許這兩家可能比那八家都難吃呢!
那麼,您該如何選擇?這就是「探索-應用」困境(exploration-exploitation dilemma)。強化學習更接近生物學習的本質,一個標準的強化學習演算法必然要包括探索和利用,強化學習更接近生物學習的本質。Google的專家們(即人類老師)已經把這種「探索和利用」最佳平衡的技巧(演算法)教給了AlphaGo (機器學生),讓AlphaGo及AlphaGo Zero超越了人類的圍棋頂尖高手。
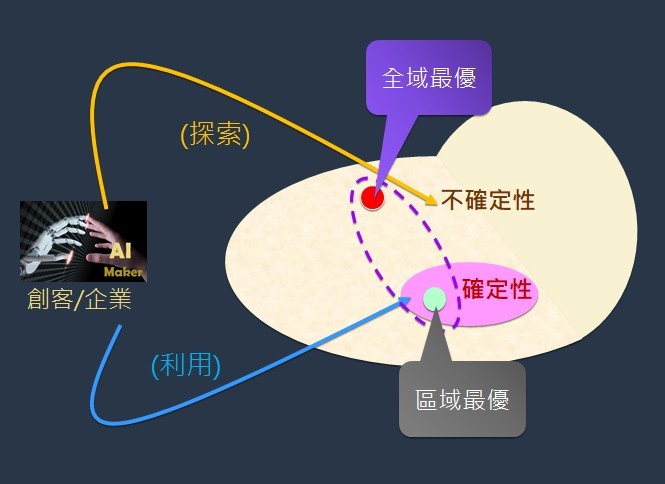
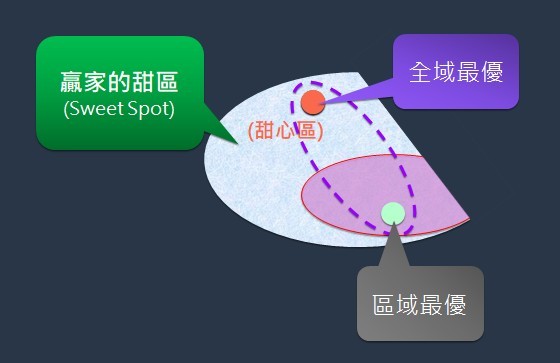
傳統的人類學習是學以致用(利用所學)為依歸,由於常常受限於(現有知識),無論是人類或機器學生都只能得到區域最優(local optima)。
因此,無論是機器學生或人類學生,一旦具有強化學習能力,都能大大提升其探索未知機會的能力,有信心去探索更大的狀態空間,而得到全域最優(global optima),讓學生們成為AI時代的大贏家,人人能探索更多的可能,也捕捉到更多的好機會。
懂得避風險,才敢大膽探索、才有熱情創新
大膽探索的背後,必須有效降低風險,這是AI時代人類可以向機器學習的重要一課。AI強化學習已經把這種「探索-利用」最佳平衡的演算法效益發揮出來,然而搭配著一種降低風險的策略。AlphaGo的目標總是將獲勝機率最大化放在第一位,它會透過尋找確定的搜索途徑實現最低風險的獲勝機會。例如,AlphaGo的行為會傾向為了取勝而放棄更多贏棋子數,只為了降低不能取勝的風險。
AlphaGo 的蒙地卡羅演算法給出的是搜索之後的勝率評估,然後AI會根據這個勝率來選擇落子點,唯有懂得避風險,才敢大膽探索、才有熱情創新。因而,AlphaGo能在高度不確定性的圍棋棋局中,超越人類高手。俗語說,商場如戰場,它們都跟圍棋競賽一樣具有高度的不確定性,因而人們(如企業家)將可從AlphaGo學會如何在商場上,善於面對如圍棋棋局中高度不確定性的市場環境中,超越其他的人類競爭者!
與不確定性共舞
向AlphaGo學習,有助於提升人們的避風險能力和信心,以便更具備創新精神。就如同下述的這句名言:
“When you focus on problems,you’ll have more problems. When you focus on possibilities,you’ll have more opportunities.”(當您專注於問題時,您就會有更多的問題;當您專注於可能性時,您就會有更多的機會。)
當人們一直專注於問題時,是基於過去經驗,評估具有現實條件支撐,力求化解問題、或避免問題發生的機率性,在心中逐漸萌生具有高度的明確感。這種機率性思維而得到地明確感稱為「機率性明確感」。
大家都知道,當面對不確定的情況時,人們總是需要明確感,才會安心。大多數人習慣於機率性思維,一直專注於問題,力求化解問題或避免問題發生的機率性,於是在心中逐漸萌生具有高度安心的明確感。
透過這種機率性思維而得到的明確感稱為「機率性明確感」,但是,常常會基於經驗和現實而過濾掉機率小的可能方案,而失去許多的機會。
「可能性明確感」試圖涵蓋未來各種可能的機會,避免基於經驗和現實而過濾掉或機率小的可能方案。然後,逐步探索經驗和現實進行否證而去蕪存菁,漸進提升心中的明確感,亦即面對複雜和新的未知世界,培養先容納內心的不確定性,規劃方案並採取行動試驗性(試錯),逐漸提升明確性和信心。
可能性(possibility)意味著機率性(probability)很小的事件,有人稱之為「黑天鵝」。它的出現,初期並不起眼,而是經過「一段時間」逐漸產生乘數效果的巨大效應。為什麼會是「當您專注於可能性時,您就會有更多的機會」呢? 因為上述的「一段時間」是一項寶貴的資產,例如,長榮集團創辦人張榮發就是洞悉到物流集裝箱(黑天鵝)而獲得寶貴時間,並且預作準備,因而獲得更多機會,而後來才進入的競爭者,就因缺乏時間資源而失去競爭力。
大多數人習慣於機率性思維者,他們常常成為失去寶貴時間的後知後覺者,因為他們會覺得黑天鵝還沒普及流行,尚未成氣候。這種面對不確定逐步提升心中的明確感,通稱為「與不確定性共舞(living with uncertainty)」。人們總是需要明確感,才會安心。「機率性明確感」與「可能性明確感」,其目的一致:滿足內心所需的明確感,只是手段不同而已。
譬如一隻小獅子肚子餓了,依據成功經驗奮力去追小兔,只是捕獲的兔子日漸減少(可能兔子變敏感了),有些困惑(明確感降低)。這小獅子的媽媽就教牠:肚子餓了,就眼睛閉著,睡大覺,不要亂跑。小獅子滿腦困惑,不確定感急速上升,非常不安;但母命難違,只好勉強為之,果然耳朵變靈敏了,清晰聽見兔子的聲音愈來愈近,然後猛然奔出一抓,輕易捕獲,飽食一餐,繼續睡大覺。
小獅子專注於問題(如肚子餓了),卻引來更多的問題(如追累了,走不動,引來生命危險)。母獅教小獅子不要圍繞問題,而專注於可能性(如原來以為兔子不可能自動送上門),反而發現更多的機會(如更容易填飽肚子的新途徑)。
從AlphaGo下圍棋可以發現,在面對高度不確定性的環境時,它懂得專注於可能性,探索更多機會,獲得全域最優而出人頭地。人類可以從AlphaGo學習到與不確定性共舞的能力,就會如同小獅子一般,探索到更多贏家之道。
如何降低風險:向AlphaGo學習「去蕪存菁」策略
AlphaGo透過監督學習,訓練了決策神經網路(policy network),亦即從網上下載了上百萬的業餘圍棋遊戲,透過監督學習,讓AlphaGo模擬人類下圍棋的行為,再從棋盤上任意選擇一個落子點,訓練系統去預測下一步人類將作出的決定,系統的輸入是在那個特殊位置最有可能發生的前五或者前十的位置移動。這樣會縮小探索範圍到5~10種可能性,而不用分析所有的200種可能性了。這種做法稱為AlphaGo蒙地卡羅搜尋樹(MCTS)的剪枝(pruning)策略,也就是AlphaGo的去蕪存菁策略。
這種策略的實踐技術,最簡單的就是MinMax演算法,它是一種最小化最差情況的演算法,也就是先考慮到可能失敗(沒把握的)情況,然後將有證據顯示最可能失敗的方案優先刪除掉,採取最低風險的方案,這又稱為「去蕪存菁」策略。
針對這一點,AlphaGo給人類的啟示是:當面臨高度不確定性的環境時,宜採取去蕪存菁的策略來有效降低風險。與圍棋競賽一樣具有高度不確定性的就是戰場,就如孫子在《形篇》中敘述:「故善戰者,立於不敗之地,而不失敵之敗也。是故,勝兵先勝而後求戰,敗兵先戰而後求勝。」換句話說,就是:「不打沒把握的仗」之意。
藉由AlphaGo領會「不打沒把握的仗」策略
前文說明Google的專家們已經把「探索和利用」最佳平衡的技巧(演算法)教給了AlphaGo,讓AlphaGo及AlphaGo Zero超越了人類的圍棋頂尖高手。因此,我們可以從AlphaGo的策略來領會戰爭的贏家策略:不打沒把握的仗。
俗語說,商場如戰場。這意味著AlphaGo的「剪枝」策略和兵家的「不打沒把握的仗」策略,都是企業家和一般人可以學習的去蕪存菁策略,以便有效降低風險,激發大膽探索的熱情和信心,探索出全域的最佳解,成為商場的贏家。
在股市裡,巴菲特是眾人皆知最成功的投資家。有人問巴菲特:「您買股票的原則是什麼?」他回答說,我只有兩條原則:第1條:「不賠錢」,有人繼續問他說,那麼第2條是什麼呢? 巴菲特則回答:「永遠不忘記第1條」。
這意味著,兵家所說的「不打沒把握的仗」就等於「不考慮(刪除)沒把握的仗」,但是不等於「只考慮有把握的仗」。一樣地,巴菲特所說的「不賠錢」就等於「不考慮(刪除)會賠錢的」,但不等於「只考慮有穩賺的」。
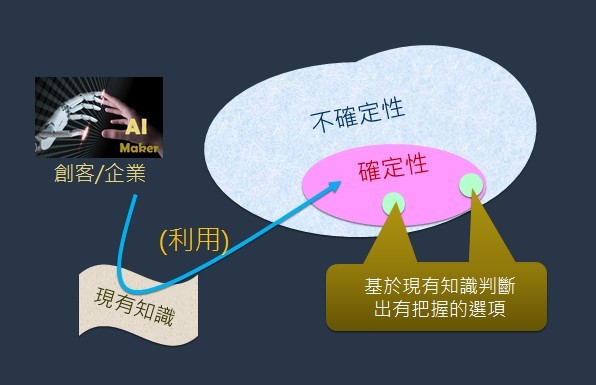
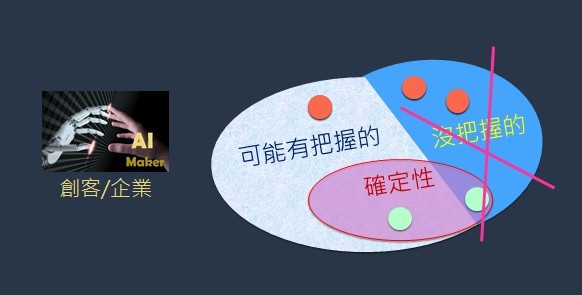
前文提到了「不打沒把握的仗」並不等於「只考慮有把握的仗」,只打有把握的仗,其意謂在現有知識經驗之內找出有把握的選項(圖3)。
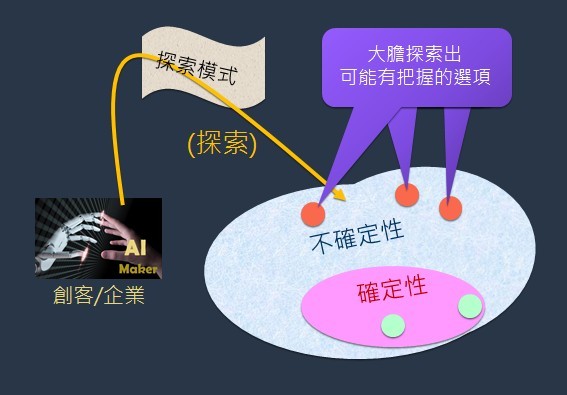
現有知識經驗就像一座碉堡,「只打有把握的仗」意謂在經驗(雕堡)之內找出有把握的選項,而「不打沒把握的」則意謂走出經驗(雕堡)之外去尋覓可能有把握的選項(圖4)。
其實,有把握的仗(或選項)有些在經驗雕堡內,有些在雕堡之外。在雕堡之外的有把握的仗,卻常常被現有經驗及知識把它們排除掉了。所以,經驗「雕堡內」的有把握的仗,加上「雕堡外」的有把握的仗,等於「全部有把握的仗」。此時,不打沒把握的仗等於只打(全部)有把握的仗,就意味著把雕堡拆除掉了。因為既有的經驗知識有時會成為探索(最佳決策)的阻力。當我們把經驗知識雕堡拆除掉,反而海闊天空,風險更低。反之,一直躲在雕堡裡從窗戶看世界,視野受限,反而危機重重而不自知。
結語
如果您已經能清?分辨出「不打沒把握的仗」與「只考慮有把握的仗」之間的區別,您的探索技能將可大幅提升了,因為可以在人生中遇到超越經驗值之外的狀況時,將其風險降到最低。這時,就可以學習AlphaGo蒙地卡羅搜尋樹(MCTS)的剪枝策略,將有明顯證據的「沒把握的選項」刪除,加以去蕪存菁(圖5)。
此時,能找到全域最優者,將會是贏家;而只能找到局部最優者,很可能是成為輸家(圖6)。
諸如圍棋、戰場或商場的高度不確定性環境中,圖4的「不確定性」區域通常非常大;因此,全域最佳解(即最優選項)大多會位於圖5的「可能有把握的」區域內;所以,通稱為贏家的甜區(Sweet Spot)。唯有提升探索不確定性的能力(包括去蕪存菁方法),才有信心能探索這個廣大的甜心區,找到全域最優選項,成為贏家。