監控系統高度依賴嵌入式視覺系統所提供的功能,以加速在廣泛市場與應用中的部署。這些監控系統的用途非常廣泛,包括從事件與車流量監控、安全與安防應用,一直到ISR與商業智慧。此用途的多樣性帶來許多挑戰,因此系統設計人員在解決方案時須加以克服。
這些挑戰,包含:
‧ 多攝影機視覺:擁有連接多個同質或異質感測器類型的能力。
‧ 電腦視覺技術:使用高階函式庫與架構(例如OpenCV和OpenVX)進行開發的能力。
‧ 機器學習技術:使用如Caffe等架構來運行機器學習推論引擎的能力。
‧ 提高解析度和幀率:提高影像中每幀所需的資料處理。
根據不同應用,監控系統會運用相應的演算法,例如光學流演算來偵測影像內的動態。當立體視覺提供影像內的深度感知時,機器學習技術亦用於偵測和分類影像中的物體。
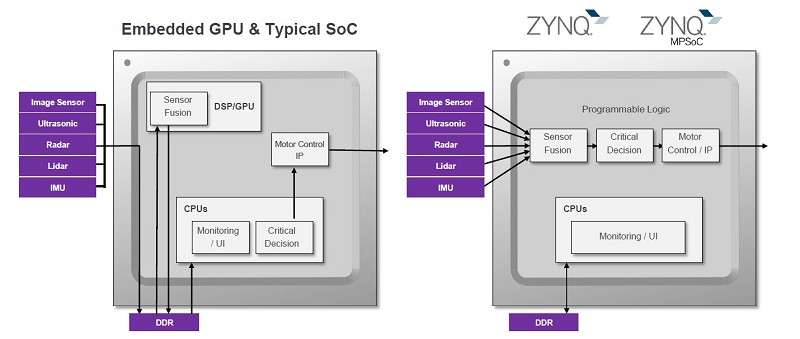
如All Programmable Zynq-7000和Zynq Ultrascale+ MPSoC等的異質系統元件逐漸被運用在監控系統應用上,而這些元件結合高效能Arm核心,來形成一個可編程邏輯(Processing Logic, PL)結構的處理系統(Processing System, PS)。
與傳統方案相比,PL與PS的緊密耦合使建立的系統具更強的反應力、可重組能力及更高的功率效能。基於CPU/GPU的傳統SoC方案需使用系統記憶體將影像從一個處理階段傳送到下個階段,由於多個資源需要存取在同一個記憶體,因此會降低確定性並增加功耗與系統反應延遲,造成處理演算法的瓶頸,且該瓶頸會隨著幀率和影像解析度的增加而加重。
當解決方案採用Zynq-7000或Zynq UltraScale+ MPSoC元件時,便能突破這個瓶頸。這些元件允許設計人員在元件的PL中運行影像處理管線,當在其中一個階段的輸出被傳送到另一個階段輸入的PL中,設計真正的平行影像管線時,就能獲得確定的反應時間,並同時縮短延遲以達到功耗最佳化的解決方案。
相較於僅有固定介面的傳統CPU/GPU SoC方案,利用PL來運行影像處理管線,能擁有更廣的介面能力。PL IO介面的彈性特質允許任意形式的連接,因此能支援如MIPI、Camera Link、HDMI等業界標準介面。此彈性還能達到客制傳統介面,並進行升級以支援最新介面標準,且利用PL能讓系統平行連接多個攝影機。
不過,最關鍵的是在無需使用硬體描述語言(如Verilog或VHDL)來重新編寫高階演算法下,來實現應用演算法的能力,這正是reVISION推疊的用武之地。
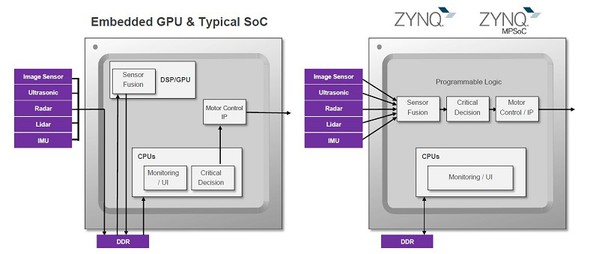
| 圖3 : 傳統CPU/GPU方案與Zynq-7000/Zynq UltraScale+ MPSoC的對比 |
|
reVISION推疊
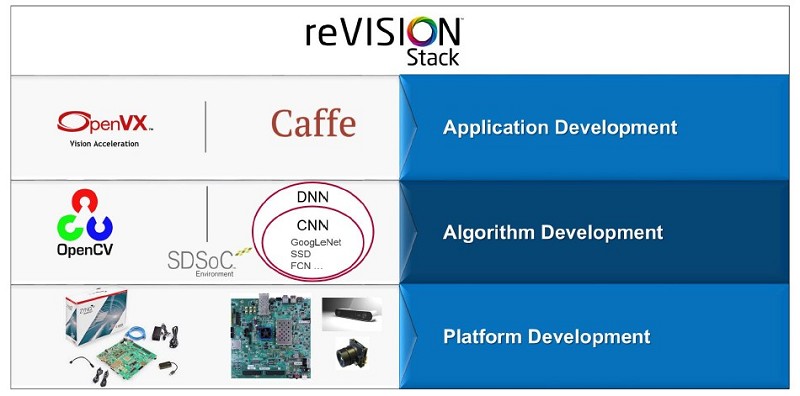
reVISION推疊使開發人員能夠實現電腦視覺和機器學習技術,當針對Zynq-7000和Zynq UltraScale+ MPSoC時,也能使用相同的高階架構和函式庫。為此,reVISION廣泛地結合多種資源來支援平台、應用與演算法的開發。該推疊分為三個不同等級:
1.平台開發:此為推疊的最底層,且是剩餘推疊層的建構基礎。該層為SDSoC 工具提供平台定義。
2.演算法開發:此為推疊的中間層,為需運用的演算法提供支援。同時該層亦支援影像處理和機器學習推論引擎加快轉移至可編程邏輯中。
3.應用開發:此為推疊的最高層,為業界標準架構提供支援。該層利用平台開發和演算法開發層來發展應用。
推疊的演算法和應用層是被設計來支援傳統影像處理流程與機器學習流程。在演算層中,支援用OpenCV函式庫開發影像處理演算法,這包含將多種OpenCV功能(包括OpenVX核心子集)加速轉移成可編程邏輯的能力。當支援機器學習時,演算法開發層則提供幾種可放在PL中用以實現機器學習推論引擎的預先定義硬體功能,然後再由應用開發層存取這些影像處理演算法與機器學習推論引擎,來創立最終應用,並為OpenVX和Caffe等高階架構提供支援。
reVISION堆疊能提供高效能監控系統演算法所需的所有必要元素。
在reVISION中加速OpenCV
演算法開發層最重要的優勢之一是能夠加速多種OpenCV功能。該層可加速的OpenCV功能可分成以下四種高階類別:
1.運算:包含兩個幀的絕對偏差、像素運算(加、減和乘)、梯度與積分運算等功能。
2.輸入處理:支援位元深度轉換、通道運算、直方圖等化、重新映射與尺寸重調等。
3.濾波:支援包含Sobel、自定義卷積和高斯濾波器等多種濾波器。
4.其他:提供Canny/Fast/Harris邊緣偵測、閥值以及SVM和 HoG分類器等多種功能。
這些功能構成OpenVX子集的核心功能,能提供支援OpenVX的應用開發層緊密的整合。開發團隊能利用這些功能在可編程邏輯中創立演算法管線,若能以此方式在邏輯中實現這些功能,便能明顯得提高演算法的運行效能。
reVISION中的機器學習
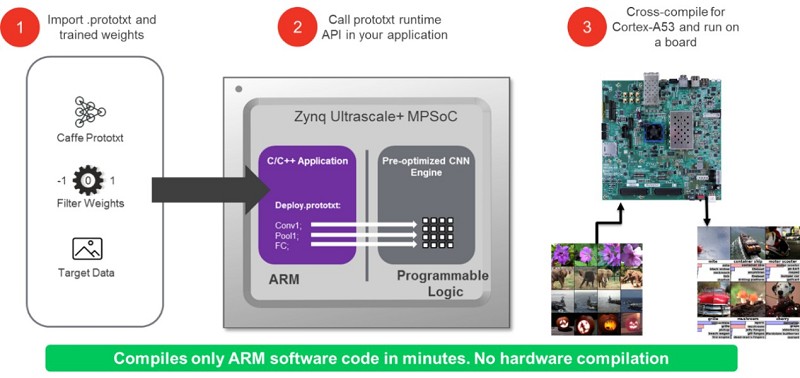
reVISION提供與Caffe的整合,以實現機器學習推論引擎。與Caffe的整合發生在演算法和應用開發層。Caffe架構在C++函式庫中為開發人員提供一系列的函式庫、模型和預先訓練的參數,以及Python和MATLAB捆綁程序。該架構在無需重新開始的狀況下,讓用戶能建立和訓練網路,以執行所需的運算。為便於模型重用,Caffe用戶可通過模型庫(model zoo)共享模型;其模型庫中提供多個網路模型,用戶可針對指定的任務來執行和更新。推論這些網路和參數則在prototxt檔案中被定義,且當在機器學習環境中部署時,此檔案則用來定義推論引擎。
reVISION提供Caffe整合功能,使機器學習推論引擎的執行非常簡單,剩下的工作皆由架構來完成,只需提供prototxt文件即可。接著,此prototxt檔案來配置處理系統及可編程邏輯中的硬體最佳化函式庫,而可編程邏輯則用來質行推論引擎,並包含Conv、ReLu、Pooling等功能。
推論在機器學習推論引擎中所執行使用的數字表示系統,同時在效能上也扮演著重要的角色。機器學習應用逐漸使用更高效率、降低精度的定點數字系統,例如INT8表示法。
相較於傳統的FP32,使用定點降低精度數字系統的準確度沒有明顯的損失。與浮點相比,定點運算更容易實現,因此改用INT8後,在一些執行上能達到更高效、快速的解決方案。可編程邏輯解決方案適合用於定點數字系統,而reVISION提供在PL中使用INT8表示法的能力。
這些INT8表示法允許在PL內使用專用的DSP模組。當使用同樣的核心參數時,這些DSP模組架構允許兩個INT8乘積累加函數(Multiply Accumulate)運算同時執行。此方案不僅能提高效能執行,同時能降低功耗。憑藉可編程邏輯的靈活特性,也可以輕鬆實現精度更低的定點數字表示法。
結論
reVISION使開發人員能夠有效利用Zynq-7000和Zynq UltraScale+ MPSoC元件所提供的功能,即便不是專家,亦能透過可編程邏輯來實現演算法。這些演算法和機器學習應用可通過高階的業界標準架構來達成,進而縮短系統開發時程。這使開發人員能提供較高的反應性、可重組能力,以及更低功耗的最佳化系統。
(本文作者Nick Ni、Adam Taylor任職於Xilinx公司)