新車在出廠之前需要先經過一連串的最終檢查,包括由技術人員以及自動化測試流程共同執行電子診斷的靜態測試、由技術人員測試軟體、測力計的動態測試,再加上其他測試站的共同合作,確認引擎以及進行懸吊或其他零件的調整。
工作人員、機台、車輛之間在最終測試的互相協同合作是一項相當複雜的任務。許多公司並沒有正式的途徑來優化這些過程,而是仰賴資深工程師主觀的建議,或從其他製造廠房經驗找出的最佳方法,而這些方式可能具備不同的條件要求,或甚至需要不斷地嘗試錯誤來找出最佳方法。
為了在最大化生產量與產能的同時盡可能降低人力需求與浪費,我開發了一個平台,利用Simulink與事件模擬模塊組(SimEvents)執行模擬。這項模擬可用來協助進行操作上的決策、預測若採取計劃中的某生產過程變更將產生的結果、並提升Daimler公司生產線的效率(圖1)。
優化最終測試所面臨的挑戰
最終測試的優化由於幾個因素讓變得複雜。首先,要估計各個測試站的處理時間是有困難度的。以在懸吊的變異為例,某些車輛可能需要在懸吊調整工作站停留比較久的時間。再者,引進可以加速完成測試的新設備可能造成既有流程的中斷。同樣地,將新技術導入至車輛形成新的額外選項並需要新的測試程序。
第三,可用流程改善選項相當複雜,即使是專家也幾乎不可能預測到所做的改變將如何影響流程的整體表現。不論是增加工作人員、平行地完成測試、重工車輛的處理、在每一個測試站之前插入緩衝(佇列)、允許車輛在測試站之間穿越、縮短循環週期—專家需要了解每一個可能的選項組合將造成什麼樣的影響來找出最佳的配置。
收集和管理資料
就我所知,我的模擬需要考慮到龐大的資料量。通常在模擬的研究,資料會在迥然不同的軟體套件之間進行交換,承受著準確性與完整性流失的風險。透過MATLAB與Simulink,可以在同一個環境收集、分析、準備資料,再利用這些資料進行以資料為基礎的優化與模擬。除此之外,也可以透過平行運算工具箱(Parallel Computing Toolbox?)在多個運算核心進行分析來加快處理速度。
每一個測試站皆會產生各車輛的log檔。如果1000台車各在3個測試站受過測試,則會有3000個資料集被登錄。單一台車在一個測試站的log檔就容納了高達200,000行的資訊。每一個log檔只容納一小部分的必要資訊,其中包含車輛細節、每一項測試結果、以及完成每一項測試所花費的時間。為了快速地萃取這些資料,我建立了一個DOS-based的批次檔案,再為每一個log檔調用這個批次檔案,並將這些工作分配至每一個可用的核心。
分析現有的流程
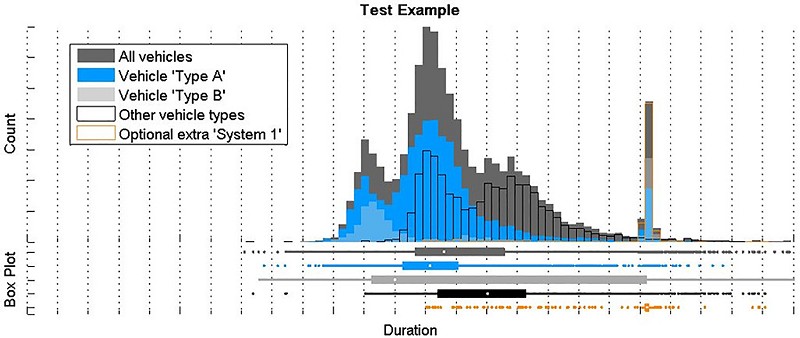
開發模擬之前,我需要先了解目前的測試流程。因此我從每一個測試站收集了log檔,並在MATLAB以數字及圖表進行分析。我繪製了測試時間及車輛變異的直方圖及長條圖,並進行統計分析來關聯這些變數(圖2)。我利用平行運算工具箱在四核心處理器執行這些任務,使log檔的語法分析及處理速度加快了將近四分之一。
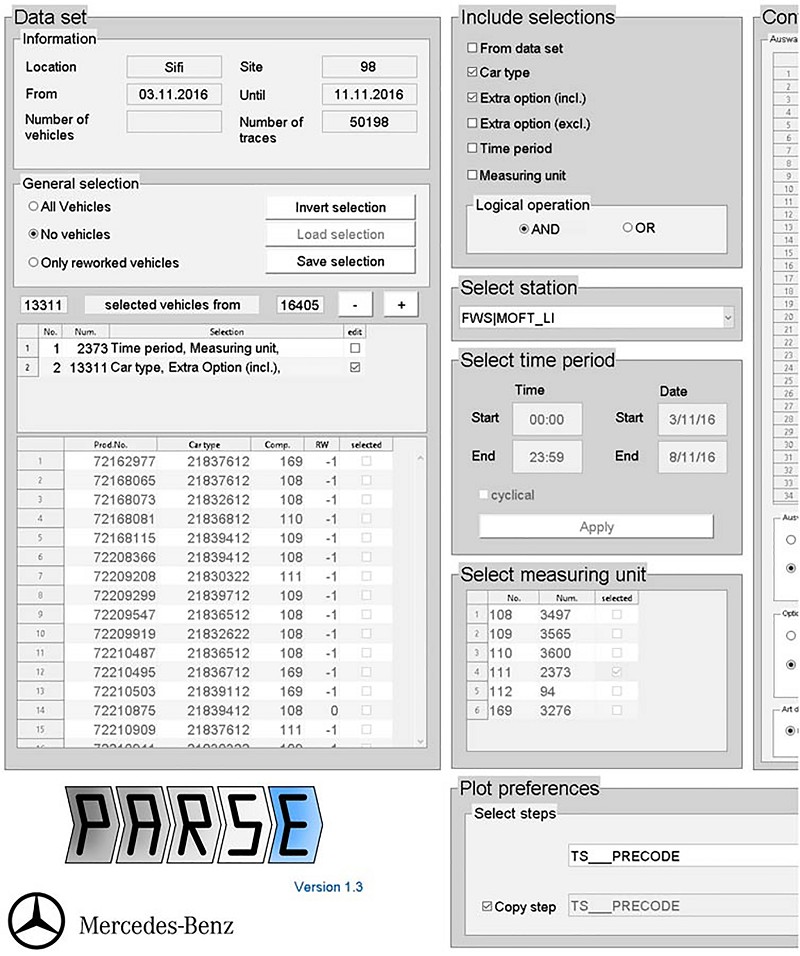
在經過互動式地探索與分析資料之後,我在MATLAB建立了一個介面來簡化常見的分析任務(圖3)。我將這個介面與在MATLAB開發的分析函式打包成一個單獨的Windows應用程式PARSE(Process Analysis Routine for Site-overlapping Exploration),將介面與我在MATLAB開發的分析函式包含在內。透過MATLAB編譯器(MATLAB Compiler),PARSE讓我在Daimler的同事可以探究最終測試的資料,不需安裝MATLAB。PARSE也為接下來的建模與模擬提供了資料庫。
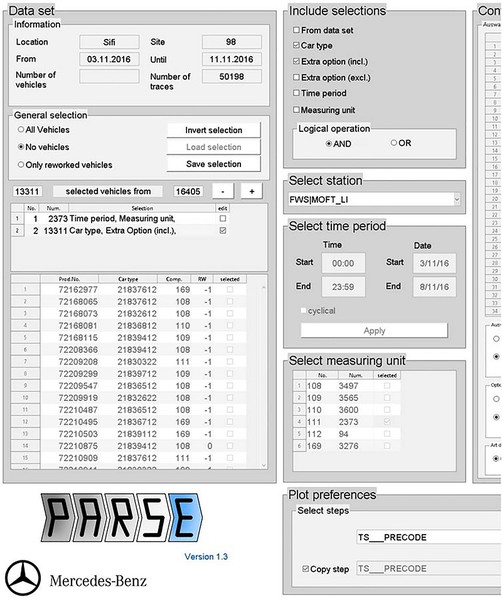
| 圖3 : 在MATLAB開發的PARSE應用程式,用來處理、分析、探索測試站資料。 |
|
為最終測試流程建立模型
大部分的工程師將佇列、伺服器、個體、及其他來自預先定義的函式庫的模塊連結在一起,來建立用來進行離散事件模擬的模型。大多數模擬環境中,因為預先定義的要件的關係,讓理解其基本功能與在模擬系統的影響變得困難。我決定採取不同的方式:開發一個MATLAB腳本,以編程的方式建構SimEvents模型。透過SimEvents的基線元件建立模型有個優點,就是在一開始就先知道以模型建立的系統的所有功能、邏輯、策略行為。利用編程的方法可以執行最佳化演算法,同時調整模型參數並產生新的模型。這樣的方式,可以藉由在MATLAB建立的第二個介面定義出模型。
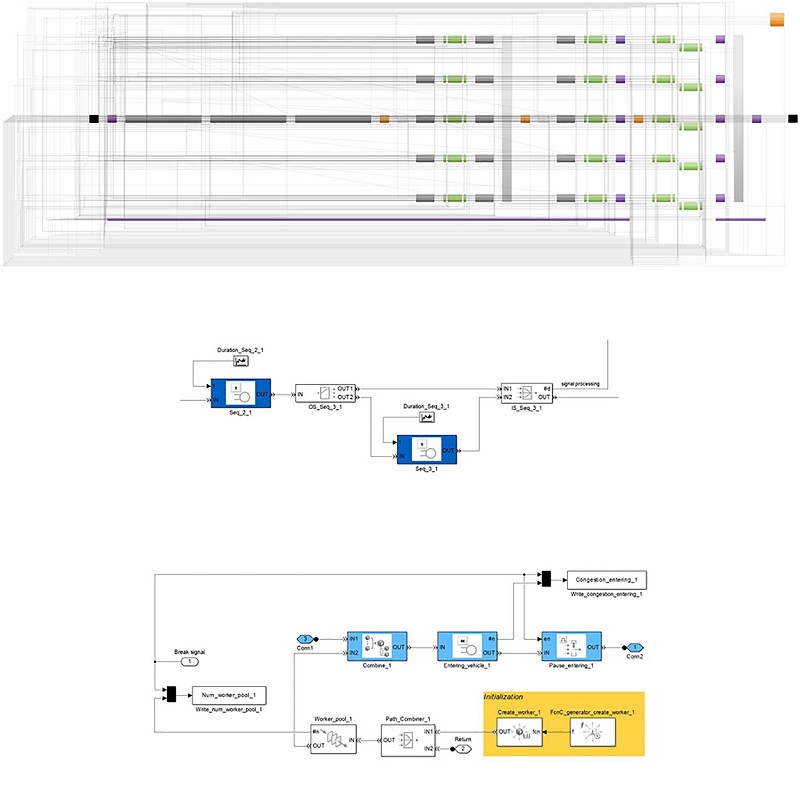
這個介面讓工程師可以指定測試站的數量與結構、工作人員人數等條件,來定義測試流程。工程師的選擇被捕捉進一個的資料模型,MATLAB腳本可利用該模型來產生內含測試站與工作人員子系統的SimEvents模型(圖4)。
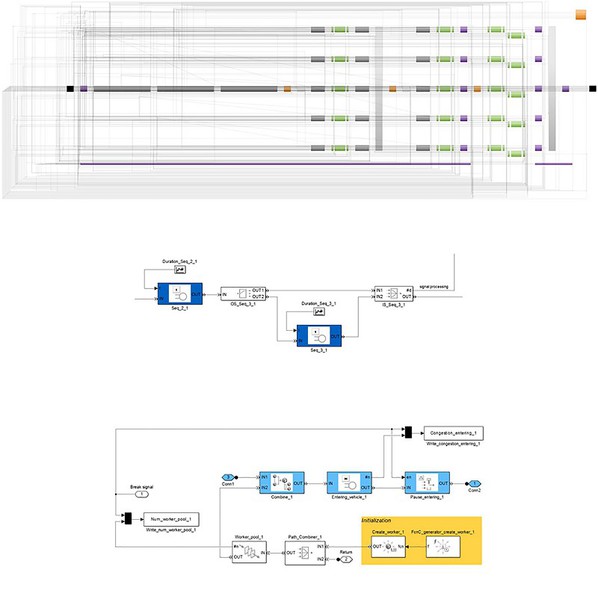
| 圖4 : 上:建立在SimEvents的終端測試流程模型。中:從模型而來的測試站子系統。下:工作人員子系統。 |
|
在這個被產生出的模型包含了大約1500個模塊,工作人員與車輛實體在每一個測試站透過實體整合器被放在一起。這些測試站以多個代表了測試站內每個單獨的流程的單一伺服器表示。在每個測試站所花費的時間則由基於事件的隨機數字模塊利用任意離散分配依該測試站處理過的log資料來計算。
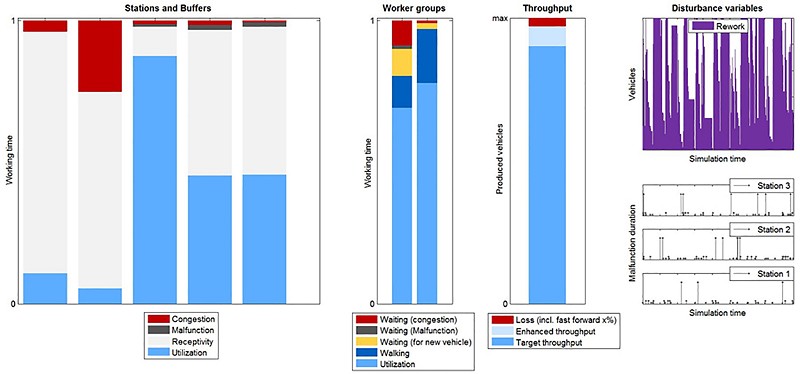
測試站的邏輯行為還有實體的策略控制皆是以MATLAB腳本建模,並以S-Function模塊形式嵌入到模型中。模型儲存了來自每一個測試站的統計資料,包含有多少車輛被處理過、每輛車在測試站停留多久、在每個測試站之間車輛會等候多久等等,也儲存來自週邊過程的資料,像是車輛交付、工作人員的流動、以及停頓時間等等。我利用MATLAB來進行這些資料的後期處理與視覺化(圖5)。
我最早利用介面與模型產生器建立的其中一個模型僅是複製內含以真實世界原始資料建立的資料庫的現成工廠設置。我執行這個模型模擬,並將其結果與來自工廠現場的真實世界結果進行比較,以驗證模型與模型產生的腳本。
執行模擬來優化流程
當我能夠處理與分析log資料並以編程的方式產生模型,我就可以開始執行有系統的模擬來優化最終測試的表現。在模擬當中,演算法的優化讓結構的變化反應出不同的工廠產出,以及讓參數的變化反應個別的測試站結果。我提供界限與初始值,並接著利用一個在全域最佳化工具箱(Global Optimization Toolbox)的樣本搜尋演算法來優化像是生產量、必要的生產設備、人力、與浪費等因素。若要評估所有可能的模型變異,可能需要經歷數千次的實驗。我透過樣本搜尋演算法,只要少少幾次的實驗就可以達成同樣的結果。
SimEvents模型幫助我調整臨界值以執行假設情境。我執行模擬器,例如查看車輛的變化如何影響特定測試必須花費的時間,這讓我可以找出對流程性能影響最大的變異。
傳統的汽車製造商花費相當可觀的精力在縮短測試時間上,卻很少注意到最終測試的設計對於整個流程的影響。在Daimler,我的模擬研究改變了這個情況。我透過SimEvents執行的模擬與最佳化提供改變廠房結構所造成之影響的洞見。在設計新的製造廠房之前,Daimler現在可以評估像是預備及緩衝區的大小、測試站數量、接合點的啟用、人員配置等可能影響廠房測試表現的因素。
(本文由鈦思科技提供;作者Marius Gemeinhardt任職於Daimler AG公司)