瀏覽人次:【9908】
現今快閃記憶體已經被廣泛地應用在各種不同的領域。但由於成本的考量,高密度低成本的快閃記憶體的市場佔有率與日俱增,但此類的快閃記憶體同時也帶來許多管理上的問題,例如資料存取速率大幅下降與資料錯誤率大幅上升。因此提出並研發一既省主記憶體又能有效提昇快閃記憶體讀寫效能與資料可靠性的方法,實為一重要的課題。
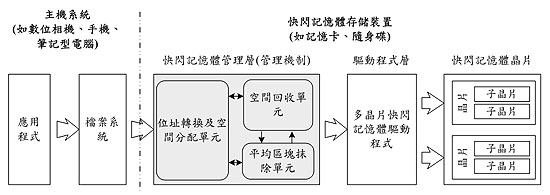
一個快閃記憶體晶片是由區塊 (block) 所組成,每個區塊是由頁面 (page) 所組成,每個頁面包含一個資料區與一個額外區,資料區是用來存放資料而額外區是用來存放管理資料(如錯誤更正碼、資料區所存資料的邏輯位址…等)。區塊是資料抹除的單位,而頁面是讀寫的基本單位。當一個頁面被寫入資料之後就不能再寫入資料,必須要等到它所在的區塊被整個抹除後才能再寫入資料。因此為了效能的考量,通常我們會把寫入的資料寫到空閒頁面 (free page),而不是寫回原來的頁面,因此,同一份資料可能會同時有多個版本存在於快閃記憶體之中,然而只有最後一版的資料為有效資料,其餘舊版的資料皆為過期或無效資料。存放最後一版資料的頁面稱為有效頁面,存放舊版資料的頁面稱為無效頁面。如圖一所示,快閃記憶體裝置上通常會搭配一個管理機來管理快閃記憶體,使得主機系統能夠使用邏輯位址直接存取快閃記憶體存儲裝置上相對映邏輯位址的資料,而不需了解快閃記憶體的存取特性及實際資料所存在的實體位址。為了管理快閃記憶體,在快閃記憶體存儲裝置上需要一個邏輯位址與實體位址的轉換機制 (address translation) 或轉換資訊,這樣才能找到每個邏輯位址的資料存在處。另外,當系統沒有足夠的空閒區塊時,空間回收單元 (garbage collector) 就會被啟動來回收存放過期或舊版資料的空間。由於每個區塊所能被抹除的次數有限,因此在選擇回收並抹除的區塊時,必須盡量使得每個區塊被抹除的次數較為平均,以延長快閃記憶體的使用壽命。
《圖一 》
 |
快閃記憶體又可分為傳統較高成本的 Single-Level Cell (SLC) 快閃記憶體,以及高密度低成本的 Multi-Level Cell (MLC) 快閃記憶體,其中SLC快閃記憶體的每個記憶體單元(cell)只能記錄一個位元 (bit) 的資料,而MLC快閃記憶體的每個記憶體單元可記錄兩個位元以上的資料。傳統上有許多不同的管理機制被提出 [1][2][3][4],然而隨著製程密度的上升,快閃記憶體的效能也快速下滑,再加上 MLC 快閃記憶體又新增兩個寫入的限制:一個是每一個頁面只能被寫入一次,另一個是每個區塊內的每個頁面必須要循序被寫入。因此使得傳統的管理方法無法管理這些高密度低成本的 MLC 快閃記憶體晶片,或是效能變得十分低落。為了改善存取效能,有研究提出利用特別的方法來管理隨機小量被寫入的資料,以提昇整體系統效能 [5][6][7]。 有些研究更進一步提出可調性的位址轉換機置來管理大容量的快閃記憶體存儲系統,以提昇管理機制的可擴充性 [8][9]。另外,有一些不同的研究是利用寫入緩衝區來提昇快閃記憶體的寫入效能 [10][11][11],不過這些機制都沒有辦法在頁面資料毀損失時還原毀損頁面中的資料,且通常會在系統當機或斷電時產生資料流失,而使得儲存系統喪失資料的一致性。
不同以往的方法,本文提出一個「提交式管理機制」來提升快閃記憶體的可靠性,可還原毀損頁面中所存的資料。同時,此機制包含一個「三層式位址轉換架構」以加速位址轉換效能並減少主記憶體的使用量,以及一個「可調性區塊管理方法」以利用對多顆記憶體晶片平行寫入的特性來加速資料存取的速度,並且可依隨機或循序存取模式自動調整以降低管理的額外負擔。另外,此管理機制同時考慮到高密度MLC快閃記憶體的寫入限制、系統快速開機及系統快速當機回復等特質。
提交式管理機制
快閃記憶體區編排方式
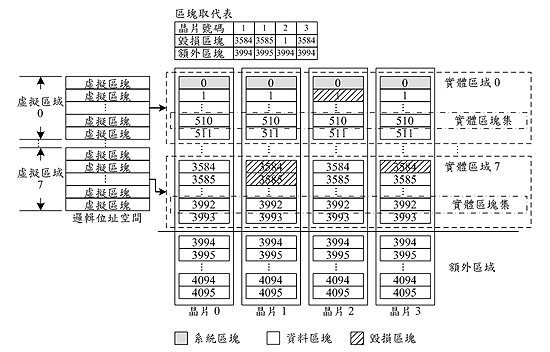
在本文所提出的提交式管理機制之中,一個多晶片的快閃記憶體存儲裝置的實體區塊,會被分割成多個實體區域,及一個額外區域(如圖二所示)。在不同晶片的同一編號的實體區塊,組成一個實體區塊集,同一個實體區塊集中,各個區塊中相同偏移量的頁面組成一個實體頁面集。一個實體區塊集為空間回收與空間分配的最小單位,而一個實體頁面集為資料讀寫的最小單位。額外區域的實體區塊只能用來取代同一晶片內的毀損實體區塊,因此即使有毀損實體區塊存在且被取代時,讀寫指令仍然能夠同時對實體區塊集內的每一個區塊做讀寫的動作,達到善用系統效能的平行性。每當有毀損實體區塊發生時,就會從同一個晶片的額外空間分配一個好的實體區塊來取代該毀損區塊,而此取代資訊就記錄在「區塊取代表」裏。一個實體區塊集內的資料寫入是從第一個頁面集循序寫入,以符合高密度 MLC 快閃記憶體的寫入限制。在邏輯位址空間方面,連續的邏輯位址組成一個虛擬頁面,連續的虛擬頁面組成一個虛擬區塊,連續的虛擬區塊組成一個虛擬區域,每一個虛擬區域都會依序對映到一個實體區域,而一個虛擬區域中的虛擬區塊可以對映到相對實體區域中的任一個實體區塊集,且每一個虛擬區塊最多可以對映到兩個實體區塊集,其中較早被分配對映的實體區塊集稱為舊實體區塊集,而較晚被分配對映的則稱為新實體區塊集。
《圖二 》
 |
三層式位址轉換架構
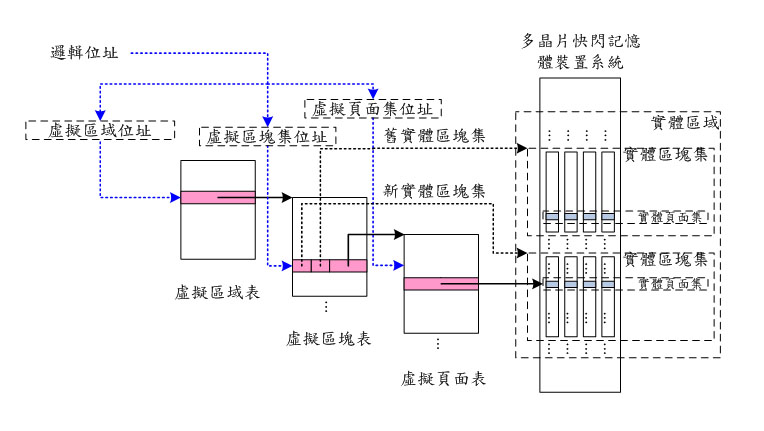
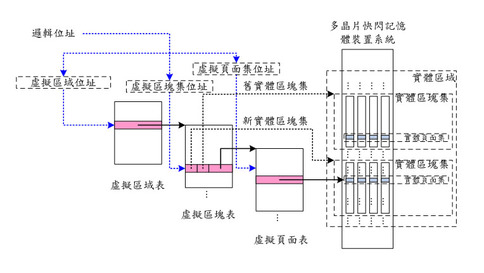
給定一個邏輯位址,這三層分別負責「實體區域位址」、「實體區塊集位址」及「實體頁面集位址」等三層的位址轉換以找到該邏輯位址的資料所存放的實體位置。如圖三所示,當給定一個將要被存取的邏輯位址,這個邏輯位址就會被分割成「虛擬區域位址」、「虛擬區塊位址」及「虛擬頁面位址」,而這三個位址會被當成索引來分別從相關的「虛擬區域表」、「虛擬區塊表」及「虛擬頁面表」來找到存放該邏輯位址的資料的實體頁面集。每一個虛擬區域都會維護一個自己的虛擬區塊表來維護所有虛擬區塊與相對映實體區塊集的位址轉換資訊,而每一個虛擬區塊都會有一個自己的虛擬頁面表來維護該虛擬區塊中虛擬頁面對映到相關實體頁面集的轉換資訊,且只有在被使用或參考到時才會從快閃記體讀取出來存放在主記憶體之中。如此一來,只有被用到的位址轉換資訊才會被存放在主記憶體,因此可以大幅降低主記憶體的使用量。由於每個虛擬區域都會對應到一個實體區域,因此需要一個虛擬區域表來記錄它們與實體區域的對映關係,當然也可以使用循序對映的方式,這樣一來就不需要虛擬區域表,只要直接記算就能得知每個虛擬區域所對映的實體區域。
而當一個虛擬區域被存取時,它相對映的虛擬區塊表會馬上利用掃描相對映實體區域內每一個實體區塊集的一個頁面來重建該虛擬區塊表。而當一個虛擬區塊被存取時,它相對映的虛擬頁面表可以馬上利用掃描相對映實體區塊集內每一個實體頁面集來重建該虛擬頁面表。由於只有被存取到的虛擬區域(/區塊)的相對映虛擬區塊(/頁面)表需要被重建,所以開機及當機後位址轉換資訊重建的效能非常高,且不會隨著快閃記憶體容量上升而變慢。此外,所有的位址轉換表可以暫時存放在快閃記憶體之中,在被使用時才讀取出來,且關機時將所有更新過的位址轉換表都寫回快閃記憶體之中,則當系統有正常關機時,重開機就不用任何位址轉換表重建的時間,因此能快速啟動。若是系統毀損,則下次開機之時,我們也只需要重建毀損的位址轉換表即可。因此具有高度的可擴充性及位址轉換效能。
《圖三 》 - BigPic:763x430
 |
可調性區塊管理方法
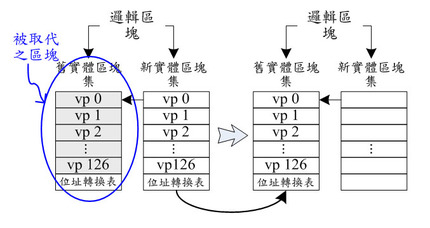
在所提出的提交式管理機制中,採用可調性區塊管理方法來管理資料的寫入。一開始每個邏輯區塊都沒有對映的實體區塊集,當一個邏輯區塊第一次被寫入資料時,一個空閒的區塊集就會被分配來存放被寫入的資料,並且對映成該邏輯區塊的「新實體區塊集」,所寫入的資料會依序從該區塊集的第一個頁面集循序往下寫。當此新實體區塊集被寫滿剩下最後一個頁面集時,該邏輯區塊所有資料的邏輯位址到其相對映實體頁面集的位址轉換表(註:也就是虛擬頁面表)就會存放在最後這個頁面之中,稱寫入位址轉換表的這個動作為「確認提交」。如果接下來有資料寫入到此邏輯區塊,則另一個空閒實體區塊集就會被分配來存放寫入資料,並且對映成此邏輯區塊的新實體區塊集,而原來對映的實體區塊集就變成「舊實體區塊集」,所有寫入的資料都會循序地寫入新實體區塊集。
當一個邏輯區塊已經對映到兩個實體區塊集,且其新實體區塊集已經被寫滿或是已確認提交,則當有新的寫入資料到此邏輯區塊時,則一個新的空閒實體區塊集就會被分配來存放寫入的資料,並且設定為其邏輯區塊的新實體區塊集,而原來的兩個實體區塊集中,擁有比較多有效資料的區塊集就會被設定為舊實體區塊集,另一個區塊集則會被回收並且抹除。在回收之前,存放在區塊集內的有效資料會先被複製到新分配的實體區塊集裏。
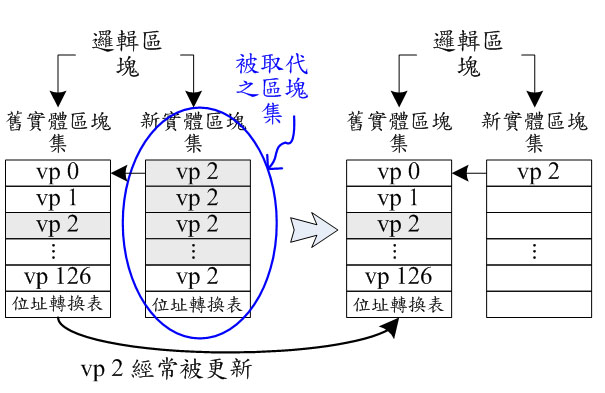
《圖四 》 - BigPic:604x392 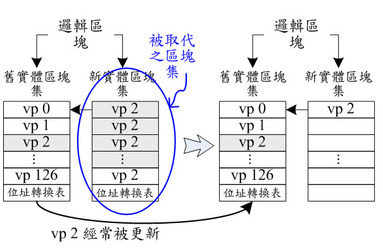 |
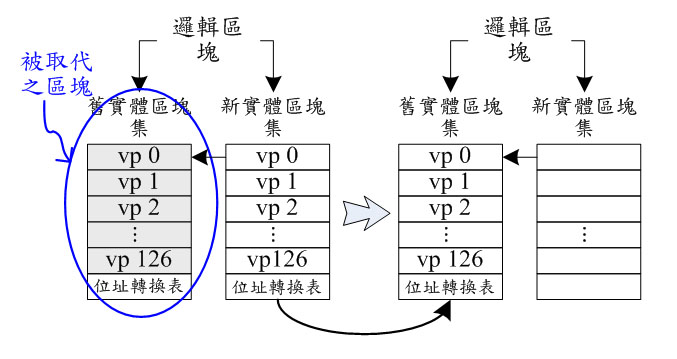
如圖四所示,為一個邏輯區塊的舊實體區塊集擁有較多的有效資料或頁面集,每個頁面集所存放的資料的邏輯位址簡寫為 vp,通常這樣的現象發生在存放系統資料或是小量經常被更新的資料,因此大部分有效資料都留在舊實體區塊集,而新實體區塊集所存放的為經常被更新的少量資料,因此只有非常少量的有效資料,其餘大多為過期或無效資料(灰色底代表的是無效資料)。當邏輯區塊所相對映的兩個實體區塊集都已確認提交,此時,若有一個新的資料寫入到此邏輯區塊,則新實體區塊集中的有效資料(也就是vp 2)會先被寫到一個新分配的空閒實體區塊集,接著就會被回收並抹除,而這個新分配的實體區塊集則變為該邏輯區塊的新實體區塊集,而原來的舊實體區塊集仍然為舊實體區塊集。另外一個循序資料存取的例子(如圖五所示),大部分的資料都循序被更新到新實體區塊集,因此當新實體區塊集被寫滿或確認提交時,大部分或所有的有效資料都在新實體區塊集,若有一個新的資料寫入該邏輯區塊時,舊實體區塊集內的有效資料會被複製到新分配的空閒實體區塊集,此空閒實體區塊集就會變成該邏輯區塊的新實體區塊集(註:圖五的例子中的舊實體區塊集沒有有效資料),接著該舊實體區塊集就會被回收並且抹除,而原來的新實體區塊集就變成該邏輯區塊的舊實體區塊集。值得一提的是:系統裏的實體區塊集的數量必須比邏輯區塊多,因為每個邏輯區塊可能同時對映到兩個實體區塊集。
《圖五 》 - BigPic:676x359
 |
依據上面例子可知,此可調性區塊管理方法可以自動調整,使得不論是隨機資料寫入或是循序資料寫入都能有很好的效能。當隨機寫入發生時(例如寫入檔案特性、檔案系統的系統資訊或是小系統檔案),大部分的有效資料都會留在邏輯區塊的舊實體區塊之中。當循序資料寫入的狀況發生時(例如寫入多媒體檔案的內容),資料通常會留在邏輯區塊的新實體區塊之中。而本文所介紹的可調性區塊管理方法總是會選擇有效資料較少的實體區塊來抹除,因此不論是隨機或循序資料寫入,都能有很好的空間回收效能。下面圖六是一個連續寫入兩個1MB大小的檔案到一個 FAT 檔案系統的過程,在寫入這兩個檔案的過程中包含了一個大量的循序區域寫入(邏輯位址 210664-214759)以及三個隨機區域的小量資料寫入。本發明所提出的方法可以同時對資料內容的寫入、檔案屬性的寫入與目錄資訊更新的寫入都有很好的效能。
《圖六 》 - BigPic:613x606 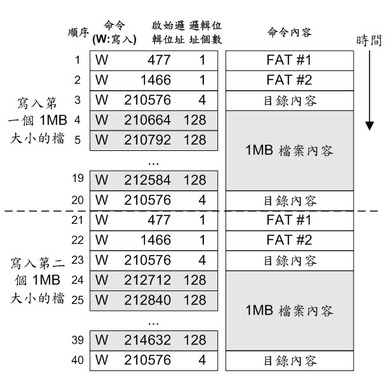 |
值得一提的是:每一個實體區塊集都會在實體頁面的額外區保留一個指標指向另一個實體區塊集,而此實體區塊集是在它之前被對映到同一個邏輯區塊的實體區塊集。因此系統如果當機的話,系統只要從這個指標的指向關係就能知道對映到相同邏輯區塊的實體區塊集的新舊關係。當然如果系統分配一個新的空閒實體區塊集來取代某個實體區塊的過程中發生當機或斷電,那麼系統裏就可能會有三個實體區塊集會對映到同一個邏輯區塊,然而因為最後被分配對映到此邏輯區塊的實體區塊集一定沒有指標指向它,而被它的指標所指到的實體區塊集就是沒有被取代掉的那個實體區塊集,因此就能夠找出三個實體區塊集的新舊關係,以回復未完成的實體區塊集取代動作,達到快速當機回復的目的。
另外,一個實體區塊集裏頭所存放的資料會使用錯誤更正的方法來還原更正一個實體頁面或實體頁面集裏的資料。一個比較直接的做法是把每一個寫入同一個實體區塊集裏的每一個實體頁面資料都使用XOR這個運算來算出「同位元檢查碼」,最後在關機或是實體區塊集裏的所有實體頁面集(除了最後一個頁面集)都被寫滿之時,將該實體區塊集所屬實體頁面集的同位元檢查碼寫入到最後一個實體頁面集裏(註:與虛擬頁面表一起寫入),而這個實體頁面集裏的實體頁面稱為「總結頁面」。當未來實體區塊中有任何一個實體頁面資料毀損時,該實體區塊集的同位元檢查碼就可以用來還原該毀損頁面內的資料,同時使用額外區域裏的空閒實體區塊來取代包含該毀損頁面的實體區塊,被取代的實體區塊內的資料都搬移到新的實體區塊內,同時區塊取代表的對映也會隨著被更新。之所以當一個實體區塊內有一個頁面毀損時就把該實體區塊置換的原因是因為擁有毀損頁面的區塊通常比較容易產生更多的毀損頁面,且對一些特定的管理方法會有不良的影響,例如使得這些方法變得沒有效率或是無法正確存取資料。值得一提的是:因每個虛擬區塊所屬的虛擬頁面表同時存放在其相對映的實體區塊集的總結頁面裏頭,所以每個虛擬區塊集被存取時就不需要重建其相對映的虛擬頁面表。
最後,本文同時提出一個快速的「過期資料回收法」。當系統沒有足夠的空閒實體區塊時, 系統的空間回收單元(garbage collector)就會被啟動來回收無效資料所占據的空間。空間回收器被啟動時就會循環地檢查每個邏輯區塊,如果某個邏輯區塊對映到兩個實體區塊集,這兩個實體區塊集裏的有效資料就會被合併複製到另一個空閒實體區塊集,然後把這兩個實體區塊集抹除並回收,如此一來不常被更新的資料所占據的空間就能得到回收以得到更好的空間利用率。由於每次合併兩個實體區塊集就能得到一個空閒的實體區塊集,因此空間回收的最差執行時間(worst-case execution time)就能很容易地預測,這樣的特性對即時系統來說是非常重要的。
結語
本文所提出的「提交示管理機制」之中所包含的三層式位址轉換架構可提升位址轉換效率,以提升快閃記憶體裝置的整體效能,並且達到高度的可擴充性。同時可調性區塊管理方法可對多個快閃記憶體晶片做同時存取的動作以大幅提升存取效能,並且能自動調整所選中的空間,以最小化回收過期資料時所增加的資料複製量。另外更使用總結頁面來存放部分的位址轉換資訊及錯誤更正資訊來進一步提升高密度低成本快閃記憶體儲存裝置的位址資訊重建效率及資料可靠性。
本研究成果已發表於 2009 年設計自動化國際會議 (Design Automation Conference, 2009)。
參考文獻
[1]Flash File System. US Patent 540,448. In Intel Corporation.
[2]FTL Logger Exchanging Data with FTL Systems. Technical report, Intel Corporation.
[3]Flash-memory Translation Layer for NAND flash (NFTL). M-Systems, 1998.
[4]A. Birrell, M. Isard, C. Thacker, and T. Wobber. A Design for Highperformance Flash Disks. SIGOPS Oper. Syst. Rev., 41(2):88–93, 2007.
[5]T. Kgil and T. Mudge. FlashCache: a NAND Flash Memory File Cache for Low Power Web Servers. the International Conference on Compilers, Architecture and Synthesis for Embedded Systems (CASES), pages 103–112, 2006.
[6]G. Kim, S. Baek, H. Lee, H. Lee, and M. Joe. LGeDBMS: a Small DBMS for Embedded System with Flash Memory. In the 32nd International Conference on Very Large Data Bases (VLDB), pages 1255–1258. VLDB Endowment, 2006.
[7]C.-H. Wu, L.-P. Chang, and T.-W. Kuo. An Efficient B-Tree Layer for Flash-Memory Storage Systems. In the 9th International Conference on Real-Time and Embedded Computing Systems and Applications (RTCSA), 2003.
[8]L.-P. Chang and T.-W. Kuo. An Efficient Management Scheme for Large-Scale Flash-Memory Storage Systems. In the ACM Symposium on Applied Computing (SAC), pages 862–868, Mar 2004.
[9]C.-H. Wu and T.-W. Kuo. An Adaptive Two-level Management for the Flash Translation Layer in Embedded Systems. In the IEEE/ACM International Conference on Computer-Aided Design (ICCAD), pages 601–606, 2006.
[10]H. Jo, J.-U. Kang, S.-Y. Park, J.-S. Kim, and J. Lee. FAB: Flash aware Buffer Management Policy for Portable Media Players. In IEEE Transactions on Consumer Electronics, pages 485–493. IEEE, 2006.
[11]H. Kim and S. Ahn. BPLRU : A Buffer Management Scheme for Improving Random Writes in Flash Storage. In the 6th USENIX Conference on File and Storage Technologies (FAST), pages 239–252, 2008.
[12]S. yeong Park, D. Jung, J. uk Kang, J. soo Kim, and J. Lee. CFLRU: a Replacement Algorithm for Flash Memory. In the International Conference on Compilers, Architecture and Synthesis for Embedded Systems (CASES), 2006.
---張原豪為國立台灣大學資訊工程學博士,現任國立台北科技大學電子工程學系助理教授;郭大維為德州大學奧斯汀分校電腦科學博士,現任國立台灣大學資訊工程學系教授---
|