在本系列的第二個部份中,已分別探討了以暫存器為基礎和以描述符為基礎的不同DMA模式。現在接著要來探討的是關於在應用中資料搬移選擇的一些重要系統決定。但首先來重新檢視一下DMA的模式,以便在面臨要選用何種模式時,能夠有更多的指引方向。
為了使容量相同的資料維持連續以及單向的移轉,使用自動緩衝的架構是最為恰當的。對DMA設定暫存器做一次設定,而移轉結束時會被自動重新讀取。假如可以使用多維定址(multi-dimensional addressing)的話,那麼就能夠設定多重緩衝,而個別獨立的中斷也就可以被設定為在每個緩衝區的結尾進行觸發。
移轉至音訊編/解碼器是這類型處理的完美候選人。在選擇次緩衝區數量時應該要和所需執行之處理程序類型相符。對於連續性的移轉,只要確定使每個緩衝區的最大處理時間低於其用以搜集一個緩衝區所花的時間即可。
假如在特定通道上的移轉大小或是方向會有所改變,那麼描述符模式才是最佳的選擇。想像以下的情況:在內部與外部記憶體之間有一系列的小型移轉。如果區塊的大小改變,或是想要以非連續性型態的方式遊走於一個緩衝區,描述符可以針對這個目的來進行設定。
我們將很快地對一些系統資料搬移情況該選擇使用快取或是DMA來做些探討,但是在這之前,必須先看看存在於應用領域中資料搬移的類型。
因為透過內建的周邊來將資料從系統中移轉進來或是移轉出去是最易於展示的方法,所以就從這個部分開始。許多的周邊在進行資料搬移時,都具有選擇使用核心存取或是DMA通道的特性。當可以選擇時,應該使用DMA通道。DMA控制器是最佳的選擇,這是因為通常資料不是進來的太慢就是太快,以致於處理器無法有效率的對其進行即時處理。以下就是一些例子:
當使用像是串列周邊介面(SPI)埠或是通用非同步收發器(UART)之類的慢速串聯元件時,資料將會以遠低於處理器核心運作的速率來進行移轉。核心在對這類型周邊進行存取時,通常會輪詢記憶體映射暫存器(memory-mapped register)中某些位元。即使周邊運作的速度比處理器時脈還低(這同時也意味著存取動作發生的頻率較低),這個輪詢動作仍然是頗為浪費的。在某些狀況下,周邊具有發出中斷信號的能力,藉以通知核心移轉已經開始進行。然而,處理這樣一個中斷的成本─包含了內容切換(context switches)的時間,是會隨著每次的資料移轉而發生的。
另一方面,使用DMA控制器來執行移轉,可以對在中斷發生前所產生的移轉數量進行微控制。此外,該中斷也會在每個資料”區塊”的結尾產生,而非僅只是在每個位元組或是字元之後產生。
在資料流量範圍的另一端,較高速的並聯周邊(比如說以10 – 100 MHz運作)可能不具有核心移轉的選項。這有兩個原因:第一個原因是,當使用這種方式設定時,處理器會持續的對周邊進行存取。第二個原因則是,與高速周邊相關連的處理程序大多會在資料區塊上完成。無論是在信號處理應用之快速傅利葉轉換(FFT)或是在影像處理系統的二維迴旋,一旦該緩衝區最後一筆資料取樣送達後,處理器就可以開始工作。其中,發出區塊移轉結束信號的中斷會分散在上百或是上千個移轉。
不論周邊移轉的類型為何,DMA通道應該要被設定有多重的緩衝區,這樣處理器在存取目前的緩衝區時,下一組緩衝區才會處於被充填的狀態。假如是更加複雜的系統,那麼就會牽涉到同時的多重區塊移轉。舉例來說,除了存取現有的區塊並蒐集下一個區塊之外,可能也有需要將前一組經過處理的區塊傳送出去,以作為未來之用。與其類似的則是參考資料區塊也需要處理現有的框架。對於各種不同的應用領域─包括大多數的視訊壓縮類型在內,這點相當的重要。
範例1中所示為使用雙重緩衝,以音訊為基礎的的簡單範例。
範例1
有幾種方法可以將音訊資料送入處理器核心。舉例來說,在前景執行的程式可以輪詢序列埠看有無新的資料,不過這類型的移轉在嵌入式媒體處理器(embedded media processor)中並不常見,因為這樣會造成核心的無效率使用。
取而代之的是,將處理器連結至音訊編 / 解碼器時,通常會使用DMA引擎從編 / 解碼器的鏈結(類似序列埠)移轉資料至處理器中可以使用的記憶體。這個資料的移轉會在背景中執行,不會受到核心的干預。唯一的開銷就是一旦資料緩衝已經收到或是傳出時,需要設定DMA的處理程序以及中斷的處理。
在以區塊為基礎使用DMA將資料來回傳送於處理器核心的處理系統當中,DMA移轉以及核心之間必須要有「雙重緩衝」才能夠加以仲裁。有了這個機制,處理器核心以及獨立於處理器之外的DMA引擎才不會在相同的時間存取相同的資料,以避免資料相互干擾的問題。想要進行長度為N之緩衝區的處理程序,只要建立一組長度為2 × N的緩衝區即可。對於雙向的系統而言,必須要建立兩組長度為2 × N的緩衝區才行。如同(圖1a)中所示,核心對in1緩衝區進行處理並且將結果儲存至out1 緩衝區,而此時DMA引擎正在把in0填滿並且將資料從out0中傳送出去。(圖1b)所描繪的是一旦DMA引擎完成雙重緩衝的左半邊之後,它就會開始將資料移轉進入in1當中,以及從out1當中將資料移轉出來,而核心則會進行將資料從in0轉出以及轉入out0的處理程式。這樣的設定有時候會被稱做「 乒乓緩衝」( ping-pong buffering),因為核心會在雙重緩衝區的左半邊與右半邊輪流交換。
請注意到,在即時系統中,序列埠DMA(或是另一組受到音訊取樣速率所約束的周邊DMA)對時序預算(timing budget)具有支配性的地位。基於這個原因,區塊處理的演算法在進行最佳化時,必須要使其執行時間少於或等於DMA在從雙重緩衝區的一半轉入或轉出資料時所花費的時間。
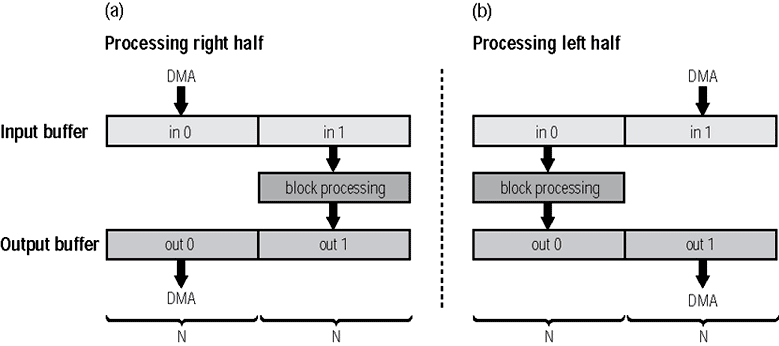
| 《圖一 針對串流處理的雙重緩衝架構》 - BigPic:779x346 |
|
在DMA與快取之間做選擇時的系統準則
在應用裝置中的資料流如果越複雜,在開始進行計畫案的架構佈局時就需要花更多的時間。在架構一組系統時,最基本的挑戰就在於決定哪個資料緩衝區在搬移時要使用DMA通道,哪個則應該要透過快取來進行存取,還有哪個要使用處理器的讀寫來做存取。我們接著來看看三種最為常用的系統設定,以便找出對於不同的系統等級而言,哪種方法才是最好的。
指令快取,資料DMA
這可能是最為常用的系統模型,因為媒體處理器通常都會以這個使用方式的輪廓來作為其架構。將程式碼予以快取可以減輕對於複雜指令流的管理負擔,但前提是應用必須能夠負擔得起這樣的奢侈。當系統沒有硬即時性的限制時,這個方式可以運作的很完善,因為快取失誤(cache miss)不會對於緊密結合之事件的時序造成嚴重的破壞(舉例來說,視訊的更新或是音訊 / 視訊的同步)。
同時,當處理器的性能遠遠的超越了處理上的需求時,將指令予以快取往往是個可以採用的安全方法,這是因為快取失誤不太會導致瓶頸的產生。雖然考量一個在現實上能否使用的”特大”(oversized)處理器似乎顯得不太尋常,但是考慮是一組能夠對壓縮的視訊與音訊進行解碼的可攜式媒體播放器的情況。當其處於純音訊模式時,性能上的需求只不過是在進行視訊播放時所需要的一小部分而已。因此,在每個模式下的指令 / 資料的管理機制都可能不同。
對於大部分的多媒體應用而言,透過DMA來管理資料是最自然的選擇,這是因為它們大多會牽涉到壓縮與未壓縮之視訊、圖形、以及音訊等大型緩衝的處理。除了在某些情況如資料為準靜態(quasi-static)(例如:固定顯示在螢幕上的一個圖形圖示)之外,將這些緩衝區進行快取是沒有意義的,這是因為資料會快速而且持續的改變。再者,如同先前所討論的,在同一時間內通常都會有多重的資料緩衝區在晶片的四周進行搬移─像是將調整的未經處理區塊、經過局部調整而需暫時儲存的區段、以及經過完全處理要送往外部顯示或是儲存裝置的區段等。DMA是管理緩衝區的理想工具,因為DMA允許核心在這些緩衝區上運行,而不需要擔心如何去對這些緩衝區進行搬移。
指令快取,資料DMA/快取
這個方法與剛才所討論的相似,除了在這種情況下有部分的L1資料記憶體被分割做為快取,而剩下的部分則作為DMA存取之用的SRAM。對於在處理牽涉到許多靜態係數或是對照表(lookup table)的演算法則而言,這個架構非常的有用。舉例來說,將正弦/餘弦表儲存在資料快取中可以提高FFTs的快速運算能力。或者,也可以將量化表(quantization tables)予以快取,這樣將可以促進JPEG的編碼與解碼能力。
請記得這個方法牽涉到一個在本質方面的權衡。雖然應用可以獲得以單週期來存取常用的常數以及表單,可是同時也會犧牲掉等量的L1資料SRAM,因而也會對單週期存取資料可用的緩衝區大小造成限制。想要對這個權衡進行評估,試著改變在Statistical Profiler(在許多的開發工具組中都有提供)之中的架構(資料DMA /快取 vs. 只有DMA),以便判定在每個環境下有多少百分比的時間是花在程式碼區塊上,這會是一個很有用的方法。
指令DMA,資料DMA
在這個架構裡面,資料與程式碼彼此之間的依賴性如此緊密的交纏,以致於開發者必須對指令與資料區段何時要透過晶片來搬移進行手動的排程。在如此的硬即時系統當中,確定性是必要的,因此快取並不適用於此。
雖然這個方法需要較多的規劃,但是所換取到的好處就是具有確定性的系統,其中程式碼總是會在資料需要其執行之前就能夠準備好,而且不會有資料會因為緩衝溢出而遺失。由於DMA的處理程序可以彼此連結而不需要核心的介入,因此一個新的處理程序之啟始就足以保證前一個程序已經完成,而資料或是程式碼的搬移是否發生也會被予以確認。這是想要將資料以及指令區塊同步化最有效率的方法。
基於另一種原因,指令/資料DMA的組合也很值得注意。當一般直接存取快取無法使用時,該組合提供了一種很方便的方法,可以在模擬與除錯階段時就先在系統中測試程式碼以及資料流。因此程式設計師可以在系統設定中進行調整,或是將「易出故障點」( trouble spots)強調出來。
有個需要將指令與資料都使用DMA處理之系統的範例,那就是視訊編碼/解碼器。當然,視訊以及其相關的音訊需要是確定性的,以便使用者獲得滿意的體驗。假如DMA在每次完成緩衝區移轉之後就對核心發出中斷信號的話,這將會對系統帶來很明顯的潛在問題,因為相對於其他的事件,中斷具有較優先完成的特性。在一個中斷服務例行程序的啟始與結尾處所發生的環境切換,會消耗數個核心處理器的週期。所有的這些因素都會對維持系統確定性的主要目標造成阻礙。(圖二)與(圖三)提供在選擇對指令與資料採用快取與DMA的準則,以及在使用快取與使用SRAM之間之權衡上的指引,這些都是以我們先前所討論過的內容為基礎。
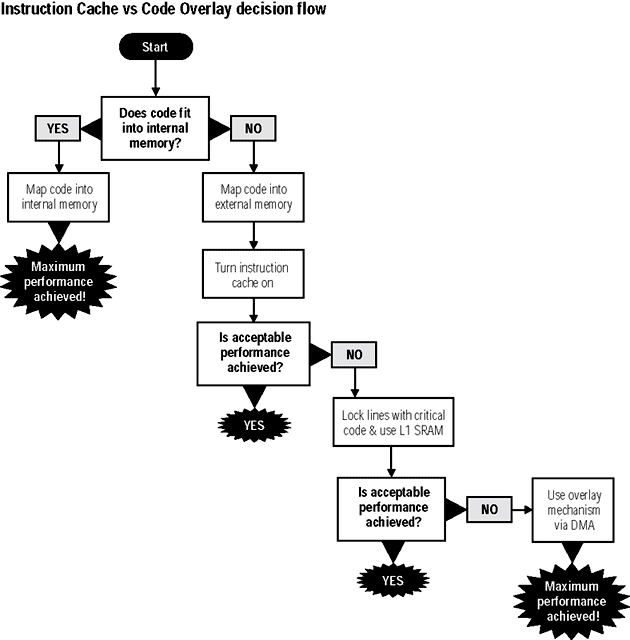
| 《圖二 在指令快取與DMA之間做選擇時的核對清單。》 - BigPic:630x640 |
|
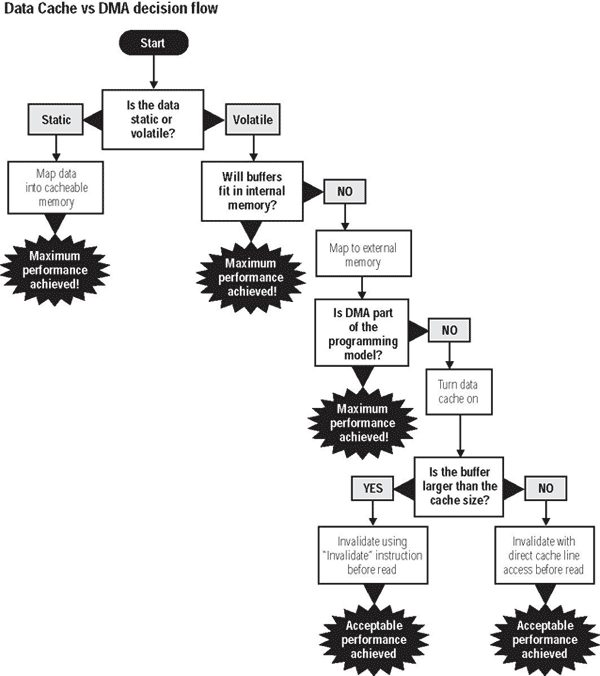
| 《圖三 在資料快取與DMA之間做選擇時的核對清單。》 - BigPic:600x676 |
|
在接下來關於DMA之討論的第四部份中,將會針對一些先進的DMA議題進行討論,其中包括了優先(priority)與仲裁(arbitration)架構、記憶體移轉效率的最大化、以及其他的複雜議題等。


