近年來,產品設計工程師需要進行即時視訊或影像分析,按照醫用、工業和軍事系統的一般需求必須採用成本很高的專用處理器。然而,隨著定點、高性能嵌入式媒體處理器的出現,經濟有效的即時影像處理已成為可能。為了開發真正高效率的演算法,充分利用這些處理器所提供的結構特性對產品設計工程師來說是很必要的。本文將討論數位影像濾波演算法能夠如何利用嵌入式媒體處理器結構的多媒體人性化特性。該媒體處理器的特點和指令集可用作一個參照點,但是同樣的概念通常也適用於高性能媒體處理器。
現在,雖然定點處理器的時脈超過300MHz,但是僅僅增加時脈並不能確保適合即時視訊濾波的功能。同樣重要的是連接多媒體的結構特性和專用視訊指令。
大多數視訊應用需要處理8bit資料,因為單一個像素分量(無論是RGB還是YUV)通常是基於位元組的資料。因此,8bit視訊演算邏輯單元(ALU)和基於位元組的位址資料在像素處理中會有很大不同。這一點非常重要,因為數位信號處理器(DSP)通常採用16bit或32bit資料工作。
另一特點是具有一個靈活的資料暫存器(Register)。在傳統的定點DSP中,字長通常是固定的。然而,資料暫存器具有的一個優點是能以一個32bit字(例如R00)或者兩個16bit字(例如R0.L和R0.H分別代表低16位和高16位元)來處理資料。這種結構的應用將在下面介紹。
專用的單周期指令可以非常方便地提供高效的多媒體編碼演算法。這種應用的一個很好範例是 “絕對差的和”指令能同時將幾個像素集之間的差值相加,從而表明在兩訊框之間的場景變化有多大。
二維影像卷積
由於一個視訊流實際上是一個以一定速率運動的影像序列,所以影像濾波器需要足夠快的工作速率才能跟上輸入影像的連續運動。因此,必須最佳化影像濾波器內核以便占用盡可能最小的處理器周期。這可以利用分析二維卷積(Convolutional)的一個簡單影像濾波器組來說明。
卷積是影像處理中的一個基本運算。一個給定像素的二維卷積計算是將其直接鄰域像素的亮度按權值相加。由於一個遮罩的鄰域集中在一個給定的像素中心,所以該遮罩通常具有奇數維數。該遮罩的大小通常比影像小,並且經常選用一種3×3的遮罩,因為它在每個像素基礎上的計算是合理的,但是足夠大才可以檢測出一幅影像的邊界。
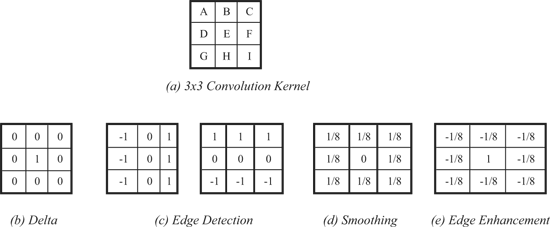
3×3內核的基本結構如(圖一)(a)所示。例如,位於一幅影像第20行第10列的像素卷積過程的輸出應該是:
Out(20,10)=A×(19,9)+B×(19,10)+C×(19,11)+D×(20,9)+E×(20,10)+F×(20,11)+G×(21,9)+H×(21,10)+I×(21,11)
| 圖一 : (a)3×3內核的像素卷積遮罩及其使用方式 |
|
重要的是按照一種輔助計算方法來選擇係數。例如,比例係數首選是冪指數為2(包括小數),因為乘法可以利用簡單的移位操作來替換。
圖一(b)~(e)顯示幾種有用的3×3內核,每一種內核都簡述如下:
- ●圖一(b)顯示出的δ函數是最簡單的影像處理函數,當前像素不經修改直接輸出;
- ●圖一(c)示出了邊界檢測遮罩的兩種常用形式。第一種檢測垂直邊界,而第二種檢測水平邊界。高輸出值對應較高的邊界出現;
- ●圖一(d)的內核是一個平滑濾波器。它計算當前像素周圍八個像素的平均值並且把結果放在當前像素的位置上。它具有 “平滑”或者“低通濾波”影像的作用;
- ●圖一(e)中的濾波器稱為“模糊遮罩”操作。它可認為通過從當前像素中減去一個平滑的當前v像素(通過取其相鄰的八個像素平均值得到)產生一個邊界增強的影像。
以嵌入式媒體處理器達成影像卷積
以下將進一步討論二維卷積過程。其高階演算法可按下述步驟:
- (1)將遮罩的中心放在輸入矩陣的一個元素上;
- (2)位於該遮罩鄰域內的每個像素乘以相對應的濾波器遮罩元素;
- (3)將每次乘法結果相加得到一個結果;
- (4)將每次相加後的結果放在輸出矩陣中遮罩中心對應的位置上。
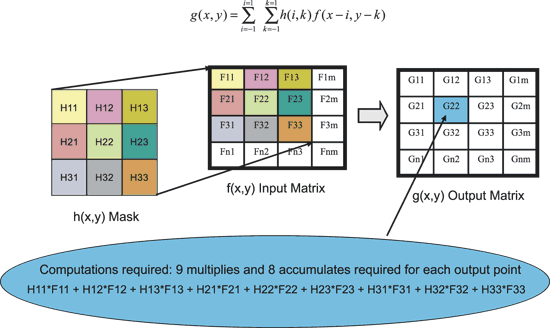
(圖二)顯示3個矩陣:一個輸入矩陣f(x,y),一個3×3遮罩矩陣h(x,y)和一個輸出矩陣g(x,y)。
對每個輸出點計算後,該遮罩被向右移一個元素。在影像的邊界,該演算法繞回下一行的第一個元素上。例如,當將遮罩集中在以元素F2m為中心時,該遮罩矩陣的H23元素乘以輸入矩陣的F31元素。結果使輸出矩陣的可用部分在影像的每個邊界都減少了1個元素。
對於一個30 幅/秒的視訊圖形陣列(VGA;640×480像素/幅),其影像播放速率達到每秒9.2M。現在考慮如果9次乘法和8次加法需要串列來達成,運算速度將是(9+8)×9.2=156Mips。如果加法和乘法並行執行,那麼運算速度降低為9×9.2=83Mips。下面的例子將說明如何節省2倍的運算周期。
高效二維卷積之實例
下文中將討論所有乘法累加器(MAC)運算的“內部”迴路。這個範例將證明只要適當地對齊輸入資料,MAC單元就能夠在一個處理器周期內每次處理兩個輸出點。在相同的周期內,讀取與MAC運算同時執行的多個資料。
這個應用的關鍵部分是內部迴圈,如(圖三)所示。內部迴圈的每條線路都按照單周期指令執行。輸入資料以16bit數表示。輸入矩陣的開始必須對齊32bit邊界,這將確保輸入矩陣的兩個連續點可以在一個32bit的操作中被讀取。在進入此迴圈之前,該輸入矩陣的第一個值保存在R0.H中並且它的第二個值(F12)保存在R0.L中,正如圖三所示的第一周期前2個運算。暫存器R1.L也必須在進入內部迴圈之前置入。它包含遮罩矩陣(H11)第一個元素的值。
正如前面所述,為了獲得該輸出矩陣的每個元素需要九次乘法和八次加法運算。但是,由於是雙MAC運算,兩個輸出元素可以在每個內部迴圈結束時獲得。因此,F11×H11和F12×H11可以在第一條指令結束時在加法器中獲得。內部迴圈的每條指令都轉向下一個遮罩值。其結果將在單獨的累加法中累加。該內部迴圈的最終輸出置入R6中。
多個數學運算不僅僅同時出現在每個周期中,而且置入和保存可平行作業以便進一步提高效率。以第一周期為例,下一個輸入元素(F13)讀入R0.L中並且在隨後的一個指令中用於一個MAC運算。類似地,將下一批遮罩值裝入R2。這些值將用於該內部迴圈的後續MAC操作。
結論
隨著影像濾波技術的進步,3×3遮罩二維卷積的達成是相當明顯的。上文中介紹的研究結果示範了如何選擇一個適合即時影像處理的處理器,並瞭解其結構組成以便提高演算法效率、減少執行周期(這裏為原來的1/4)。且此種處理器還能為在同一個平臺上達成更複雜的影像處理功能提供更堅實的基礎。(作者任職於美商ADI Blackfin處理器應用開發部門)