所謂的網頁探勘(Web mining),主要就是利用文字或資料探勘(text/data mining)的技術,針對網頁的特性,自動從網頁上擷取、發掘出一些特徵與規律(pattern),並希望能應用在各個領域。
為何需要Web Mining?
Web Mining 從字面上來看,簡單的說就是從全球資訊網(WWW)的豐富資源中“採礦",挖掘出重要的資訊。隨Web快速的成長,世界各地的使用者,根據他們所關心的主題,持續不斷地加入並更新各式各樣的內容,並以網頁的形式整理資料。目前全球被搜尋引擎所索引(index)的網頁,已經超過42億頁,這只是冰山的一角,並不包括沒有被收錄的部分。因此,它已經是世界上最龐大的動態知識來源了。然而,如何從這麼豐富的網頁資源中擷取、並分析出有用的資訊則是目前主要的研究課題之一。
由於Web是個豐富的動態資源,不論在何種領域都可以找到一定程度的相關資料,因此對於各種型態的資料分析、知識擷取都有很大的助益。但是要在如此龐大的資源中,擷取出真正想要的資料,還真是不太容易。目前常見的做法是透過搜尋引擎,如 Google、Yahoo、Alta Vista等,以關鍵詞查詢(query)的方式來搜尋。運作的方式大多是以crawler(spider,搜索器)先盡量將全世界的網頁收集下來,然後根據關鍵詞出現的頻率及在文件中分布情形,來決定出每個關鍵詞最相關的文件,並依重要性順序排列。然而,如果關鍵詞太普遍或是不夠精確,搜尋結果還是太多,使用者仍像大海撈針一般,無法真正從中找到足夠多且有用的相關文件。
從資訊擷取的角度來看,各種方法的目的都希望能提升搜尋的精確度(precision)和召回率(recall),除了希望找到的資訊有更高比例是有用的,更希望所須的資訊都能盡量被找出來。因此,必須將Web 資料做更有效的處理分析。
網頁的特性
一般資料探勘所針對的對象是結構化的資料(structured data),通常是儲存在資料庫(database)中,擁有明確定義、已知欄位的資料。而文字探勘(text mining)則不限定資料來源是資料庫,舉凡一般非結構化的文字文件(textual document),如新聞報導、報章雜誌的文章等,都可能是分析的對象。網頁則是一種半結構化資料(semi-structured data),與一般data/text mining不同的是,網頁雖有其特殊的連結(link)結構,可以從中取得一些資訊,如網頁間的關連(association),但是每個網頁本身的內容並沒有限定其呈現方式,它類似文字文件,卻又包含各式多媒體資料,因此可能會比一般的文件或資料庫更難以擷取出有用的資訊。因此,我們便希望利用網頁特性,以及text/data mining既有技術,找出Web中有用的資訊。
Web Mining的架構
目前Web mining技術大致可以分為三類:網頁使用探勘(Web Usage Mining)、網頁結構探勘(Web Structure Mining),以及網頁內容探勘(Web Content Mining),分別針對使用者對網頁的存取情形、網頁與網頁間的連結狀況,以及網頁內容本身所包含的資料加以分析。以下便分別敘述其架構。
網頁使用情形探勘
每天全世界有許多人連上各式各樣的網站,與現實社會同樣有著種種行為,不論是查詢資料、購物、或打發時間。 對於經營網站的人而言,尤其是購物網站,對於消費者一定希望有相當程度的了解,以針對需求來提供更符合顧客特性的多樣化商品及服務。所以,如果能將所有消費行為加以分析,便可能可以找出一些規律。例如針對上網站的族群、年齡層、職業、區域、商品種類、金額...等,便可進一步掌握消費者心理,提供個人化服務。
又例如在一個公司內部,老闆希望了解員工在上班時間都上些什麼網站,是否偷偷進行與公事無關的行為,如上網購物、看股票、上成人網站等。經由公司內部Web Usage Mining分析也能一探究竟。
另外,網站管理員可能希望經由網頁存取的記錄(Web access log),分析出網站的最大負荷、出現的時段,以及使用者來源,並且進一步找出瓶頸甚至發現異常流量或大量存取,以便發覺網路入侵者或是robot的行為。
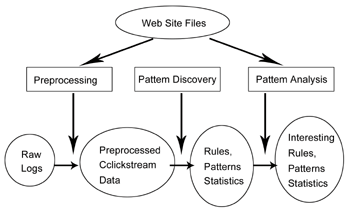
通常Web Usage Mining的進行方式如(圖一)所示。 網頁的每一個瀏覽動作在伺服器端必定會留下記錄(log),分別記下每一次存取(access)是發生在何時(time)、來自哪裡(IP address)、存取了哪個網頁。 因此第一步先要將伺服器的存取記錄(server access log)作前處理(preprocessing),依網頁、每台機器、使用者,以及使用者所按下連結的順序(clickstream data),分別處理以便進一步的分析。第二步發掘規律(pattern discovery)才是真正從中發現規律性,或是規則。最後,進行規律分析(pattern analysis),依據需求分析出有用的規律、規則,或統計數據。
網頁結構探勘
網頁與網頁間的結構,最主要是以超連結(hyperlink)串連起來,如(圖二)所示。通常,hyperlink除了指向目的網頁的網址(URL)外,還會有一小段文字描述,叫做標示文字(anchor text),用來輔助說明目的網頁。通常網頁間的連結有幾種不同的意義:第一,作者對目的網頁表示認同、肯定(endorse)或是推薦(recommend);第二,作者僅只是提供網站連結,純屬參考(reference)之用;第三,可能是常用網站,或是相關訊息,用連結整理方便日後使用。因此,整個WWW便是由網頁以及連結所交織而成的網(Web)所構成。
網頁與網頁間的連結很容易令人聯想到一般社會中人際關係的網絡(social network):把網頁比作個人,把連結比作人與人的關係(如朋友、父子、夫妻、兄弟等),其原理是很類似的。社會網路分析(social network analysis)是社會學科被廣泛研究的主題,抽象來看,Web的網頁及連結其實可以抽象地看成是graph中的節點(node)和連結(link),運用類似的方法,我們可以計算出網頁與網頁間的關係與相對重要性的排名(ranking)。例如:PageRank [6]和HITS (Hyperlink Induced Topic Search)演算法[5]便是著名的網頁排名演算法(ranking algorithm)的例子。簡單地說,只要稍微分析一些網頁連結情形,便可以發現有些網頁是所謂的hub,也就是集中整理了許多相關或重要資訊的地方,例如入口網站(Web portal site)或是網路黃頁或目錄(yellow page);而有些網頁是所謂的authority,即是許多人都一致推薦或參考的網頁,例如著名的大公司、重要的機關團體...等都是屬於authority。 雖然後來實際的搜尋引擎如Google,並非採用原始的PageRank or HITS演算法,但是基本精神仍然類似。
網頁內容探勘
網站的內容是最有彈性、最複雜、卻也最豐富的一項資源,除了文字文件(textual document)之外,更可能包含了各式各樣多媒體內容。例如:從個人網頁中,我們想了解他的興趣、嗜好、學經歷... 等,可以透過網頁內容加以分析。又如各公司想得知其他競爭對手的現況,也可以分析公司網頁的內容,進一步了解它的主要產品、屬性、市場區隔、佔有率...等。
網頁內容與資料庫或一般文件不同的是,作者是來自世界各地的自願維護者,而且內容隨時都有可能更新,因此,網頁內容非常多樣化(diverse)。 但由於來源非常參差不齊(heterogeneous),內容的正確性並無統一機構負責校對或更正,所以網頁的內容常常也包含許多雜訊(noise)。 如何從龐大,不一致的資料中,抽取出正確或是有用的資訊,也成為目前最主要的挑戰。目前常見的方式是透過現有的搜尋引擎,作為最基本的資料取得來源,如(圖三)所示。從搜尋結果中,我們再經由進一步的處理、分析,以得到更好的結果。
由於網頁內容龐雜,光是內容的分門別類就不是一件容易的事。因此,在網頁內容探勘中,最主要的兩項關鍵技術是分類(classification)與分群(clustering)。在機器學習(machine learning)中,一般把這兩項技術稱為監督式學習(supervised learning)及非監督式學習(unsupervised learning)。
如(圖四)所示,分類(classification)的工作主要是先將一些已標記有類別(class)或標籤(label)的訓練資料(training data),利用機器學習的各種方式,訓練出一個足以代表這些資料特性的模型(model)。當一個未知類別的資料進來時,我們可以經由這個模型而“猜出"這項資料的所屬類別,這就是分類(classification)。
所謂的監督式學習就是因為學習過程中,先使用已標有正確答案的訓練資料訓練過了。
另一方面如(圖五)所示,分群(clustering)則直接面對一堆雜亂的資料,將相似的資料分在同一群,想辦法從中找出規則。由於不須要訓練資料,因此又稱為非監督式學習。分群又可以分為兩種方式:bottom-up及top-down。Bottom-up是由個別資料逐漸群眾而成,最後形成整堆資料;而top-down則是先將整堆資料分為幾大群,然後各自再加以細分。這兩種技術各有優缺點,也各有適用的情形。
Web Mining的廣泛應用
由以上三類架構的介紹,我們可知Web Mining目前的應用相當廣泛,不同領域都可應用Web mining 的技術,是一項跨領域應用的技術。首先Web這個最大的知識來源,可以發掘出有用的資訊,進一步提升各領域中原有技術的瓶頸,例如搜尋引擎本身就有許多改進的空間,藉由搜尋結果的Mining,我們可以再改進搜尋引擎本身。而在商業情報(Business Intelligence,BI)和客戶關係管理(Customer Relationship Management,CRM)方面,也存在許多應用。例如分析競爭對手、產業動態及市場消長等。CRM 方面除了對所有顧客加以分析建立user profile之外,也可提供個人化服務。
其他如數位典藏(digital libraries)方面,利用mining技術也使得分類、檢索及知識管理上,有許多應用。例如Web mining可以幫忙找到(辭典中未收錄的)未知詞的翻譯,例如新術語、專有名詞等。另外,在情報(intelligence)及安全(security)方面,也逐漸有其應用,例如利用網路上的資源,如媒體報導或是深度評論等,分析出恐怖份子及組織的概況,進行反恐(anti-terrorism)的研究。最近在醫療資訊(medical informatics)方面,text/data mining的技術已開始被大量應用,然而在Web knowledge對醫療資訊的幫助上,仍有待觀察。
Web Mining的瓶頸與挑戰
目前Web Mining技術仍有些瓶頸與挑戰,有待突破:
1. 網頁呈現方式(presentation)不一致
網頁的外觀(layout)、主題(thematic)或metadata(欄位)相關資料取得不易,甚至連資料本身都可能難以抽取出來。一般Web 作者可能來自世界各地各行各業,除了格式為HTML之外,網頁畫面的呈現方式及安排則是每個作者自由發揮,並無統一標準或硬性規定。因此,資料的呈現雖然對使用者很容易一目瞭然,但是對一個程式來說,在收集資料的困難度自然就提高了。
2. 程式本身背景知識(background knowledge)不足
程式本身依照程式設計師(programmer)所設計的演算法依序執行,但是它在一般人所具備的常識(common sense)或背景知識不足。例如個人網頁上可能會顯示一個人的基本資料,包括生日、血型、星座、興趣、學歷、經歷...等,人們一看便清楚,但是對程式而言,這些欄位本身的意義並無法單獨從網頁得知,必須另外學習,或由程式設計師賦予意義。
3. 領域知識(domain knowledge)與自然語言理解能力欠缺
由於網頁是呈現給人看的,因此,Web上許多資訊是以自然語言的文句所描述的,而且與該內容相關領域的domain knowledge有密切關係。但是對程式而言,自然語言處理(Natural Language Processing,NLP)的技術尚未成熟到足以理解任意自然語言句子的語意,同時對某一特殊領域的知識更是須要補足,這也是另一項挑戰。
Web Mining未來趨勢與方向
由上述幾項挑戰,不難看出Web Mining已成為熱門技術之一。 未來除了繼續在網頁內容探勘及文字/資料探勘的技術能有所進展之外,發現更多更新的應用仍是這項技術持續進步最主要的動力。如何以電腦程式發展出足以擷取、整理,甚至分析雜亂的網頁知識,進而提出有用的建議,更是未來必須突破的挑戰。
人工智慧或是全能的機器人也許目標仍遠大了些,但是,藉由知識發掘(Web knowledge discovery),電腦還有太多須要學習的“常識",如何教導電腦上網學習,並進而改進其”智能"(Web Intelligence)正是未來極有潛力的方向。但是要有突破性的發展,仍然有賴資料庫(Database,DB)、資訊擷取 (Information Retrieval,IR)、機器學習(Machine Learning,ML)、人工智慧(Artificial Intelligence,AI)、乃至自然語言處理(Natural Language Processing,NLP)等基礎領域技術的持續發展。
(作者任職於中央研究院資訊科學研究所)
參考資料
1. S. Chakrabarti, Mining the Web: Discovering Knowledge from Hypertext Data, Morgan Kaufmann, 2002.
1. Web Mining Resource, http://www.cs.ualberta.ca/~tszhu/webmining.htm
2. U. Y. Nahm, A Roadmap to Text Mining and Web Mining, http://www.cs.utexas.edu/users/pebronia/text-mining/
3. Web Mining Survey - Some Pointers, http://www.cs.umbc.edu/~kolari1/Mining/webmining.html
4. J. Kleinberg, "Authoritative Sources in Hyperlinked Environment," Proceedings of the 9th ACM-SIAM Symposium on Discrete Algorithms, pp. 668-677, 1998.
5. S. Brin and L. Page,"The Anatomy of a Large-Scale Hypertextual Web Search Engine," Proceedings of the 7th World-Wide Web Conference (WWW 1998),1998.
|
|
|
資料探勘(Data Mining)是一項很有趣的資源探索,能夠挖掘出有用的資料。如同在礦山裡採礦一般,所挖掘出來的結果往往都會令人驚奇不已。相關介紹請見「擁有驚人預測能力的Data
Mining」一文。 |
|
資料探勘是指從大量的資料中,去尋找有用或潛在的資訊或知識,而網路資料探勘(Web
Mining)則是將資料探勘的工作運用在大量的網路資料上,以改進網路上的資訊服務。你可在「網路行為大預測
– Web Mining 」一文中得到進一步的介紹。 |
|
現今所謂的CRM大約分為兩類,一為分析式CRM、一為操作式CRM,而分析式之CRM更是操作型的基礎,有了資料倉儲之基礎建設,再往上建置不同系統,將收加乘之效果。
在「如何應用資料倉儲發揮CRM效益」一文為你做了相關的評析。 |
|
|
 |