文字如同語音在聲音訊號中的標準性一般,是影像訊號中的通訊標準。工研院前瞻技術中心早期也發展文字辨識(Character Recognition)技術,包括光學和手寫文字辨識,特別是手寫辨識現在已成為手持設備重要的輸入介面,目前為商品化技術。近年來,在影像視訊上的技術發展逐漸轉向各種電腦視覺處理的研究,特別是在有關安全監控方面的應用。
影像與視訊檢索技術
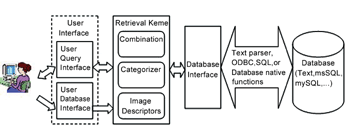
目前使用者對資訊型態的要求,已由純文字演進到多媒體,即包括聲音、靜態影像、視訊等,其相對應的檢索技術也應運而生。一般影像與視訊檢索技術僅定義了各種特徵的擷取和比對方式,但卻無法判別個別媒體內容以何種特徵描述為最佳。而這樣一來,便無法達成有意義、高效率的檢索效果。
目前研究單位正在發展能自動依據影像內容選取適合特徵的系統,能夠進一步以互動的方式探知使用者的需求,並整合各項特徵資訊,以傳回使用者真正想要檢索的影像。這種整合檢索方式,可突破傳統單一查詢影像、單一描述的限制,達成較傳統方式快速而精確的成果。
人臉辨識技術
想像一下,當您使用電腦或手機時不用再記住一大堆密碼該有多好?以人臉辨識為例,它是屬於生物辨識(Biometrics)其中一項技術,就如同指紋、聲音、瞳孔與熱影像等用來當作身分識別的特徵。而人臉有別於這些特徵,且收集比較容易,不會造成使用者的不方便與不舒服,所以一般人的接受度較高。
財政部於2003年時,為了打擊人頭戶氾濫所衍生的金融犯罪,要求所有銀行於2004年3月底前,建置完成拍照開戶或錄影開戶的動作。個人隱私雖是一個很大的問題,但隨著加解密技術與驗證方式的進步,個人資料外洩的疑慮已大幅降低。目前,國外已有將人臉辨識技術用在過場旅客的濾機機制上的例子,以防範偷渡客持有他人身分證件。
以工研院所開發的人臉辨識技術來說,可以從平常的照片中即時找出所有人的臉部位置,並且根據其五官等重要特徵來辨識身分。而對於小角度轉頭或各種表情、有無戴眼鏡、換髮型等動作都不會照成任何的影響。我們以200人的實驗來說,其辨識率可達到95%以上。
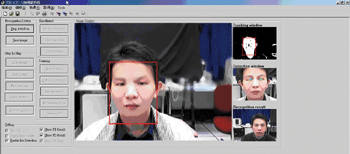
| 《圖二 中間圖為使用者影像,右下角的小圖則是辨識出來的身分》 |
|
自動櫃員機的人臉遮蔽/非遮蔽偵測技術
近年來,自動櫃員機盜領、改裝、側錄與盜刷的事件層出不窮,財政部為了杜絕這些犯罪情形,規定國內金融機構於2004年6月底前,在旗下的自動櫃員機建立24小時監控中心。其實許多銀行早就在自動櫃員機裝設了錄影設備,但在犯罪發生後,所攝錄到的歹徒往往戴著安全帽或口罩,並無法從影像辨識身分。人臉遮蔽/非遮蔽偵測技術,就是要在第一時間發現臉部被遮蔽的可疑人物,以提醒警衛人員注意,並且避免無效的錄影存證。目前這種在自動櫃員機設置的主動式智慧型監控技術,已在日本與歐洲逐漸開始實行,國內還屬於起步的階段。
工研院的人臉遮蔽/非遮蔽偵測技術主要是比對人臉的眼、鼻、口等部位是否清楚,並作判斷的動作。而對於戴口罩、安全帽、用手摀住嘴或遮臉等情形都可以偵測出來,且不會造成正常使用者的困擾。目前這個技術在開發與改善中,其雛形系統也已在國內的一些保全業者內部作測試的階段。

| 《圖三 左圖:臉被遮蔽的Alarm狀態,右圖:臉沒有被遮蔽的正常(Clear)狀態》 |
|
多元模式人機互動技術
人類互動常常是結合多種感官同時進行,例如使用者在說話時,結合手勢與臉部的表情。而機器的操作往往也使用多種模式的配合來執行命令,以增進操作的效率與方便性,例如鍵盤與滑鼠的搭配輸入、螢幕顯示與聲音輸出的搭配使用等。因此,結合語音及視覺的多元模式互動技術,也是未來發展的重點之一。
多元模式人物辨識技術
生物特徵識別是一項熱門及新穎的主題,也是近年來學術界和工商界極為重視的一種安全認證方式。而生物特徵識別普遍所用到的生物特徵包含指紋、掌紋、聲紋、人臉、視網膜、手型、耳型,及嘴唇等運動模式。
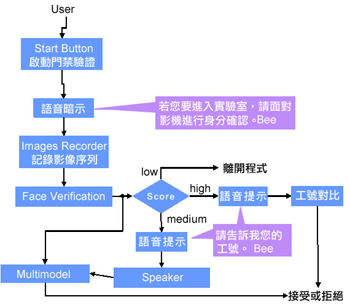
工研院所研發的一套多元模式系統,可辨識人臉及語音兩種特徵,並應用在門禁管制系統中。因為人臉和語音並不是外在的物品,所以不用特別攜帶,且別人也不容易仿冒。至於其他的優點還包括使用方便(人性化)、適用性廣泛(可依安全性需求來調整)。若配合人機介面的系統,更能充分發揮生物特徵識別的優點及功能。
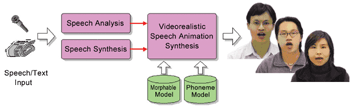
人臉說話仿真技術
藉由說話影像與語音資料的處理,以及多維可形變模型的技術(Multidimensional Morphable Model),來學習影像與語音之間的關連性。多維可形變模型是將每張影像的形狀與紋理加以參數化,讓每張嘴型影像得以由其形狀與紋理參數形,變為少數的樣版影像(Prototype Images)來加以合成。
在將影像參數化之後,我們可以得知語音與影像參數之間的關係。把這些參數變化的路徑分析與合成後,使得只要輸入語音或文字,便能計算出其中每個語音音素所佔用的時間,如此即可求出最佳之影像參數路徑,並藉由多維可形變模型的技術來合成出擬真的人臉動畫。
此技術可透過輸入語音/文字的驅動,來進行說話影像視訊合成。而其中所包含的技術有語音的分析處理或合成技術,以及相對應的影像合成技術。
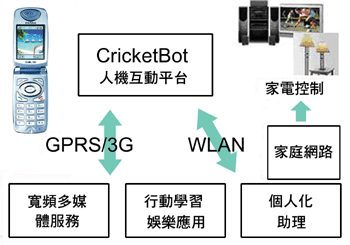
個人化可配置分散式人機互動平台
此平台的核心為可配置分散式語音辨識C-DSR(Configurable-Distributed Speech Recognition),這是一個可以累積個人化語音資料與對話場景資訊的平台。而在C-DSR平台上的各種擬人化造型、可與之互動的虛擬生物,則被稱為「CricketBot」。
CricketBot是利用Client-Server的架構所建立,並可分為「使用模式」及「編導模式」。利用與虛擬生物對話的情境,人們較會主動願意利用語音辨識與機器做擬人般的互動。當使用者與系統互動越頻繁,此平台主動、被動蒐集的資訊就會越多。如此便可以讓互動機制成熟和互動效果越成熟與平順。這種平台可以作為個人化的人機互動介面,並深植於各種實際應用之中。
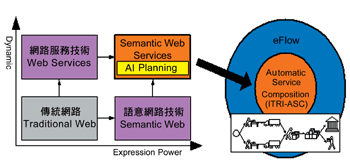
語意網路服務
網路服務(Web Services)的作用是增加傳統網路的動態連結性(Dynamics),而語意網路(Semantic Web)的作用則是增加傳統網路的知識表達能力(Expression Power)。顧名思義,語意網路服務(Semantic Web Services)整合了兩者的優點,並突破智慧型規劃(AI Planning)缺乏動態調整的限制,實現自動服務組合的概念。
語意網路服務的優點在於電腦可動態地依據使用者的需求,自動尋找適當的服務,並組合成e化工作流程。比起傳統的人工流程組合,這個技術更可增加開發與維護e化工作流程的效率。
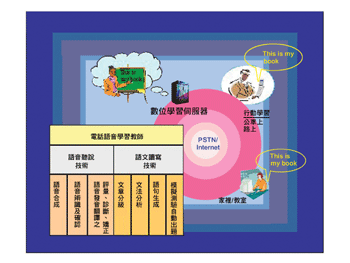
認知仿真語言數位學習技術
認知仿真語言數位學習技術是一種可以輔助語言學習的相關技術,其中包括發音與韻律之評量、診斷和矯正等語音處理技術,以及文章分級、文法分析、語句生成等語文處理技術。其終極目標是希望在電腦環境上建構出個人專屬的語言學習教師,讓學生不受時或地的限制,隨時隨地都能夠學習。
這名電腦教師可以像普通的老師一樣,訓練學生的聽、說、讀、寫能力,如示範正確的讀音、糾正發音的錯誤、指導寫作、模擬測驗,及練習口語會話等。
其它智慧型人機介面技術
除了上述的人機介面技術外,其它還有幾個較為值得一提的技術,以下就替這些技術作個簡介。
視覺性互動式遊戲 有氧熱舞機技術
熱舞機雛形展示系統的概念為利用遊戲畫面與音樂引導玩家舞動身體,並透過攝影機來擷取玩家肢體動作,然後再利用影像處理核心技術進行分析、辨識,及判斷玩家動作是否正確而予以計分。
熱舞機的核心技術包含兩種,分別是使用去背法(Background Subtraction)偵測出前景資訊、使用隱藏式馬可夫模型(Hidden Markov Model,HMM)進行動作模型訓練與動作辨識。配合人機介面的設計,以及結合影像處理技術與運動休閒,提供玩家與運動愛好者一項新型態的電子遊戲。
雷射光點偵測與應用技術
這是將影像偵測與追蹤雷射筆的雷射光點結合,並分析其運動軌跡的技術,可取代電腦遊戲的光槍射擊,或作簡報時所需的滑鼠操作。這類應用核心技術包含了兩部份,分別是影像與螢幕(投影幕)間的座標校準與轉換,以及影像中所出現雷射光點的偵測、追蹤與運動(軌跡)分析。
智慧型(主動式)人物入侵監控系統
智慧型(主動式)人物入侵監控統採用先進的電腦視覺演算法,其作用是在少量人力的協助下,系統會主動對攝影機拍攝的影像進行偵測、追蹤與分析。並利用分析的結果判斷入侵情形是否發生,以及入侵的種類主動發出警告。該系統可有效降低人力並增加監控的安全性與可靠性。其功能如下:
- ● 可判斷之警報(Alarm type):
- ●快速或慢速移動人物(intruder)
- ●攝影機遭受斷訊,轉向,遮蔽(camera error)
- ● 可避免之假警報(False alarm)
- ●輕微地震
- ●動物或昆蟲經過
- ●環境光源自然變化
- ●環境每天極小變化(如鏡頭髒污)
- ● 可即時判斷是否遭到入侵並且於螢幕上顯示警訊與入侵種類
- ● 若具有儲存裝置,可保留入侵前3張與後2張影像以作為蒐證用途
結語
個人化彈性配置的處理平台、生物特徵在安全性的應用、語意理解能力的網路服務,以及數位學習的應用等技術都是人機互動技術未來發展的新方向。就像人類是地球最高度複雜的生物一樣,人機互動技術也是極為深奧複雜,其發展趨勢與可能方向更是難以預測。唯一可以確定的是,人類對於瞭解本身奧秘的追尋,以及設計仿造如人類智慧之機器的企圖與夢想永遠都不會停止。
<作者為工研院電通所前瞻技術中心副主任>