近年來多媒體技術不斷進步,電影、電視、電子影像等傳播媒體快速發展,科技的進步使得各種影音資料大量的被數位化。要如何儲存如此大量新增的數位影音資料,以及如何保存過去所累積的影像與聲音文化資產,使其能被再生使用,是我們面臨的重要課題。
影音資料庫的架構
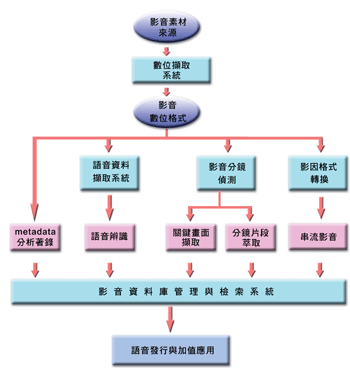
影音資料庫建立的流程大致包括影片取得、數位擷取、資料庫建置、加值使用,分別說明如下:
- (1)影片取得:影音素材取得之來源,包括數位與類比影音,例如:35mm影片、16mm影片、Betacam錄影帶、Digital Betacam錄影帶等。
- (2)數位擷取:將影音資料建檔、壓縮並轉換成數位格式。
- (3)資料庫建置:建立數位影音收藏環境,建立片庫管理系統以管理影片之後設資料(metadata)與視訊、音訊資料。
- (4)加值使用:包括影音隨選播放、影片剪輯、影音資料重新再製等工作。
- 影音資料庫建立流程如圖一所示:
關聯式資料庫
資料庫技術被廣泛的用來儲存與管理大量資料,目前的資料庫管理系統(DBMS)都具備優異的管理文字性資料能力,並能提供有效率之資料操作(如新增、修改、刪除、查詢等)。在各種資料庫產品中,關聯式資料庫已成為市場的主流,其技術已經發展的非常成熟,而資料操作之語法(SQL)更早已被標準化,各家資料庫發展廠商也都以關聯式資料庫為基礎,進而發展其它的應用。
在多媒體資料與影音資料之儲存方面,多數的關聯式資料庫管理系統提供了一種二進位大型物件(Binary Large OBject,BLOB)的資料類型,這種資料型態可以儲存二進位資料,以應付影音資料所需的大量儲存空間。BLOB資料型態無法支援修改及查詢之操作,資料之匯入匯出也必須透過程式來進行轉換與存取。
另一種常見的影音資料庫設計方式,是不改變原本影音資料之儲存格式,而將影音原始檔案直接儲存於檔案目錄中,其目錄結構則以影音檔名為依據或使用特定之雜湊(hashing)演算法決定。而影音之metadata資料與影音檔案所放置之位置,則儲存於資料庫系統之中。此種設計的優點是不需考慮資料庫管理系統是否支援多媒體影音之儲存方式,資料之讀取與寫入可以直接進行,不需要透過特殊程式之轉換;其缺點是影音數位物件與影音相關之metadata之間的關聯性,需透過額外的記錄與串連。
影音資料庫檢索技術
具備方便有效的檢索能力,是影音數位博物館能否普及的重要關鍵之一。目前影音資料庫檢索,大致可分為metadata檢索、全文檢索、語音檢索三種方式,分述如下:
Metadata檢索
根據影音metadata文字內容,區分為不同屬性之資料項目,如人物、主題、時間、地點等分類,查詢者可根據事先定義好的資料分類項目,輸入欲查詢之關鍵詞以進行影音資料檢索。此種檢索方式必需由人工先將影片內容之描述以文字輸入影音資料庫。若影音資料儲存於關聯式資料庫,可透過其所提供的資料查詢功能進行檢索,在系統實作上較易達成。對於查詢者而言,必需對資料分類項目有部份了解方可進行檢索。
全文檢索
全文檢索與metadata檢索方式相似,必需由人工先將影片內容之描述以文字記錄。主要的差別是使用全文檢索時,不需依照資料分類進行檢索,查詢者可輸入任意的關鍵詞進行整個影音文字資料檢索。全文檢索在系統實作上,需要搭配全文檢索的搜尋引擎(search engine)。對於查詢者而言,不需了解影音資料內容之分類方式即可進行,並可找出最多的相關資料。
語音檢索
過去,影音資料必須仰賴專人建立文字索引,方能利用文字資訊檢索技術提供使用者查詢檢索。然而,建立影片的內容描述必需耗費大量的人力與時間,且影片索引點往往僅包括人、主題、時間、地點等資訊或是少量的關鍵詞,並不是基於完整的內容,使得檢索的效果大打折扣。近年來,隨著語音辨認技術逐漸成熟,整合語音辨認與資訊檢索之語音檢索技術愈來愈受到重視。
語音檢索系統之建立流程需先把影片中之聲音部份抽離出來,並將雜訊去除,然後進行語音辨識工作。語音辨識會經過聲學模型(acoustic model)、詞典(lexicon)、語言模型(language model)處理後,將辨識結果儲存於語音資料庫中。使用者可以使用語音輸入或使用文字輸入的方式,將欲檢索的關鍵詞輸入;語音檢索系統會將關鍵詞轉換成對應的音節,於語音資料庫中進行比對,進而將比對結果傳回。
語音檢索相較於文字資料檢索的優點在於,使用語音檢索時不需由人工先建立影片內容之描述文字,且可對整個影片之完整內容進行檢索,不僅止於少量的關鍵詞文字;但其缺點是使用語音檢索之精確率不如文字檢索,若是影片中的聲音帶有大量的干擾噪音時,其辨識結果則更不理想。
影音分鏡偵測技術
如何準確的達成自動分鏡偵測(shot change detection)一直是影音註解工作人員最希望能自動化解決的工作。一般研究者將一個分鏡(shot)視為一個基本的影片片段,因此在一個多小時的影片中,就可能包含了上百個分鏡。若以人工的方式去找出這些分鏡的變換處(邊界),必需花上數倍於影片長的時間才能完成。傳統上分鏡偵測的方法就是以人工看完一整部影片,再把它分成很多的分鏡,接著做後續的索引、註解、儲存等工作,耗費大量的時間與人力。因此,提供影音工作人員一套自動化影音分鏡偵測工具是非常有用的。
要對一部數位化影片作分析,首先要將影片拆解成一個個的分鏡單位,也就是由同一部攝影機在連續時間中所拍攝出來的連續畫面(frames)。若能自動地找出這些影片中每個分鏡的起始位置時間,並以關鍵畫面(key frame)代表這個分鏡,使得影片記錄人員,只要看這些關鍵畫面的時間點及內容,即可很快地完成影片索引記錄的動作,如此將可大幅縮短工作時間與人力需求。
常見的兩種分鏡變化為:突然式分鏡變化(abrupt shot change)與漸進式分鏡變化(gradual transition)。漸進式分鏡變化包含溶解(dissolve)、淡入淡出(fade in/out)、wipe、mosaic、shift等。突然式分鏡變化發生在兩張畫面之間,可明顯看出影片中鏡頭的切換。漸進式分鏡變化是指前一段影片片段逐漸消失,同時後面一段影片也逐漸出現,此種分鏡變化會經歷好幾張畫面。
目前分鏡偵測有使用直方圖(histogram)、像素比對(pair-wise pixel comparison)、以區塊(block)為基礎之比對法等。直方圖被認為在時間與正確率上能取得較佳的平衡,被廣泛研究與發展。像素比對法之計算複雜度較高,對鏡頭與物體移動敏感。區塊比對法則是利用局部特徵比對,以減少物體移動所造成的影響。在已壓縮影音方面,則有利用MPEG特性進行分鏡偵測的作法,如使用MPEG中的巨方塊(macroblock),針對MPEG中的I(Intra)、B(Bi-directional)畫面(frame)進行突然式分鏡變化偵測。
影音metadata設計
Metadata可稱為詮釋資料或後設資料,metadata之設計將影響系統資料內容之完整性與未來跨系統資料交換之便利性,因此在建置系統之前必需要仔細考慮metadata的設計。
metadata之種類可分為一般性與學科導向性,一般性的metadata如通用之都伯林核心集(Dublin Core),其內容採用十五個固定的通用欄位來對應儲存各種資料。學科導向性metadata則是依不同領域之資料特性選擇適合該領域的metadata標準,如博物館採用的CDWA、檔案館採用的EAD等。採用一般性metadata的優點是系統設計簡單,容易與其他系統進行資料交換與對應,而缺點是無法精細的區分資料屬性,對資料內容的記載也不如學科導向性metadata內容的仔細與多樣性。
常見的metadata標準
影音系統之metadata標準,常見的有ECHO(European CHronicles On-line)、MPEG-7(Moving Picture Experts Group 7)、SMEF-DM(Standard Media Exchange Framework Data Model)等。歐盟(European Community)贊助支持的ECHO計畫設計的metadata標準是以國際圖書館學會聯盟(International Federation of Library Associations and Institutes,IFLA)的書目記錄功能需求模式(Functional Requirements for Bibliographic Records Model,FRBR Model)為基礎進行應用與修正,是數位影音領域中重要的metadata標準之一。
ECHO標準
ECHO標準將影音資料分成四種層次:Work(AV Document)、Expression (Version, Video, Audio, Transcript)、Manifestation(Media)和Item(Storage),其關係如圖二所示:
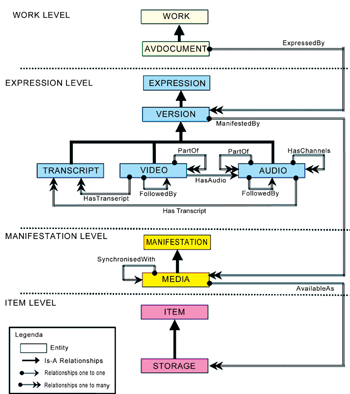
| 《圖二 ECHO的後設(詮釋)資料模型圖<資料來源︰http://pc-erato2.iei.pi.cnr.it/echo/public/deliv/D3-1-1%20ECHO%20Metadata%20Modelling.pdf>》 |
|
最上層的Work作品層次,是指AV Document影音文件 - 電影、錄影帶、錄音帶等。Expression內容版本層次,可再細分為Version層次 - 實體版本、數位版本等、Video影像層次、Audio聲音層次、Transcript文稿層次﹔Manifestation實體樣本層次(Media為媒體之基本資料)﹔Item單件作品層次(作品Storage儲存的相關資料)。
影音資料庫之發展
目前國外所發展的影音資料庫或影音數位典藏系統,較著名的如:美國卡內基美隆大學(Carnegie Mellon University,CMU)之數位電子影像圖書館(Informedia Digital Video Library)。美國University of North Carolina, Chapel Hill(UNC)所發展的Open Video Digital Library(OVDL)。
我國較著名之影音資料庫則有國立台北藝術大學與中央研究院合作之「台灣社會人文電子影音數位博物館計畫」。這些計畫都發展了影音數位典藏系統,並整合影音內容處理技術,如語音辨識與檢索、影片分鏡偵測、影片關鍵畫面擷取(image)等。目前影音內容處理技術尚未完全成熟,許多相關的研究也積極的進行中,此方面的研究仍然有很大的進步空間等待著人們去突破。
影音資料發行
由於網際網路快速成長,網路存取速度也越來越快,人們取得資料的途徑更加方便。然而影音資料的容量龐大,如何讓瀏覽者能使用較少的網路頻寬、較短的等待時間即可播放影音資料,是影音資料發行時重要的考量。目前串流(streaming)影音技術提供了較佳的解決方案,市場上較著名之產品如:Microsoft Windows Media Server之WMV與ASF之檔案格式,RealNetworks Helix Server之RM檔案格式、Apple QuickTime Streaming Server等。採用串流影音的好處包括:
- (1)即時播放:不需等待影音資料全部下載完成即可播放。
- (2)節省空間:不需將影音檔案下載至使用電腦之中,不佔電腦儲存空間。
- (3)資料不易被複製:由於資料不會被儲存於電腦之中,影音資料不易被瀏覽者取得、傳播。
- (4)即時廣播:在網路上之即時廣播(如現場直播節目),可由串流技術達成。
除了採用串流技術外,犧牲部份的影音品質以減低位元率(bit rate)的需求,將影音資料壓縮的更小,也是目前運用的方法之一。目前發展影音資料格式之廠商,多數實做了MPEG-4之壓縮標準來減少影音之容量,然而各家廠商各自實作MPEG-4之壓縮格式都有部份差異,使得檔案格式間並不能完全相容,這也是影音資料發行時前,需考慮的一個重要因素。
此外,使用者可藉由網路下載、瀏覽多媒體影音資料,也意味著使用者可以容易的複製與傳播散佈。對影音資料做智慧財產權的保護,目前較常被提及的包含數位浮水印技術(watermark)與數位內容版權管理技術(Digital Rights Management,DRM)。
版權保護與數位浮水印技術
數位浮水印技術的概念是把一些擁有者的資訊加到原始的影音資料中,當使用者下載或使用時,此資訊仍然會被保留,一旦發生版權爭議時,著作人或擁有者便能藉著浮水印來證明該資料確實為其所有,可以做為有力的舉證。
數位內容版權管理技術(DRM)是一種新興的資料保護技術,主要目的在限制未被授權者無法列印、儲存、重製、傳輸或修改其著作內容。在作法上可將著作內容以加入顯性(visible)或隱性(invisible)浮水印技術保護,並將資料鎖碼(加密編碼)保護。通常使用者必需安裝特定播放軟體或外掛(plug-in)軟體才能開啟經加密編碼的資料。目前DRM機制並沒有一定的標準,各家廠商也各自發展其架構,大體上的發展在存取控制(access control)、使用控制(usage control)、使用記錄(usage metering)、整合保護(integrity protection)等方面進行,相關技術仍在不斷的實驗與進行中。
結語
影音資料庫之設計、建置與應用,與傳統的文字式資料庫有很大的不同。巨量的資料容量、複雜的資料處理程序、多媒體資訊技術整合等,其所需的資訊技術與軟硬體資源,較文字式資料庫系統複雜許多,而相關的影音處理技術仍尚未完全發展成熟,使得發展影音資料庫需要投入大量的人力、時間、軟硬體資源。影音資料的大量使用已是未來的趨勢,影音資料庫之建置將快速成長。目前在此領域上仍有許多的研究空間與無限的商機,正等待研究者與資訊經營者去探索與經營,相信未來影音資料庫將會有劇烈的競爭與發展。(作者為中央研究院資訊科學所研究助理)