|
|
| 聲紋辨別 聽聲辨人 |
|
【作者: 王小川】 2004年03月25日 星期四
|
|
瀏覽人次:【34087】
以前我們做聲紋辨識,是將人的聲音訊號轉換成聲譜圖(spectrogram),從聲譜圖上觀察說話人發音的特徵,利用這些特徵進行說話人的辨識,就像是利用指紋圖形比對來認人一樣,因此我們將經由聲音來認人這樣的過程,就說成是聲紋辨識。其實現在的電腦已經有足夠的能力,利用影像處理方式進行指紋的自動辨識,同樣的,電腦也能夠以語音處理技術作說話人的辨識(speaker recognition)。
雖說每個人的說話聲音不太相同,對於熟識的朋友,通常聽到聲音就可以知道是誰,但是要做正確的辨識,卻不太容易,因為聲音的變數很多。例如一個人感冒了,這時候說話的聲音就跟平常說話的聲音不一樣。我們也常常看到一些模仿名人說話的表演,相當逼真,若不是看到表演者,還真的以為是該名人本尊在說話呢。所以相對於指紋辨識,聲紋辨識要困難多了,這也是為什麼聲紋辨識在使用上遠少於指紋辨識。目前市面上可以看到一些按指紋輸入作門禁管制的系統,但還極少看到只以聲音輸入作門禁管制的系統,在影片上看到的例子也常是配合指紋辨識或掌紋辨識一起使用,當作多一道驗證程序。
隨著電腦網路與無線通訊的廣泛使用,許多時候我們想透過手機去取得資訊,按鍵操作不是最有效率的做法,因為用語音輸入會更方便。如果要取用的資訊是機密性的個人資料,就必須經過授權才可以進入系統,因此使用者身份的確認便成為一個必要的步驟。可預期的,以聲音做身份驗證將會是未來極為需要的一項技術,但是要能克服辨識過程中可能對語音造成干擾的因素,例如說話人的變音、別人的模仿、噪音的干擾、通道造成的失真,以及編碼傳輸時對於原始聲音特徵的破壞。
從頻域中看語音特徵
人說話的聲音就叫做語音(speech),發不同的音,就有不一樣的聲學特徵(acoustic features),從時域的波形(waveform)中並不容易看出聲學特徵的差異,而是要將波形轉換到頻域,從頻譜(spectrum)上分辨。任何一個語音波形,都有其對應的頻譜,時域中的波形與頻域中的頻譜是語音訊號的一體兩面,而分辨語音的差異,必須在頻域中才能做到。
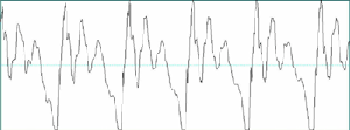
因此,我們在時軸上用特定長度的分析視窗(analysis window),取下一小段語音波形,視為一個音框(frame),將此音框內的語音波形轉換成一個頻譜。如果發音時聲帶振動,就可以在波形上看出訊號有週期性,可由頻譜上看到振動的基本頻率(fundamental frequency),以及它的許多諧振頻率(harmonic frequencies),基本頻率所呈現的特徵就是音高(pitch),圖一即展示一個發音時聲帶振動的音框。
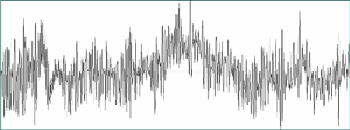
如果發音時聲帶不振動,波形上沒有呈現週期性,頻譜上就看不到振動的基本頻率與諧振頻率,而是在高頻有比較多的能量分佈,圖二就是展示一個發音時聲帶不振動的音框。
圖一 發音時聲帶振動的波形與頻譜
圖二 發音時聲帶不振動的波形與頻譜
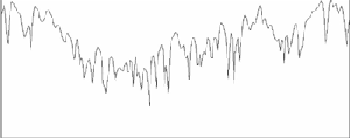
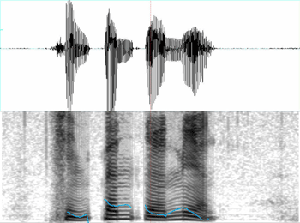
為了觀察頻譜的變化,我們以固定時間間隔移動分析視窗,將一段語音變成一串音框,每一音框頻譜的能量高低以顏色深淺表示,沿著時間軸,將一串音框的頻譜畫出來,就變成了聲譜圖。如果在一段時間中,發音時聲帶振動,聲譜圖上就可以看到諧振頻率造成的橫線條紋。如果發音時聲帶不振動,就只看到不規則的能量分佈。圖三展示一段語音的聲譜圖,可以看到某些時段聲帶振動,某些時段聲帶不振動。
一個經過訓練的人,可以從聲譜圖上觀察不同音段,猜出所發的是哪些語音。如果是不同的人說相同一句話,也可以從聲譜圖上看出差異,因為每個人會有他發音的特點。
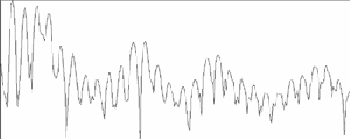
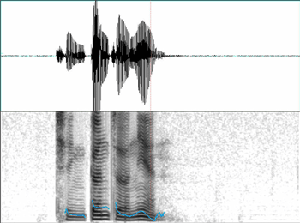
圖四展示兩個人各說了相同的一句話,仔細去看兩個聲譜圖,就會看出有許多地方是不相同的。最明顯的就是說話人A的聲譜圖上橫線條紋較寬,表示基本頻率比較大,或者是說音高比較高,應該是個女性的聲音。說話人B的聲譜圖上橫線條紋較窄,表示基本頻率比較小,或者是說音高比較低,是個男性的聲音。另外一個差異是說話人A的第三個音節前面,子音的發音明顯,而說話人B的第三個音節前面,子音的發音不明顯。
圖四 不同說話人的語音波形與聲譜圖
|
一般所說的聲紋比對,在過去就是由經過嚴格訓練的人,從聲譜圖中找出某個人的發音特點,比對這些特點,來判斷一段聲音是否是這個嫌疑人所發的語音。
語音特徵的選取
語音訊號中當然攜帶了可供辨識人的語音特徵,但是並非所有的特徵都適合作為說話人辨識之用,主要會有哪些差異? 我們又應該考慮哪些變項呢?
- (1)發音器官的差異 - 一如人的相貌不同,發音器官也不完全一樣,口腔形狀與聲帶的不同會使得說話聲音的特徵不一樣,也就是不同人的語音聲學特徵會有差異。
- (2)說話型態的差異 - 由於習慣的不同,說話型態會不一樣,例如有人說話就是比較快,或是某幾個音的發音比較特殊。
- (3)說話內容的差異 - 使用的語言、教育程度、以及社會階層的不同,都會使得說話的內容有所差異。
上述這些差異都可以作為說話人辨識之用,不過要注意的是有些說話特性可以模仿,例如說話型態與說話內容,是可以經由學習得到的,所以可以被模仿。而發音器官的差異是天生的,它使得聲學特徵上有所差異,或許一般人聽不出來,但是用電腦比對還是分得出來,這種聲學特徵就不能被模仿。所以要做說話人辨識時,去分辨由發音器官所決定的聲學特徵差異,就會比較可靠。
現在用電腦做說話人的辨識,是利用頻域的聲學特徵參數及其在時間上的變化,以比對演算的方式,達成辨識的結果。最常用的聲學特徵參數就是發音腔道模型(vocal tract model)參數,它能準確描述說話人的發音腔道特徵,用來做說話人辨識比較可靠。一個公認最適合描述發音腔道模型的參數,是「倒頻譜(cepstrum)」係數,這組係數常用於做語音辨識,也可以用於做說話人辨識。用於語音辨認時,會希望降低因人而異的差異性,盡可能做到與說話人不相關(speaker-independent),所以會選擇其中適合區別不同語音單位的部分。但是要做說話人辨識時,就應該找與說話人相關性大的部分,理想的參數是它在同一個人的語音中有較小的變異量(variance),而在不同說話人之間有較大的變異量。
除了口腔的聲學特徵參數之外,隨著時間改變的韻律特徵(prosodic features)也是可以用於說話人辨識的特徵參數,如音高軌跡、共振峰軌跡,以及音長等。
說話人辨識的類型
採用聲學特徵作說話人辨識可以有兩種作法,一是對聲學特徵參數作長時間的統計,一是針對幾個特定音作分析。對聲學特徵參數作長時間統計,是不管說話的內容,也就是它與文句不相關,我們稱之為與文句不相關的說話人辨識(text-independent speaker recognition)。如果我們限制說話的內容,例如只講數字,但是不在乎數字的組合,通常辨識效果會比較好,這就是限制內容的說話人辨識。若是針對幾個特定音作分析時,就必須讓說話人發出某些特定文句的語音,因此它是與文句相關的,我們稱之為與文句相關的說話人辨識(text-dependent speaker recognition)。
在應用上,說話人辨識可以分成兩類。一類是說話人識別(speaker identification),目的在從一群人當中找出誰是說話的人,常用於犯罪蒐證中找出嫌疑犯,或是在會議錄音中找出是誰在說話。另一類是說話人確認(speaker verification),目的在確認一個人的身份,這常用於門禁或資料擷取的管制。
說話人辨識的基本原理
以電腦做說話人辨識時,我們會對每一個音框計算出一組聲學特徵參數,例如發音腔道模型(vocal tract model)參數、倒頻譜係數、基本頻率、音量等,這組參數組成一個特徵向量,於是一段語音就有一串的特徵向量。針對某一個特定說話人,我們收集他的語音,得到許多的特徵向量,這些特徵向量隱含了這個說話人的個人特徵。若資料量夠大,我們可以從這些特徵向量的分佈,歸納出代表這個人的特徵,如某個特徵參數的平均值與變異量。對一個人的聲學特徵向量的分佈,通常我們是以一個高斯混合模型來表示,這個模型是由該說話人的大量語音資料計算出來的,就視為說話人模型。
說話人識別
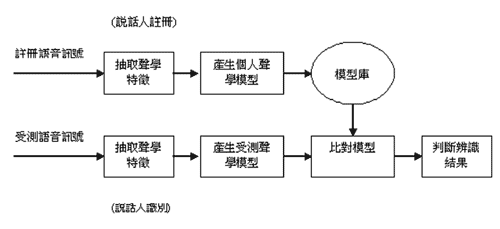
如果我們是做說話人識別(speaker identification),要從一群已經註冊的人當中找出誰是說話的人,那麼我們就先要有這一群人中每一個人的模型。當我們有一段受測語音,這段語音若是夠長,也可以算出這段語音的特徵向量分佈,構成一個受測模型。將這個受測模型跟這群人的模型比對,看是與哪一個人的模型最接近,就可以判斷這段語音是哪一個人的聲音。
這裡最重要的演算,就是計算兩個模型的差距,以差距最近的模型作為辨識的結果,目前已經有許多模型距離的定義與計算模型差距的方法。如果說話人不在這一群已經註冊的人當中,雖然也找出差距最近的模型,但不是正確的結果,所以我們要設定一個門檻,將不在這群人裡面的受測者排除。
說話人確認
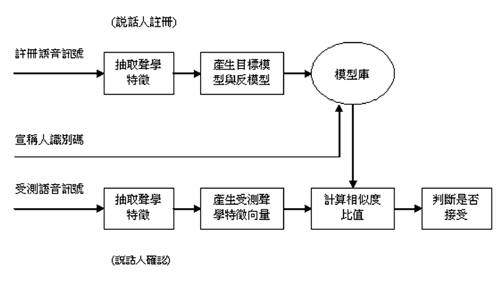
如果我們是做說話人確認(speaker verification),要確認一個人的身份,系統中就必須有這個宣稱人(claimed speaker)的模型,也就是這個人是事先註冊過的人,系統先收集了這個人的語音,建立了他的模型,叫做目標模型(target model)。針對這位宣稱人,還得建立一個反模型(anti-model),通常是找一些不屬於這個人的語音,來建立其反模型。
當一個宣稱人說了一段話之後,我們計算他這段受測語音的聲學特徵向量分佈,然後計算這些聲學特徵向量與目標模型的相似度(likelihood),以及這些聲學特徵向量與反模型的相似度。將受測語音對於目標模型的相似度,除以受測語音對於反模型的相似度,得出一個相似度比值(likelihood ratio)。
說話人確認的判斷準則(decision rule),就是將相似度比值拿來與一個事先設定的門檻值做比較,大於門檻值才認定這個受測語音是屬於宣稱人的,否則就認為說話的人是一個冒充者(impostor)。
上述的說話人辨識方法,基本上是對聲學特徵參數作長時間的統計,可以與文句不相關,但是辨識正確率通常較差。若是限制在某些語音範圍內,例如只講數目字,辨識結果會好一點。如果我們也做語音的辨識與分類,抽取特定的一些語音作比對,甚至於加上韻律參數,如音高軌跡等,作為比對的參數,通常能進一步提升辨識結果的準確率。
說話人辨識系統的設計
圖五與圖六分別是說話人識別系統與說話人確認系統的功能方塊圖。
設計一個說話人識別系統或說話人確認系統,都要建立說話人模型。因此要挑選說話人的語音資料,而且是跨越一段時間的語音資料,才能建立可靠的說話人模型。原因是說話人的聲音會隨時間改變,一個月前的聲音可能和現在的聲音不太一樣,因此說話人模型要能隨時間更新,最好的系統設計,是在使用者用過之後,就利用這時候得到的說話人語音來調整其說話人模型。
另一個設計上的考慮,是設計成有兩個門檻值。例如做說話人確認的判斷,計算出來的相似度比值若高於門檻值A就接受,低於門檻值B就拒絕,在A與B之間者,就要求再試,或是用另一組參數作判斷,這樣可以讓此系統更為可靠。如果考慮到運算時間,可以用不同參數分階段來判斷,如先用長時間平均值來做大分類,然後用特定語音的特徵作進一步判斷。
在建立說話人模型時,所收集的語音越多,得到的說話人模型越正確可靠。測試語音的長度與辨識的結果有關,通常是測試語音越長越好,這樣所計算出來的受測語音特徵參數分佈,或是受測模型,會比較準確。可是在實際應用情況下,如何收集語音是一件不容易的事,通常我們不希望讓說話人知道他正被錄音,以致於說話聲音不正常,最好是不經意的讓說話人發出我們想要的語音。因此,系統介面的設計需要講究,務必使說話人能自在地面對系統說話,錄音的過程儘量簡短。
說話人辨識技術的前景
從國外研究成果來看,說話人辨識技術已經是可以應用的技術,雖然現在的使用還不普遍,但是已經有一些公司開發出相關的產品或服務系統,正在推廣中。微軟(Microsoft)公司認為語言與語音處理是電腦發展的重要技術,將語音技術的使用視為未來電腦的一項必備功能,視窗系統中早就安排好語音的介面規格,而且投入大量資源作語言與語音技術的研發。
在網路與行動通訊日漸普遍的趨勢下,以聲音作為人機介面,用以擷取網路上的資訊,將會是一項重要的需求。而資料安全的考慮,必然會需要做人身的驗證,說話人辨識自然是一項必要的技術。也許不久的將來,說話人辨識會像語音辨識一樣,成為電腦作業系統中的一項附帶功能。在通訊網路上的應用中,人們在自由擷取資訊的同時,說話人辨識正默默的扮演資訊安全的把關工作。(作者為清華大學電機工程學系教授)
參考文獻
Joseph P. Campbell, Jr., "Speaker recognition: A tutorial," Proceedings of the IEEE, vol. 85, no. 9, pp. 1437-1462, Sept. 1997.
Joseph P. Campbell, Douglas A. Reynolds, Robert B. Dunn, "Fusing High- and Low-Level Features for Speaker Recognition," European Conference on Speech Communication and Technology, EuroSpeech 2003, pp. 12665-2668, 2003.
S. H. Chen and H. C. Wang, "Improvement of speaker recognition by combining residual and prosodic features with acoustic features," IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP2004, Montreal, Canada, 2004.
Larry P. Heck, "On the deployment of speaker recognition for commercial applications: Issues and Best practices," The Biometrics Consortium Conference, 2003. (http://www.nist.gov/speech/tests/spk)
Alvin Martin and Mark Przybocki, "NIST's assessment of text-independent speaker recognition performance," The Biometrics Consortium Conference, 2003. (http://www.nist.gov/speech/tests/spk)
P. Jonathon Phillips, Alvin Martin, C.L. Wilson, and Mark Przybocki, "An introduction to evaluating biometric systems," IEEE Computer, vol. 33, no. 2. , pp. 56-63, Feb. 2000.
Thomas F. Quatieri, Discrete-Time Speech Signal Processing, Prentice Hall PTR, 2002.
Frederick Weber; Linda Manganaro, Barbara Peskin, and Elizabeth Shriberg, "Using prosodic and lexical information for speaker identification," IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP2002, I-133-136, 2002.
K. H. Yuo and H. C. Wang, "Joint estimation of feature transformation parameters and Gaussian mixture model for speaker identification," Speech Communication, vol. 28, no. 3, pp. 227-241, 1999.
|