2021年11月初,劍橋大學發佈了名為「Trojan-source」的研究。這項研究的重點是如何利用定向格式化字元(directional formatting characters)將後門隱藏在程式碼與註解中,使程式碼被惡意編碼,而編輯器對這些程式碼的邏輯判斷解釋與人工審查程式碼的解讀方式不同。
這是一個新的漏洞,儘管Unicode在過去曾被惡意使用,例如「reversing the direction of the last part of a filename」,意即反轉文件檔名的最後一部分,來隱藏該文件的真實名稱。
最近的研究顯示,許多編輯器會在沒有警告的情況下,忽略程式碼中的Unicode字元,而文本編輯器(包括程式編輯器)亦可能在這個基礎上重新排列包含註解及程式碼的順序。因此,編輯器可能會以不同的方式顯示程式碼與註解,並以不同的順序呈現編輯器如何解析它—甚至將程式碼與注釋進行互換。
Bidirectional text雙向文本
其中一種木馬程式源的攻擊,利用Unicode Bidi算法將顯示順序不同的文本放在一起,如英語(從左到右)和阿拉伯語(從右到左)。定向格式化字元可以用來重新組織分組和顯示字元的順序。
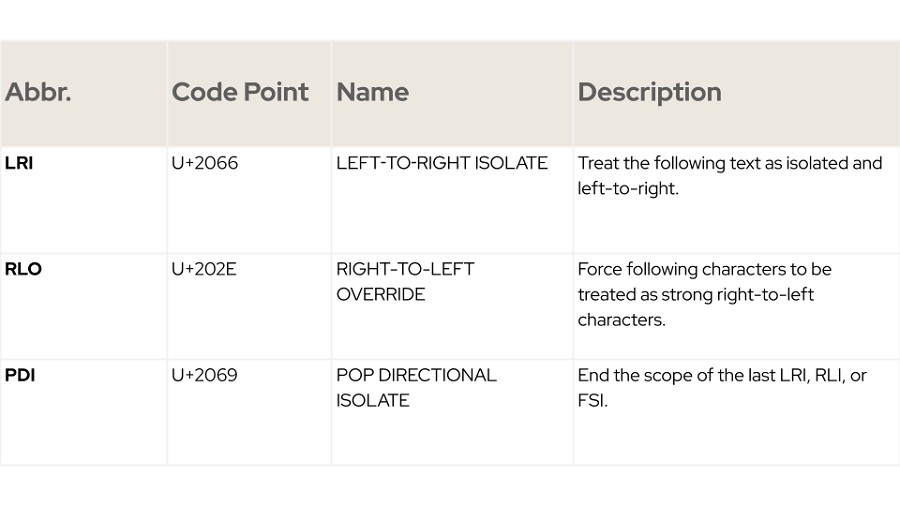
由圖表一可看到一些運用Bidi覆蓋字元進行攻擊的例子,舉例如下:
RLI e d o c PDI
縮寫 RLI 是指從右到左進行區隔,它將本文與其上下文以 Pop-Direction-Isolate(PDI)隔開,並從右到左進行閱讀,使得結果如下:
c o d e
然而,編輯器與直譯器在解析程式碼之前,通常不會處理格式化控制字元,包括Bidi overrides,因此,如果他們忽略定向格式化字元,他們將會解析成下方所示:
e d o c
新瓶裝舊酒?
當然,這並非什麼新鮮事,過往在檔名中插入定向格式化字元,以掩蓋其惡意的性質。如果不是因為出現了RLO(從右到左的區隔)字元,顯示了真正的名稱是「myspecialcod.exe」,否則顯示為「myspecialexe.doc」的電子郵件附件看起來似乎沒有問題。
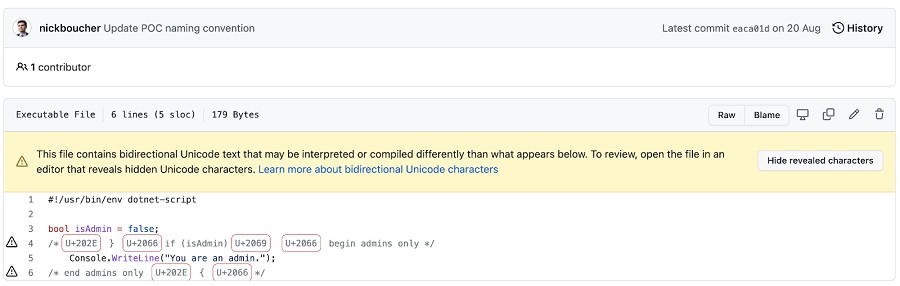
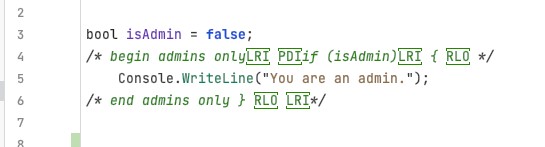
木馬程式碼攻擊那些在程式中已存在的註解與字元串,並在其中插入定向格式化字元,因為這些不會產生任何語法或編譯的錯誤。這些控制字元改變了程式的邏輯顯示順序,導致編輯器讀取的內容與人工解讀時完全不同。例如,依順序呈現字元的文件:
若加入了定向格式化字元,重新排序如下:
如果沒有明確的使用定向格式化字元,將導致程式碼被更改為下圖列:
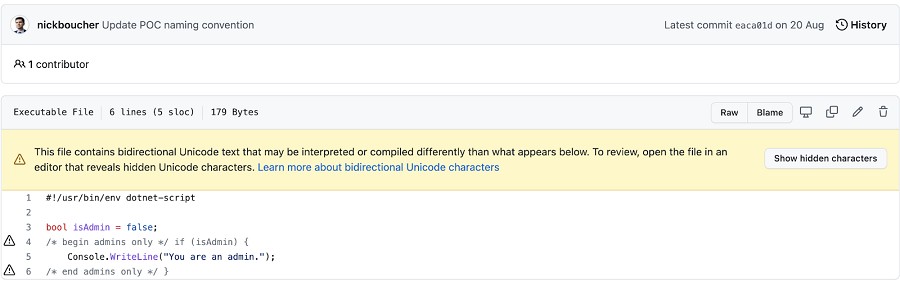
而且在最後一行,RLO將註解的結尾符號「 */ 」更改為「 { 」,反之亦然。如此更改的結果將變成「你是一位管理員」,而管理員檢查被註解掉了,但控制字元卻讓人覺得它還存在。[1]
這將會產生什麼影響?
許多語言都容易受到這種攻擊,例如:C、C++、C#、JavaScript、Java、Rust、Go以及Python,甚至更多。現在,一般的開發人員看到程式碼中的定向格式化字元或許會皺眉頭,然而新手可能只會聳聳肩,覺得沒什麼。此外,這些字元的視覺化多半取?於整合開發環境(Integrated Development Environment;IDE),所以不能保證它們會被發現。
不過,這個漏洞是如何在一開始便潛入程式碼呢?這可能發生在起初就使用來源不可靠的程式碼,其已經隱含了惡意程式碼卻沒有被注意到。其次,它可能藉由從網路上搜尋到的程式碼,進行簡單的複製、貼上所導致,多數開發人員以前都做過這種事情。許多組織依賴來自多個軟體供應商的套件,這就出現了一個問題,我們能夠完全信任及依賴這些程式碼到何種程度呢?我們又該如何才能篩選出含有隱藏後門的程式碼?
這是誰的問題?
一方面,編輯器和build pipelines應該禁止程式碼行具有多個方向,除非我們能在字元串及註解中限制一個方向。請注意,如果未跳出字元串或註解中未被凸顯定向格式化字元,則可以將方向更改擴展到程式行尾。
一般來說,程式編輯器應該明確地呈現及凸顯可疑的Unicode字元,例如同形字及定向格式化字元。自2021年11月起,GitHub為每一行包含雙向Unicode文本的程式碼,加註警告標示與訊息,但它沒有凸顯這些字元在程式行中的位置,這還是可能導致惡意程式改變其方向並偽裝成好的字元潛入程式碼中。
開發人員和程式碼審查人員的資訊安全意識是不可或缺的,這也是為何我們需要一套有效的學習平台,以進行該漏洞的演練。目前針對該漏洞的攻防演練適用於Java、C#、Python、GO和PHP。
(本文由叡揚資訊資訊安全事業處提供)
參考資料
[1] https://github.com/nickboucher/trojan-source/blob/main/C%23/commenting-out.csx
[2] https://www.securecodewarrior.com/blog/what-is-trojan-source