早在1984年时,由台北市电脑公会主导,并联合十多家电脑业者共同制定最初的Big5码。当初制定的目的是为了因应电脑相关业者对「中文数位化」日益迫切的需求,有了统一的中文编码标准,则中文数位资料才能在各平台间交换,各厂商也才能更进一步地开发相关的中文处理软体。虽然在此之前,曾有一批文字学家、图书馆学家、以及电脑学者等所组成的「国字整理小组」,进行国字整理与编码工作,并制定了目前通行于图书馆界的CCCII码,然而可惜的是此套编码不被当时的政府单位采纳,因而无法在电脑业界推广。是故他们才有另起炉灶,制定 Big5 码之举。而我们为了便于区分起见,便称这个最初的 Big5码版本为: BIG5_1984。
编辑Big5码的起因
根据Big5码的编码规则,其所能容纳的中文字与符号,最多也只有将近两万个,但中文字的个数实际上远远超过这个数目,要全部囊括进来是不可能的。因此在制定之初便保留了适当的弹性,也就是在此编码范围中只收录了一般常用字与次常用字,并保留了相当的码点空间让使用者造字,借此弥补缺字的问题。
然而,当初的美意却造成了往后的问题。由于保留了广大的造字空间于此编码中,再加上政府单位向来不硬性规定中文编码的态度,于是各厂商纷纷在这些造字区中加料,因此Big5码版本纷岐的问题就来了。
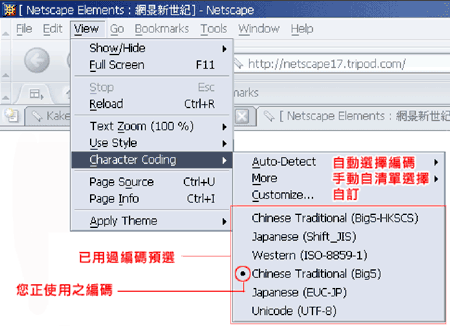
| 《图一 在Netscape下设定Big5中文繁体码》 | 资料来源:http://netscape17.tripod.com/first_coding.htm |
|
不同的版本间的困扰
在这诸多 Big5 的「变种」版本中,最重要的两个莫过于来自「倚天中文系统」的「倚天外字集」(一般人称为BIG5_Eten),以及来自微软视窗系统的CP950字集。它们之所以重要,主要是因为使用者众多,且流传极广。虽然在BIG5_1984已有部分汉字与符号定义的码点相同,但在BIG5_1984的造字区却有若干不同;不幸的是这些出现在造字区的新符号已有不少使用者在使用,因此当他们在换用不同的中文系统时,就不时地出现许多文字符号不能用的困扰了。
这样的问题到了自由软体世界开始迈向中文化时更加严重。因为绝大部分自由软体的开发,是集世界各地的程式开发者一起加入研究,大家所考虑的是「程式国际化与资料本土化」的程式设计架构,也就是一套程式设计出来后,能同时处理多国语文,而处理各国语文的部分与程式本身分开,自成一个资料库,如此写程式时就不需要各写一个版本给每一种语文了。
这是一个很好的架构,但当这些开发者开始实作我们的Big5码部分时却遇上了麻烦,因为他们找不到一个有公信力的标准可以参考,同时也不了解我们这边的情况。他们唯一能够找到的参考对象是一份来自Unicode Consortium的Big5与Unicode之间的转码表,但偏偏这份转码表的内容,不明究理地与 BIG5_1984、BIG5_Eten和CP950
间又有些许差异,其中又少了很多BIG5_Eten里广为使用的倚天外字。因此,这也就造成了在自由软体世界刚迈入中文化的头一两年里,最让大家感到困扰的地方了。
香港与台湾Big5码的差异
尔后,Big5 码所出现的变种,已不单只是将原来的BIG5_1984的造字区拿来放入若干符号而已,事实上它们更是大幅收录新字,填入造字区中空出来的码点上;所以严格来说,这些字已是「新」的字集了。在这之中,最重要的莫过于「BIG5 香港增补字符集」(Hong Kong Supplementary Character Set–BIG5-HKSCS)了。这是由香港政府所制定的字符集,而且也已成为香港地区通行的标准。而在我们这边,中推会也曾制定了一份「BIG5 补充码字集」(BIG-5 Extension Character Set–BIG-5E),当初制定的动机是提供一份现成的常用造字字集,让使用者可以免除大量造字的麻烦,同时也方便使用新字的文件在各平台间交换。然而,它并没有成功地推广开来。
正因为Big5有这么多彼此分岐的版本,不论在实作上或使用上都给大家带来许多不便,因此在我们的中文环境要迈向国际化之际,就必须开始严肃看待这个问题了。这些种种的问题,终于在2002年8月3日,在中研院资科所举办的Li18nux台湾特别会议中被提出来讨论。与会者均同意,由于Big5码的编码空间有限,再怎么样也难以收录所有中文字,且版本不一,所以缺字的问题很常见。最直接的解决之道就是换用大字马(如CNS11643或Unicode ),但那可能需要相当的社会成本,且也不是一天两天可以办得到的事。
不过目前有太多的电脑文件资料是使用Big5码,所以迈向大字码将会是一个渐进的工作,这也意味着我们可能还有好一段时间需要依赖Big5码。既然如此,研究人员就应该要给它确立好一个标准,并且在自由软体世界中有完善的实作,让大家不再发生困扰。
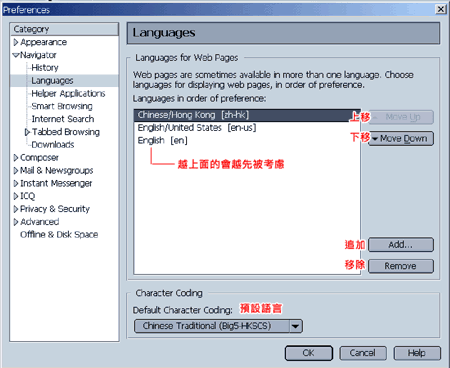
| 《图二 在Netscape的语言选项里设定Big5香港中文码》 | 资料来源:http://netscape17.tripod.com/first_coding.htm |
|
Li18nux组织
在上一届的Li18nux会议中,研究人员做出了一些相关的结论,即在Li18nux组织(现已改称为OpenI18N)中成立一个Li18nux-big的工作小组(同
样改称为Open I18N-big5),并进行初期的 Big5 码标准化的规画工作。
研究人员的工作重点
1. 重新检视Big5码,并确立与Unicode间的对应。当时的研究人员主要是拿最广为使用的BIG5_Eten与CP950作为范本,取其联集,同时参考BIG5_HKSCS与 Unicode的对应表,以尽量做到最大的相容性。这主要的工作是由唐宗汉先生(Autrijus Tang)与霍东灵先生(Anthony Fok)完成,而研究人员将其定名为TW-BIG5编码,以符合OpenI18N对字集编码名称的规范。
2. 推动Big5码国家标准化,并期望政府相关单位能够正视,以及参与维护Big5码的工作。这部分主要是由叶平教授(Ping Yeh)进行。在叶平教授积极奔走及行政院主计处与软体自由协会的协助之下,目前正一步步地往前推进。在历经几次会议之后,目前总算有了一份「BIG5-2003」的草案。
各式各样的Big5码
由于中文字的数量动辄上万,因此在电脑中不能像西方国家一样,单单只用一个位元组(byte)来容纳。所以在Big5 的编码中,必须以两个位元组来代表一个中文字或符号,传统上在萤幕显示时其宽度是两个英文字(ASCII 码)的宽度,故在许多中文系统中,我们习惯将这些中文符号称为「全形字」,而相对的ASCII字则称为「半形字」。尽管我们用两个位元组来组成全形字,但为了能与ASCII码相容,研究人员不能将这两个位元组的所有可能值都纳入编码范围。
TW-BIG5码点与Unicode之间的对应关系
为了达到最大的相容性,所以研究人员在制定TW-BIG5草稿时,便取各种Big5码版本的联集。不过光是这样还不够,还有一项重要的工作是确立各TW-BIG5码点与Unicode之间的对应关系。因为在自由软体世界(在此指的是GNU/Linux系统)的「程式国际化与资料本土化」的程式架构下,各国语文资料在系统底层都必须以Unicode或UCS4的编码来表示,如此才能达到编码转换与资料交换的目的。因此研究人员不仅要将TW-BIG5中有定义的码点与Unicode对应起来,还要考虑到空的码点,也就是造字区的部分与Unicode的对应,这样有使用者在过去的造字,才能在TW-BIG5下使用。
由于这些造字区的码点没有真正定义出中文字或符号,因此在与Unicode对应时,必须对应到其PUA的区域;而这个区域是私人使用的码点区,也没有明确的文字或符号定义,同时在Unicode的规范中,使用PUA区的码点资料是不能用来交换。道理很简单,正如同某甲所造的新字不见得能在某乙的电脑中同一个码点位置上找到。
Big5码国家标准化工作推手之一的国内自由软体社群,在理论上提出BIG5-2003草案时,就应当考虑到官方研究人员的意见,也就是 TW-BIG5 的内容。然而,由于之前联系上的失误,使得官方研究人员的TW-BIG5没有即时被纳入考虑,因此事后的比对工作就相形显得重要了。经过比对之后,研究人员发现BIG5-2003与TW-BIG5之间还是有些差异,这些差异总结如下:
- 1. BIG5-2003没有考虑到使用者造字区与Unicode PUA之间的对应。
- 2. BIG5-2003在「罕用符号区」中,将BIG5_Eten与TW-BIG5内含的俄文字与输入法特殊符号都删除了,仅保留了数字符号以及日文字。
这么做的理由有可能是因为BIG5-2003的定位是要做为CNS11643的附录,这也意味着每个BIG5-2003上有定义的码点都要与CNS11643有一对一对应才行。然而这些罕用符号区中的俄文字与输入法特殊符号在 CNS11643 都找不到对应,因此自然不能包含进来。另外一点就是这些没有包含进来的符号,几乎没有人在使用。
研究人员未来的相关工作
严格来说,解决BIG5-2003与TW-BIG5之间的差异并将BIG5-2003推向国家标准化,仍只是第一步而已。如果读者再仔细看看Big5码的内容,就会发现其中仍有些许不完善的地方是仍需进一步的工作。
与Unicode之间的多对一的对应问题
这里指的是多个Big5码点对应到同一个Unicode的码点,会发生这样的状况,主要是因为Big5中有些码点所代表符号的形状非常相似,而在Unicode中,这些看起来形似的符号,也只能够提供单一码点做为对应;其实这是Big5先天上的问题,而造成某些Big5多对一的码点在转成Unicode之后再转回Big5时就不见了。因为转回来时,是转到另一个也同样对应到该Unicode码点Big5码点去了;这就等于某些资讯可能在这样的转换中流失,故原则上研究人员希望这种「多对一」的发生情况可以越少越好。
异体字的问题
研究人员曾发现,某些中文字在BIG5与CNS11643中,与教育部所颁布的标准楷书形状不一样。理论上,应以教育部所颁布的中文字的形状为标准,然而由于CNS11643已是国家标准,同时其标准也早已提报到许多国际组织中,要修改并不容易。不过异体字的问题直接关系到我们对下一代的教育,因此笔者认为我们有必要正视此一问题,并设法化解决二者间的岐异。
总结
目前的Big5还有很大的造字空间,必要的话可以继续收录新字。但有没有必要这么做呢?从实用的观点出发,这么做是必要的,因为随着时代的演进,原本的罕用字可能渐渐变成常用字,使用者到最后免不了要面临缺字的问题。然而,继续收录新字让Big5成长,也意味着原本的造字区将逐步缩水,原来惯用造字区的使用者将无法再使用它。另外,若要最直接地解决缺字问题,便是换用大字码。当中文字正一步步朝向大字码迈进之际,是否还值得持续扩充Big5?这一点值得大家深思讨论。
"
(本文与自由软体铸造场计画网站同步刊登)
|
|
 |
本文对CNS11643国家中文标准交换码、BIG5E码、EUC码、CCCII码、ISO10646及UNICODE汉字集码等中文码有详细的介绍。此外,还有中文码之应用及发展的深入剖析,相关介绍请见「全字库中文码介绍」一文。 |
|
鉴于市民及政府部门不时需要把新字符纳入<香港增补字符集>内,政府在与中文界面咨询委员会(中咨会)共同努力下,于二零零零年四月公布了<香港增补字符集>字符增收程序和原则。本篇文章除了对<香港增补字符集>有详细的介绍外,另有更新的字库供一般民众下载,你可在「<香港增补字符集>增收新字符的工作」一文中得到进一步的介绍。 |
|
我国最早之中文字码为民国六十九年提出之「中文资讯交换码」(Chinese
Character Code for Information Interchange,CCCII)。订定此码的原动力是美国急需使用电脑处理东亚语文资料,因此派遣负责人赴东亚考察。当时只有日本订定资讯码标准JIS
C 6226
,美方初步决定采用此标准。我华裔美国亚东图书馆代表与我国代表极力反对,说明日本汉字无法代表中国文字的理由,并允诺四个月之后提出我方之标准。本文对国内中文字码发展始有详细的记载,在「国内中文字码之发展」一文为你做了相关的评析。 |
 |
|
|


