数据挖掘是新玩意?
最近在许多地方都可以看到数据挖掘(Data Mining)的踪迹,许多人不免又要皱起眉头,这又是什么新玩意?其实数据挖掘并不是什么新玩意,它早已行之有年,直到国内对于信息的重视与因特网不可思议的快速成长,才让它活跃在国内的计算机信息界。那数据挖掘是什么呢?说穿了就像它的名称一样,就是在一堆数据中做挖掘的动作,把储存在计算机中的数据当作一个宝山,利用数据挖掘的技术在这宝山中挖出我们想要的宝藏。接下来我们来看看数据挖掘的庐山真面目。
数据挖掘的由来
我们先来看一个有趣的例子,了解一下数据挖掘可以帮我们挖掘出什么样的信息。在美国有一家超商为了了解顾客的消费行为,所以利用数据挖掘的技术找出了一个非常ㄅㄧㄤˋ的结果,这结果呈现这家超商的顾客买了啤酒都会买尿布。这家超商也利用这个挖掘出来的宝藏,将商店内的啤酒和尿布陈设在一起,有时还用来促销。这样的动作,使得这家超商赚进了大把银子。
相信各位看倌现在应该对数据挖掘有一点概念了。那各位看倌知不知道为什么会出现这种现象呢?原因就是美国的男人都很喜欢喝啤酒,但是苦命的是他们的阿娜答都会叫他们买啤酒的时候顺便买尿布,所以就造就了这个令人百思不得其解的现象啰!看来美国的男人不会比我们幸福到哪里去呢!
由上述的例子,可以知道数据挖掘的主要目的,是要由庞大的数据中,找出有意义或对我们有用的信息;透过这些信息,将有助于信息管理、查询处理、以及决策的制定等。例如在超市的客户交易纪录中,可以分析出客户的购买行为以增加营业利润;对信用卡而言,可依据客户的刷卡纪录以及缴款纪录来分析出信用好坏的客户,以决定其信用额度;在医学的应用,可以发现潜在疾病的病征,有效的加予预防和治疗。
数据挖掘的流程
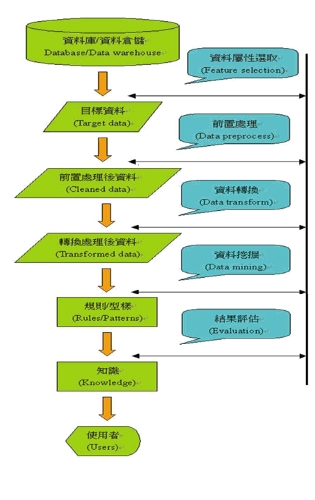
现在我们来看看数据挖掘的前后整个流程(图一)。数据挖掘的过程包含了数据的挑选、数据的前置处理、转换、数据挖掘、以及规则的评估和解释。先将各种不同来源的数据,经过整理转换后建构成数据仓储(Data Warehouse)。然而在数据仓储中的数据属性并不是全部都可以用来作数据挖掘,必须经过挑选的程序选出适宜其应用领域的数据属性。因为数据挖掘中有许多不同的技术(其后再述),这些挑选出来的数据,为了因应这些技术,所以要将这些数据加以转换才能被使用。
经过数据挖掘出来的结果,称之为规则(Rule)或者是型样(Pattern)。对用户而言,这些规则或型样并不是每一个都具有意义,所以必须经过领域内专家的评估,才能找出真正有用的信息。如果挖掘出来的结果,经过评估后不符合需求,可以回到前述的程序,进行数据挖掘技术的参数调整或是选择其他技术,更甚的是重新挑选数据属性或选择数据源。经由这种回授过程,反复进行直到满意的结果为止。
这整个流程以数据挖掘为核心,也是最重要的关键。如前所述,数据挖掘并不是一项新的技术,事实上,它也使用了许多统计上的技术加以变化,例如群组化以及分类(这些技术我稍后再谈)。现今的数据挖掘技术更加入了人工智能的技术(例如模糊理论、类神经网络、基因算法等),让数据挖掘的效果变得更为有效。此外,与数据挖掘有关的领域包括机器学习、专家系统及型样识别等。
数据挖掘发展至今,已经发展出许多的技术,这些技术分别应用在各种不同的环境上。在这些应用的环境中,如何选择适合的数据挖掘技术,将会影响处理过程的效能以及挖掘出来的信息之可用性。目前数据挖掘的主要技术有关联法则(Association rule)、分类(Classification)、组群化(Clustering)、序列型样(Sequential pattern)以及路径行走型样(Path traversal pattern),这些技术都有其特性及不同的结果分析。以下我将分别介绍这几种数据挖掘的技术。
关联法则
关联法则主要目的是在数据量庞大的环境中分析各数据项间的关联性,这个关联性的形式表示为X→Y(X、Y分别为数据库中不同的数据项)。关联法则最初的目的是为了要经由分析客户的购物交易纪录,进而找出各商品之间的关联性,利用这些关联性来做商店的商品陈设或是进货及促销的参考,明显地,此种关联性有助于商店的竞争力以增进利益。
可是如何评估关联法则的关联性是否可信?答案在于支持度(Support)以及可靠度(Confidence)这两个参数。这两个参数是由用户自定义,只要藉由关联法则找出关联性的支持度与可靠度,若值大于用户的自定义值,则可判定这个关联性是有意义的。
分类
分类在统计的领域中是一个行之有年的技术,相信许多读者对其非常熟悉了。分类是一种监督式学习(Supervised learning)的技术,其目的在于利用数据中的属性来建构一分类器(Classifier),在利用此分类器作为预测分析之用。在分类器中的数据分为两种:训练数据(Training data)与测试数据(Testing data)。
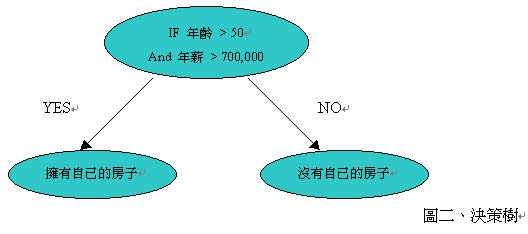
训练数据主要是用来建构分类器,而测试数据与训练数据具有相同的数据属性,用来验证分类器的正确率是否达到用户所能接受的值。目前最为普遍的分类方法是判定树(Decision tree),其分析出来的结果可以容易转换成IF-THEN的规则,以利决策者观看及达到支持决策的目的。(图二)显示出一个简单的判定树的例子。
组群化
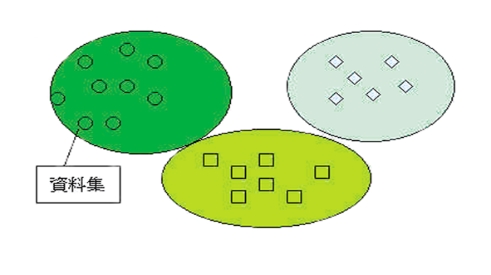
组群化的技术与分类有些不同,组群化是属于非监督式学习(Unsupervised learning)的技术。组群化是将数据有效地分成一个个的组群(Cluster),组群内的数据都具有高度的相似性,不同的组群,其特征不尽相同,其概念如(图三)所示。组群化技术可说是最广泛被应用的技术,例如在图像处理上,利用组群化来做影像分割或是影像辨识。群组化的结果,主要是提供数据的分布情形与趋势,以帮助用户进行数据的分析与决策的制定。
序列型样
序列型样的技术与以上所提的技术有很大的不同,因为序列型样加入了时间因素的考虑。基本上序列形样与关联法则目的是相同的,都是要找出关联性,可是序列型样要找的是事件在时间上的顺序关联性。举个例来说,某家超商的顾客买了可乐之后就会买面包,这之间的关系是顺序性的。
序列型样可分为顺序性型样以及周期性型样,分别针对时间的顺序性以及时间区段的周期性做分析。顺序性型样只考虑事件的时间顺序先后,周期性型样加上了时间周期的变化,例如小明每天早上八点到九点都会喝咖啡和看报纸,以上例可以看出周期是每天的早上八点到九点,而发生的事件是喝咖啡和看报纸。
这两种方法找出的型样虽然不同,但是针对时间的多变化性却也能提供有效之决策支持。这种技术最常见的应用是在股市上,主要用来做预测和分析,不过根据笔者自己的经验,在台湾股市这种诡谲多变情势,这还真是仅供参考呢!
路径行走型样
随着因特网(Internet)的快速发展,数据挖掘当然也不能错过这个可以大放异彩的机会,于是路径行走型样也应用而生。其实在因特网上的数据挖掘称之为网页挖掘(Web mining),其分为两个方向:网页内容挖掘(Web content mining)及网页使用挖掘(Web usage mining)。
网页内容挖掘主要针对网页内容做分析,其内容包含了文字和超链接。网页使用挖掘着重于找寻用户浏览网页的习惯,这也就是路径行走型样,目前有许多大型网站都有使用这种技术,例如亚马逊(Amazon.com)、雅虎(Yahoo.com)等。目前这方面的研究算是数据挖掘技术里最热门的,而随着电子商务的持续发展,数据挖掘的重要性与应用范畴也会越来越重要而且越来越广。
小结
数据挖掘发展至今,在各领域应用上已有一些相当不错的成果。在商业市场上,可经由其预测未来的市场趋势以增进其利益,以及对客户的消费行为分析取得竞争优势。在网络的应用上,经由预测用户可能的网页浏览路线,适当的放置广告以达到广告效益、轮播广告的顺序、以及个人化的网站等。数据现在已是一个十分重要的角色,尤其在竞争激烈的信息市场上,数据挖掘技术更是不容忽视,善其技术将有助于取得竞争上的优势。下一期我们再深入探讨数据挖掘在网络上的应用。
(作者为网眼科技技术顾问,网眼科技为网络市场信息分析系统专业公司)