意法半导体(ST)持续积极叁与高速发展的嵌入式人工智慧领域。为了在具成本效益和低功耗的微控制器上加快运用机器学习和深度神经网路,ST开发全方位的边缘人工智慧生态系统,嵌入式开发人员可以在各种STM32微控制器产品组合中,轻松新增利用人工智慧的新功能和强大的解决方案。
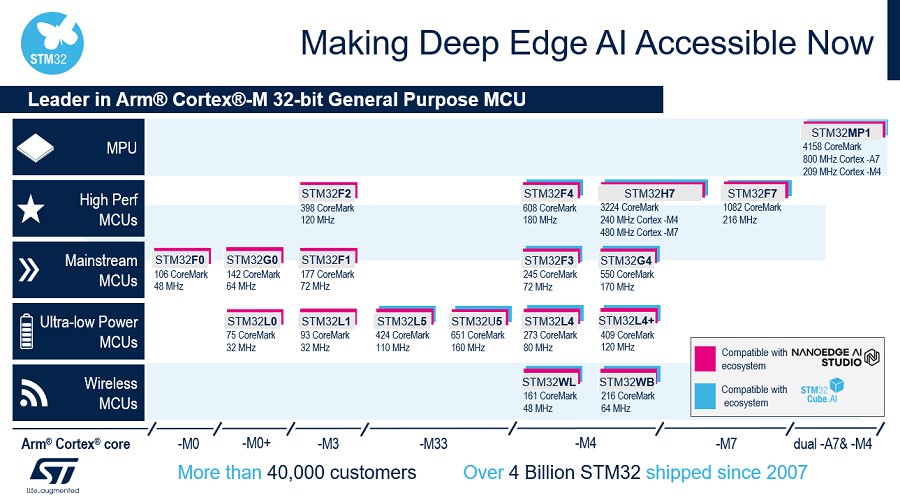
图一显示ST AI解决方案之於整个STM32产品组合,而且已经拥有预先训练神经网路的嵌入式开发人员,可以在任何采用Cortex M4、M33和M7的STM32上移植、最隹化和验证这整个产品组合。STM32Cube.AI是 STM32CubeMX的AI扩充套件,让客户能以更高效率开发其AI产品。
利用深度学习的强大功能可以增强讯号处理效能,并提升STM32 应用的工作效率。
本文概述FP-AI-VISION1,此为用於电脑视觉开发的架构,提供工程师在STM32H7上执行视觉应用的程式码范例。
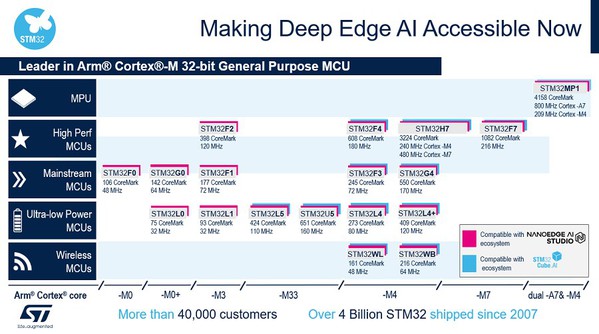
| 图一 : 执行机器学习和深度学习演算法的STM32产品组合 |
|
从FP-AI-VISION1程式码范例开始,简易达成在边缘执行的各种电脑视觉使用案例,例如
· 生产线上的物体分类,藉以根据物体的类型调整输送带速度;
· 侦测产品的一般瑕疵;
· 区分不同类型的物件,例如:螺丝、义大利面、乐高零件,并分拣到不同的容器中;
· 对设备或机器人操作的材料类型进行分类,并随之调整行为;
· 对食品类型进行分类以调整??调/烧烤/冲泡或重新订购货架上的新产品。
FP-AI-VISION1
概述
FP-AI-VISION1是STM32Cube功能套件(FP),提供采用卷积神经网路(CNN)的电脑视觉应用范例。其由STM32Cube.AI产生的软体元件和AI电脑视觉应用专用的应用软体元件组成。
功能套件中提供的应用范例,包含:
· 食品识别:辨识18类常见食品;
· 人体感测:识别影像中是否有人;
· 人数统计:依照物体侦测模型计算情境中的人数。
主要特色
FP-AI-VISION1在与STM32F4DIS-CAM摄影机子板,或是B-CAMS-OMV摄影机模组搭配连接的STM32H747I-DISCO板上运作,包括用於摄影机撷取、画格影像预处理、推断执行的完整应用韧体和输出後处理。这也提供浮点和 8 位元量化 C 模型的整合范例,并支援多种资料记忆体设定,满足各种应用需求。
此功能套件最重要的其中一项关键优势是提供范例,描述如何将不同类型的资料有效地放置在晶片上的记忆体和外部记忆体中。使用者因此能够轻松了解最符合需求的记忆体分配,并有助建立适用於STM32系列的自订神经网路模型,特别是在STM32H747-Disco板上。
FP-AI-VISION1 包括三个采用 CNN 的影像分类应用范例:
· 一种对彩色(RGB 24位元)画格影像执行的食品识别应用;
· 一种对彩色(RGB 24位元)画格影像执行的人体感测应用;
· 一种对灰阶(8位元)画格影像执行的人体感测应用。
本文将重点介绍食品识别和人体感测之两种范例。
首先讨论食品识别应用。食品识别CNN是MobileNet模型的衍生模型。MobileNet是适用於行动和嵌入式视觉应用的高效率模型架构,此模型架构由Google[1]提出。
MobileNet模型架构包括两个简单的全域超叁数,可以高效在延迟和准确度之间进行权衡。原则上,这些超叁数可让模型建构者根据问题的限制条件,决定应用大小适合的模型。考量STM32H747的目标限制条件,此软体套件中使用的食品识别模型是透过调整这些超叁数建构而成,以便在准确度、运算成本和记忆体占用之间进行最隹权衡。
图三为食品识别模型的简单执行流程。这在STM32H747上执行,大约需要150毫秒才能完成推断。
其次,将说明人体感测应用。FP-AI-VISION1 提供两个人体感测的范例应用:
· 一种采用低复杂度CNN 模型(所谓的Google_Model),用於处理解析度为96×96像素的灰阶影像(每像素 8 位元)。这个模型可从:storage.googleapis.com下载。
· 一种采用更高复杂度的CNN模型(所谓的 MobileNetv2_Model),用於处理解析度为 128×128像素的彩色影像(每像素 24 位元)。
在此观察前一个模型,人体感测应用程式可识别影像中是否有人。在与STM32F4DIS-CAM连接的STM32L4R上执行这个应用程式时,大约需要270毫秒来推断。而快闪记忆体和 RAM 的大小足以在微控制器上执行神经网路 (NN),如图四所示。
人体感测可利用从低功率唤醒,使用案例包括开灯、开门或其他任何自订方法。一般用途通常采用被动红外线感测器,藉以在侦测到移动的时间和地点触发事件。不过,这种PIR 系统的问题是可能发生误报。如果有猫经过或在风中飞舞的树叶,可能会触发这个系统。人体感测应用只会侦测人类,并且有助於轻松开发更智慧的侦测系统。
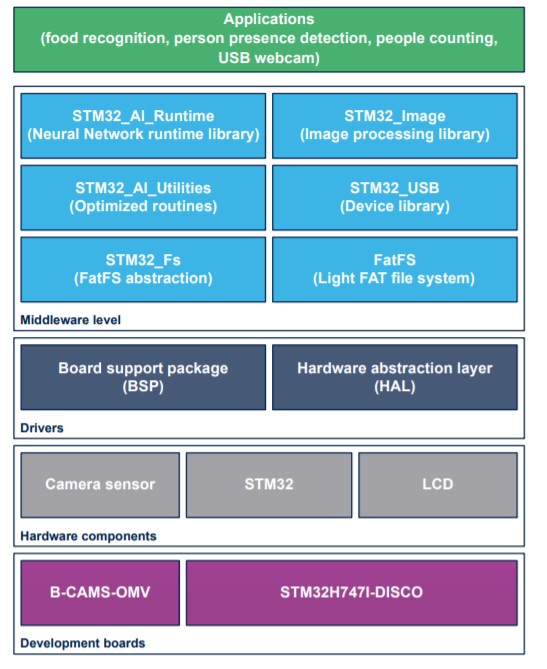
系统架构
FP-AI-VISION1的顶层架构,如图五所示。
应用建构流程
从浮点 CNN 模型(使用 Keras 等架构设计和训练)开始,使用者产生最隹化的C程式码(使用STM32Cube.AI 工具)并整合到电脑视觉架构中(FP-AI-VISION1 提供),以便在 STM32H7上建构电脑视觉应用。
产生C程式码时,使用者可从下列两个选项中择一:
· 直接从CNN模型以浮点方式产生浮点C程式码;
· 或者对浮点CNN模型进行量化,得到8位元模型,随後产生对应之量化後的C程式码;
对於大多数 CNN 模型,第二个选项可以减少记忆体占用(快闪记忆体和RAM)以及推断时间。对最终输出准确度的影响则取决於CNN模型以及量化过程(主要是测试资料集和量化演算法)。
应用执行流程
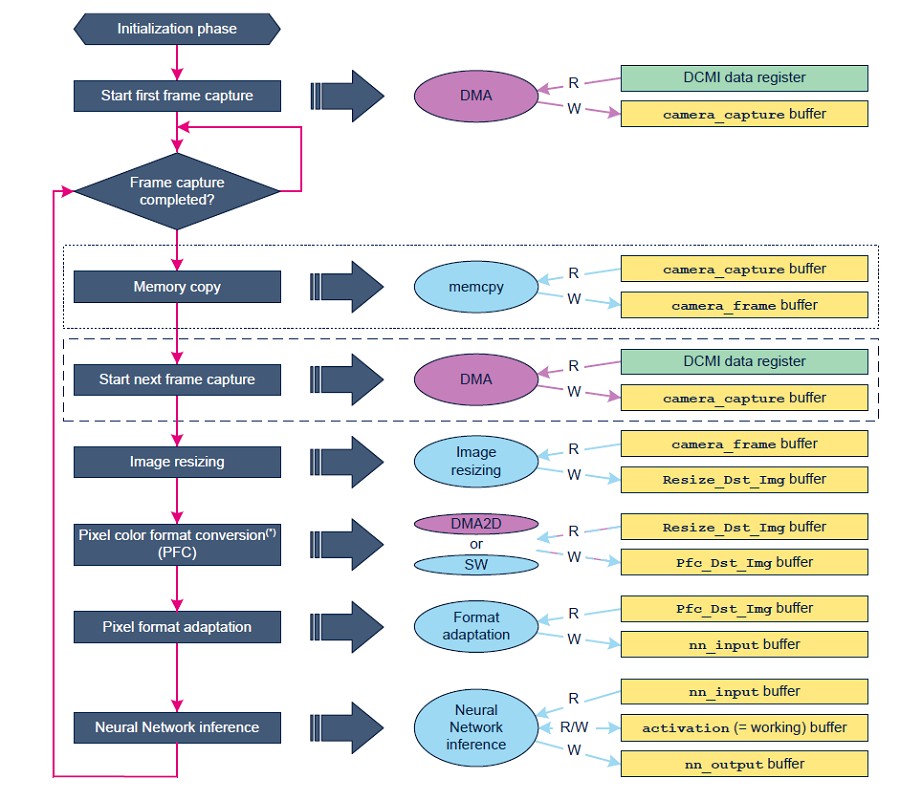
对於电脑视觉应用,整合需要一些资料缓冲区,如图七所示。
应用过程依序执行下列操作:
1. 在 camera_capture buffer中撷取摄影机画格(透过DCMI资料暂存器中的DMA引擎)。
2. 此时,根据选择的记忆体分配配置,将camera_capture buffer内容复制到 camera_frame buffer,并启动後续画格的撷取。
3. camera_frame buffer中包含的影像将重新缩放到Resize_Dst_Img buffer中,藉以配合预期的CNN输入张量尺寸。例如,食品识别NN模型需要输入张量,例如 Height × Width = 224 × 224像素。
4. 执行Resize_Dst_Img buffer到Pfc_Dst_Img buffer的像素色彩格式转换。
5. 将Pfc_Dst_Img buffer内容中包含的各像素格式调整到nn_input缓冲区中。
6. 执行NN模型的推断:这个nn_input buffer以及activation buffer提供给NN作为输入。分类结果将储存在 nn_output buffer中。
7. 对nn_output buffer内容进行後处理,并显示结果於萤幕上。
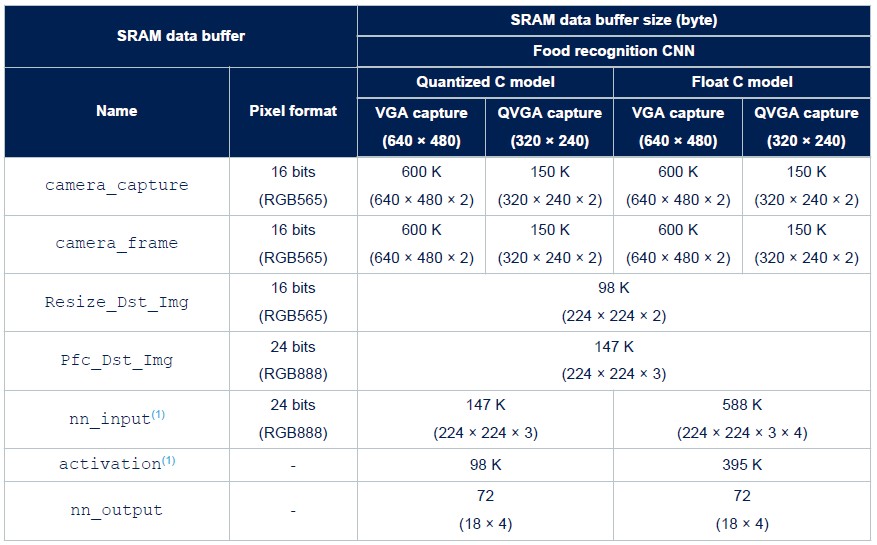
图表八详细说明了食品识别应用在整合量化C模型或浮点C模型时所需的RAM。
FP-AI-VISION1可从连结下载:
www.st.com/en/embedded-software/fp-ai-vision1.html
叁考资料
[1] 食品识别 CNN 是 MobileNet 模型的衍生模型。
MobileNet:用於行动视觉应用的高效率卷积神经网路:https://arxiv.org/pdf/1704.04861.pdf
[2]UM2611:FP-AI-VISION1手册:
https://www.st.com/resource/en/user_manual/dm00630755-artificial-intelligence-ai-and-computer-vision-function-pack-for-stm32h7-microcontrollers-stmicroelectronics.pdf
[3]UM2526:STM32Cube.AI手册:
https://www.st.com/resource/en/user_manual/dm00570145-getting-started-with-xcubeai-expansion-package-for-artificial-intelligence-ai-stmicroelectronics.pdf
[4]FP-AI-VISION1 视讯应用影片:
https://www.youtube.com/watch?v=VkFTrc5KSgg&t=130s
https://www.youtube.com/watch?v=8AX9uC2Oi1g&t=178s